Professional Data Preprocessing Pipeline for Machine Learning Projects
تفاصيل العمل
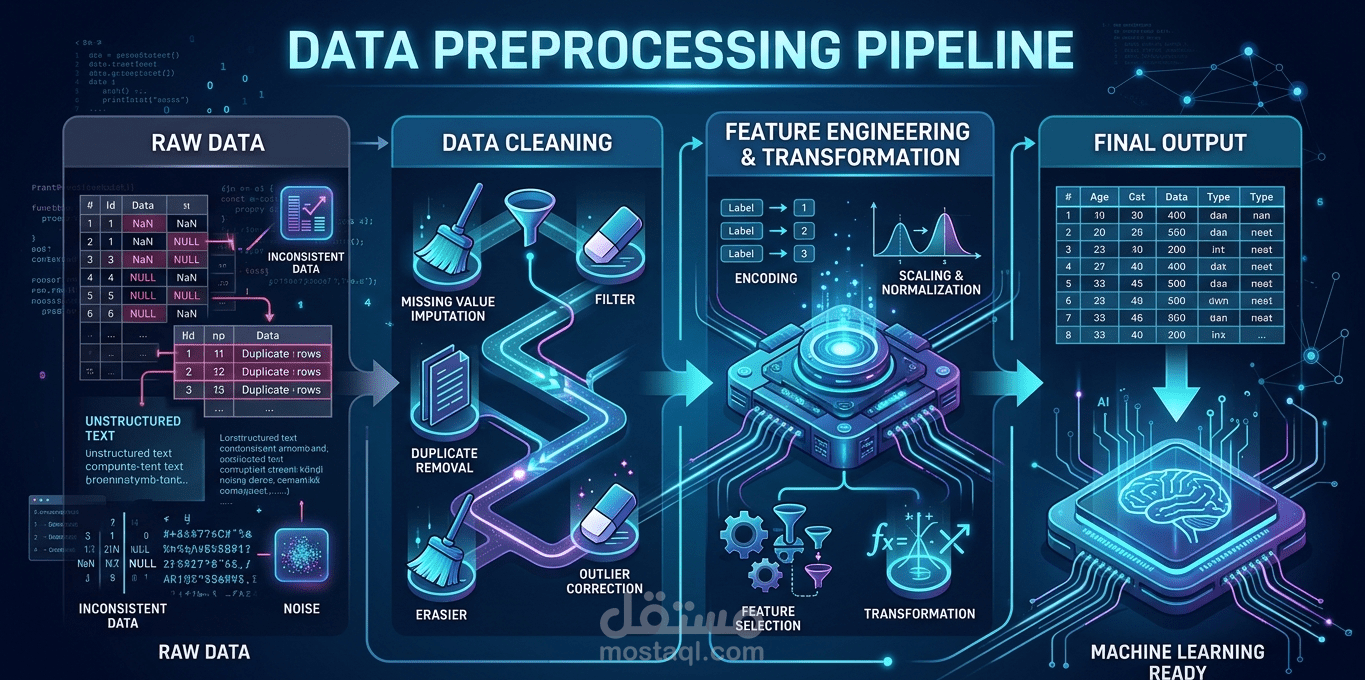
