Adverse Drug Reaction (ADR) Reporting — Exploratory Data Analysis & Predictive Modeling
تفاصيل العمل
It includes data cleaning, handling missing values, and outlier treatment to ensure data quality.
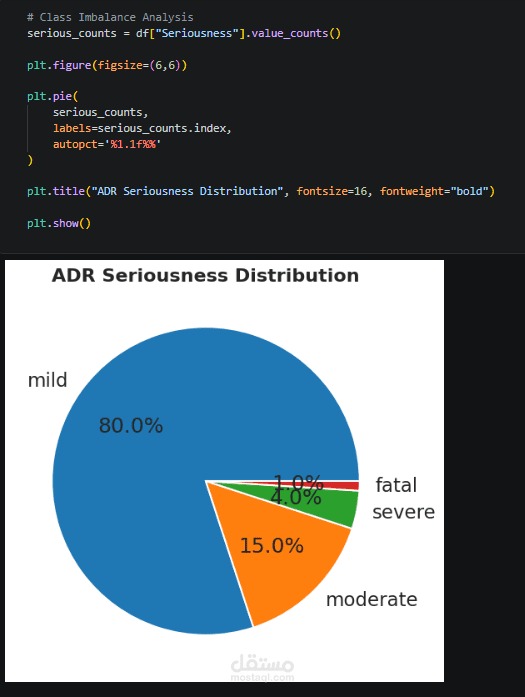
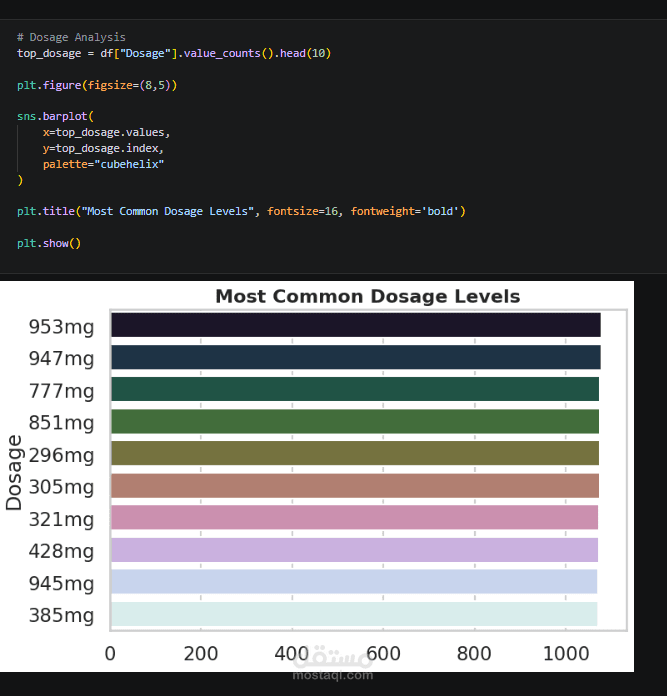
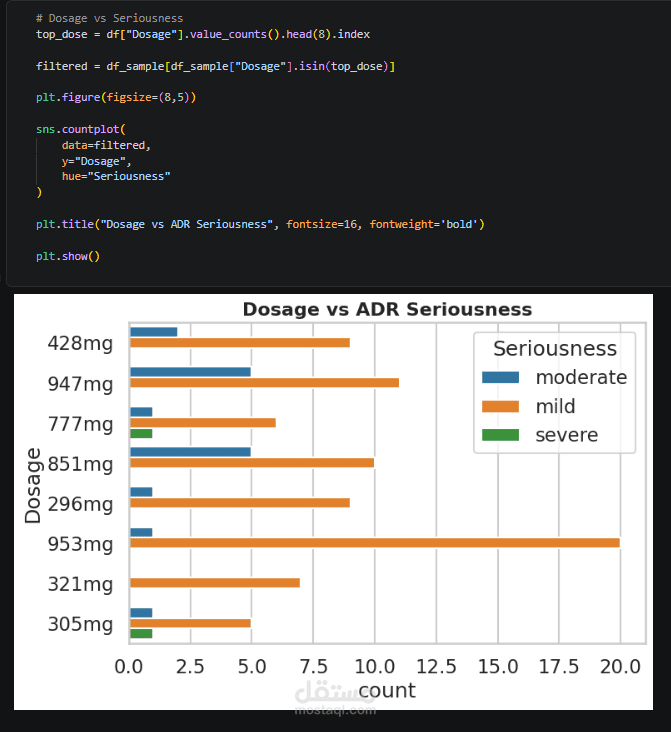
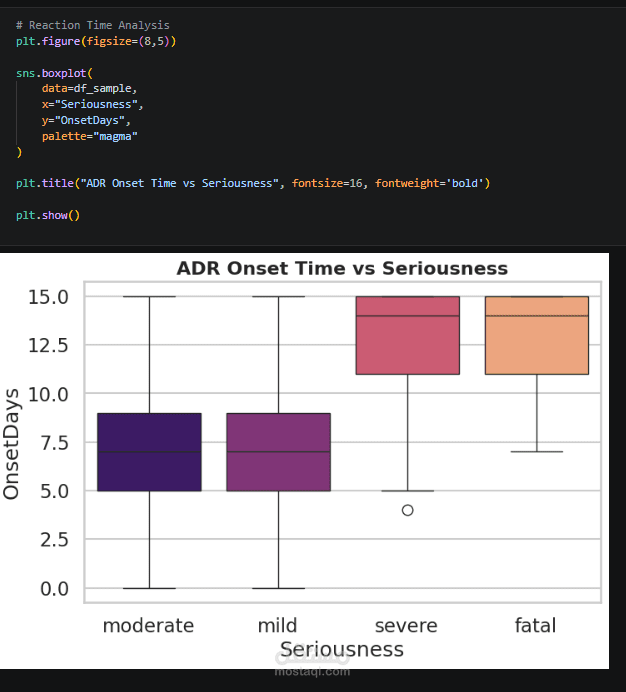
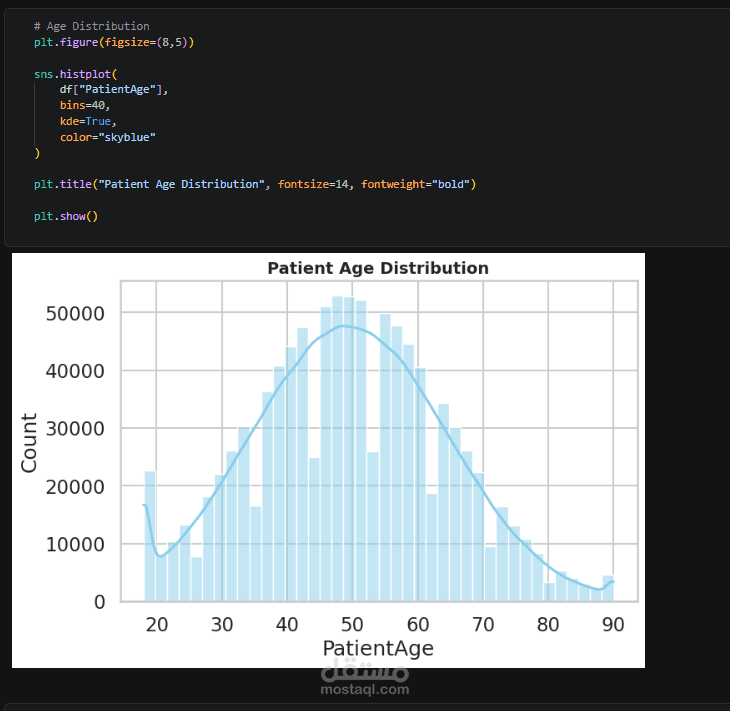
