سحب البيانات من مواقع الانترنت web scraping
تفاصيل العمل
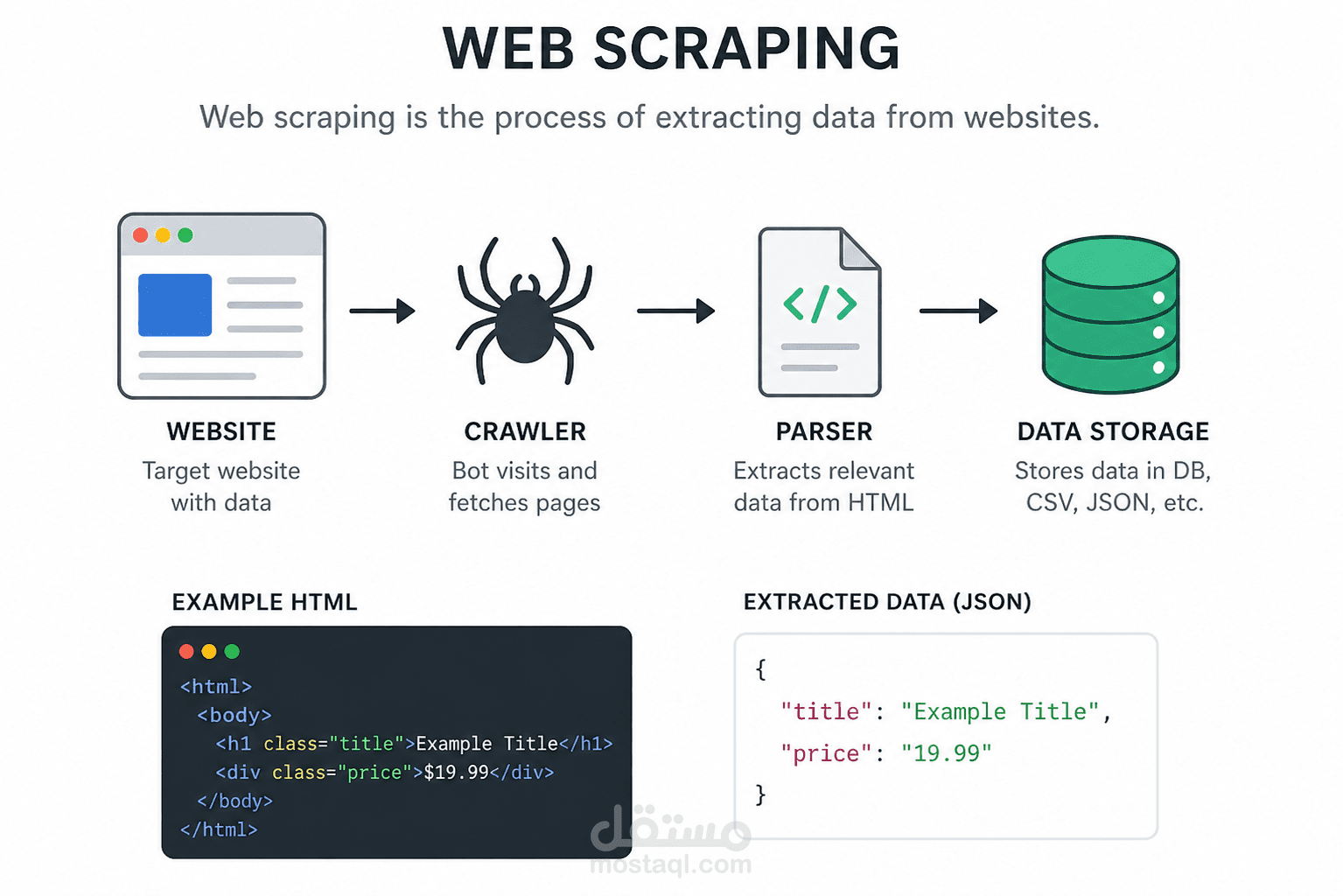


سحب البيانات من مواقع الإنترنت (Web Scraping) بهدف جمع معلومات محددة وتحويلها إلى بيانات منظمة قابلة للاستخدام في التحليل أو التخزين. يشمل العمل استخراج البيانات من صفحات الويب المختلفة باستخدام أدوات ولغات برمجية مثل Python ومكتبات مثل Requests وBeautifulSoup أو Selenium في حالة المواقع الديناميكية.
يتضمن ذلك تحليل هيكل الموقع (HTML) لتحديد العناصر المطلوبة، ثم كتابة سكريبتات لاستخراج البيانات مثل النصوص، الجداول، الروابط أو الصور بشكل دقيق. كما يشمل تنظيف البيانات المستخرجة وتنظيمها في ملفات مثل CSV أو Excel أو تخزينها في قواعد بيانات.
يركز العمل أيضًا على التعامل مع التحديات مثل Pagination، وعمليات تسجيل الدخول، والحماية من الحظر (مثل التعامل مع الـ Headers و User-Agent)، لضمان سحب البيانات بكفاءة واستمرارية.
الهدف هو توفير بيانات دقيقة ومحدثة بشكل آلي لتسهيل استخدامها في التحليل، بناء النماذج، أو دعم اتخاذ القرار.