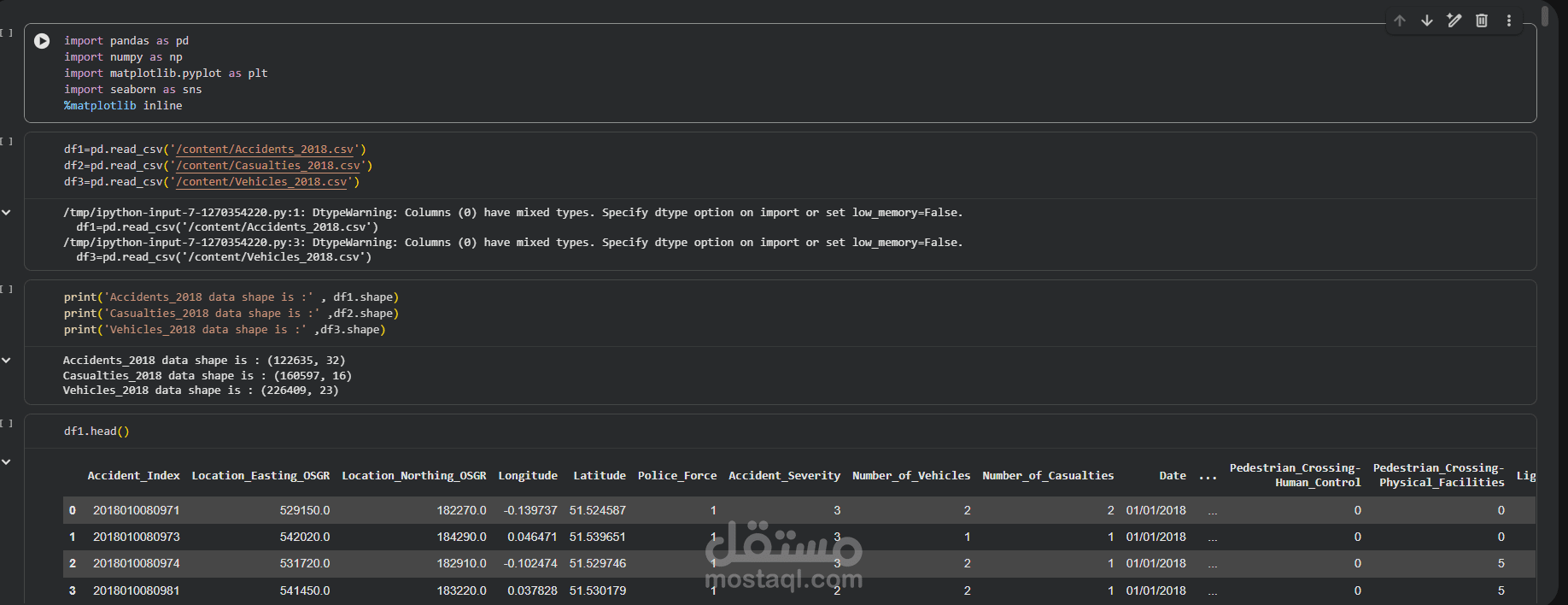
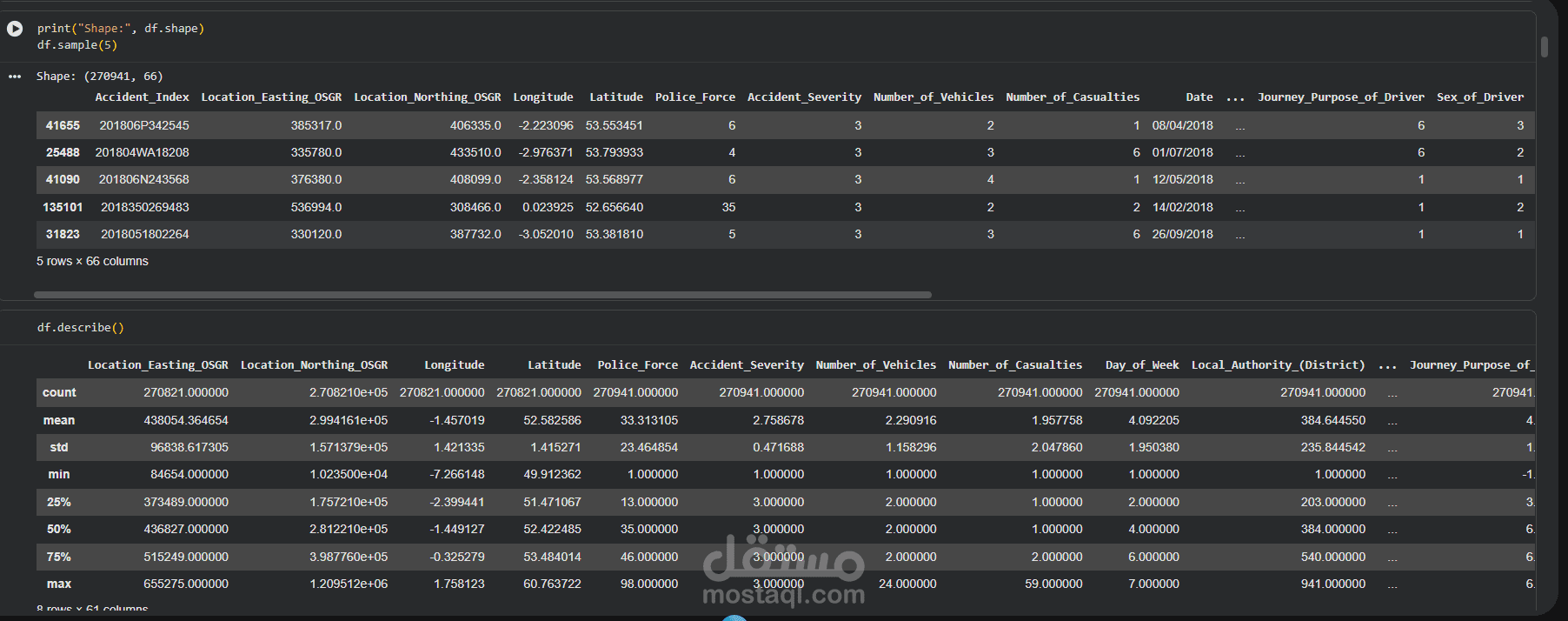