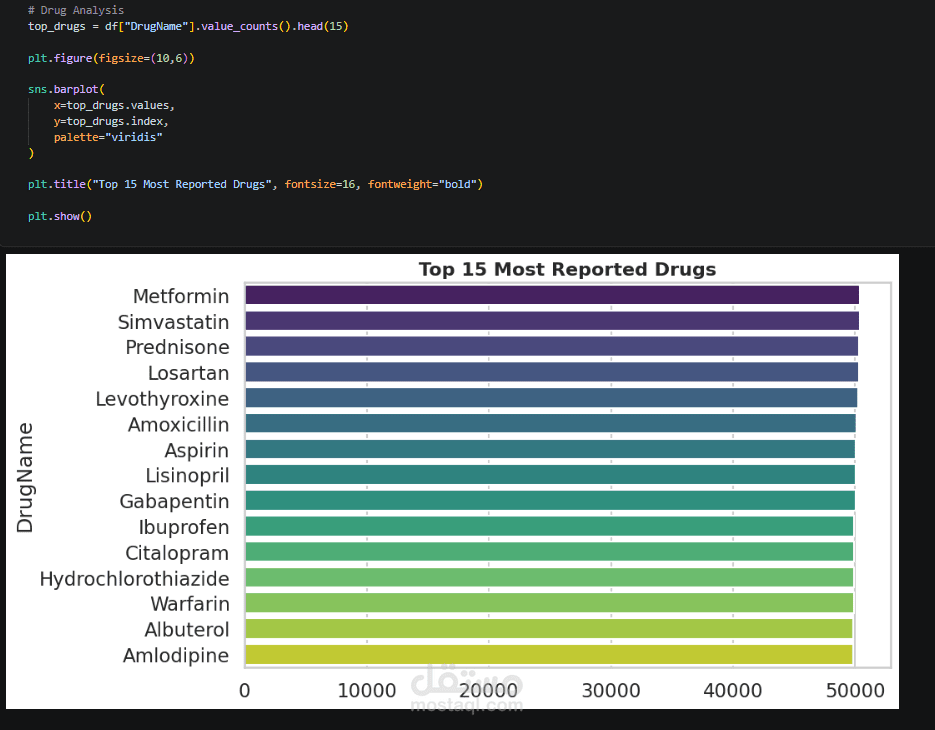
Exploratory Data Analysis (EDA) is performed to uncover patterns between patient characteristics, drug usage, and side effect severity, supported by clear visualizations. A statistical T-test is also applied to identify significant differences between serious and non-serious cases.
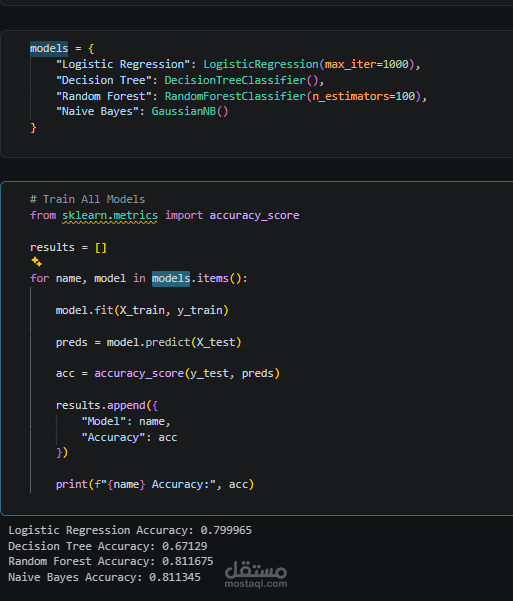
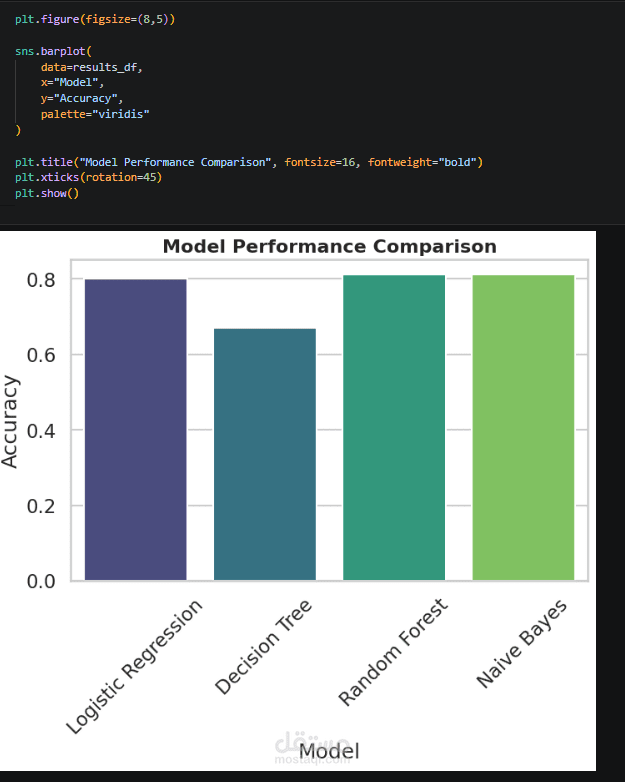
Multiple models are built using Scikit-learn, including Logistic Regression, Decision Tree, Random Forest, and Naive Bayes, to classify reaction severity. The models are evaluated and compared, with feature importance analysis to identify key influencing factors.
The project delivers a complete pipeline for transforming healthcare data into actionable insights and predictive outcomes.