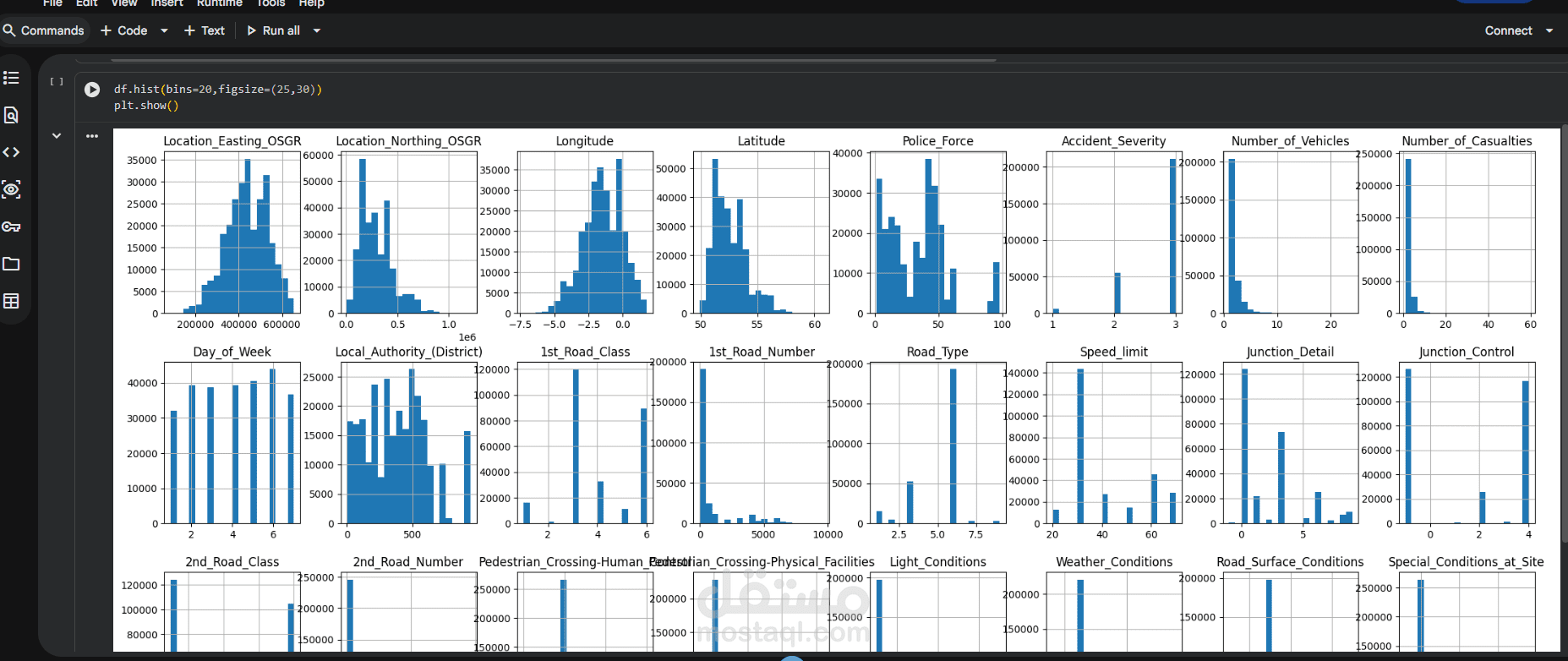
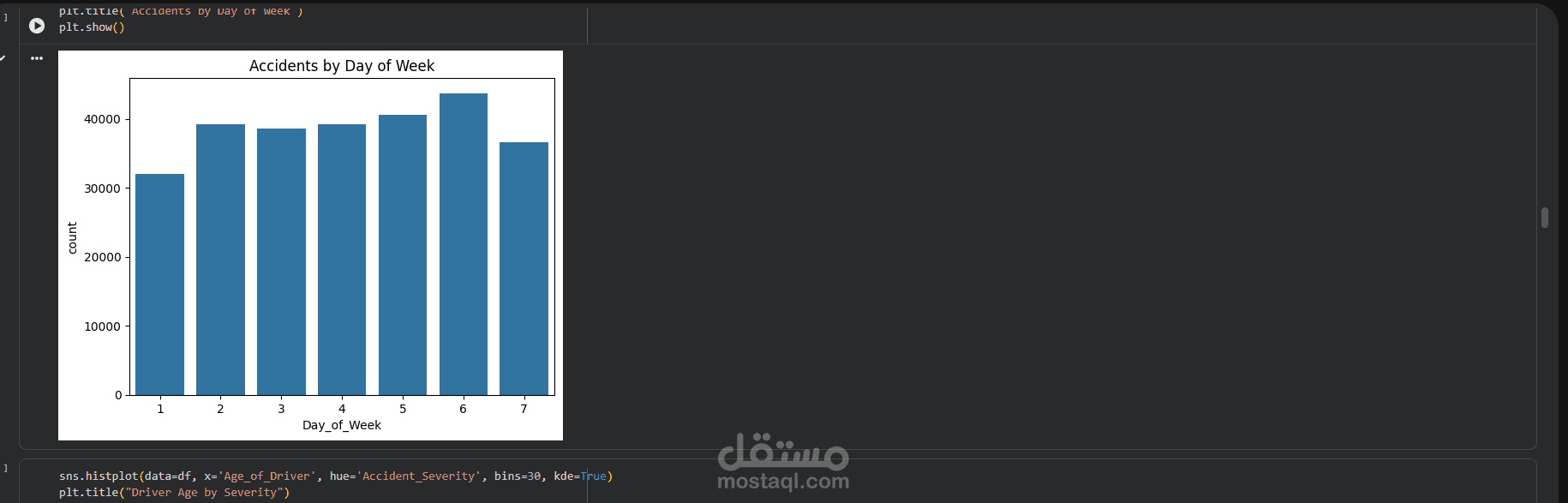
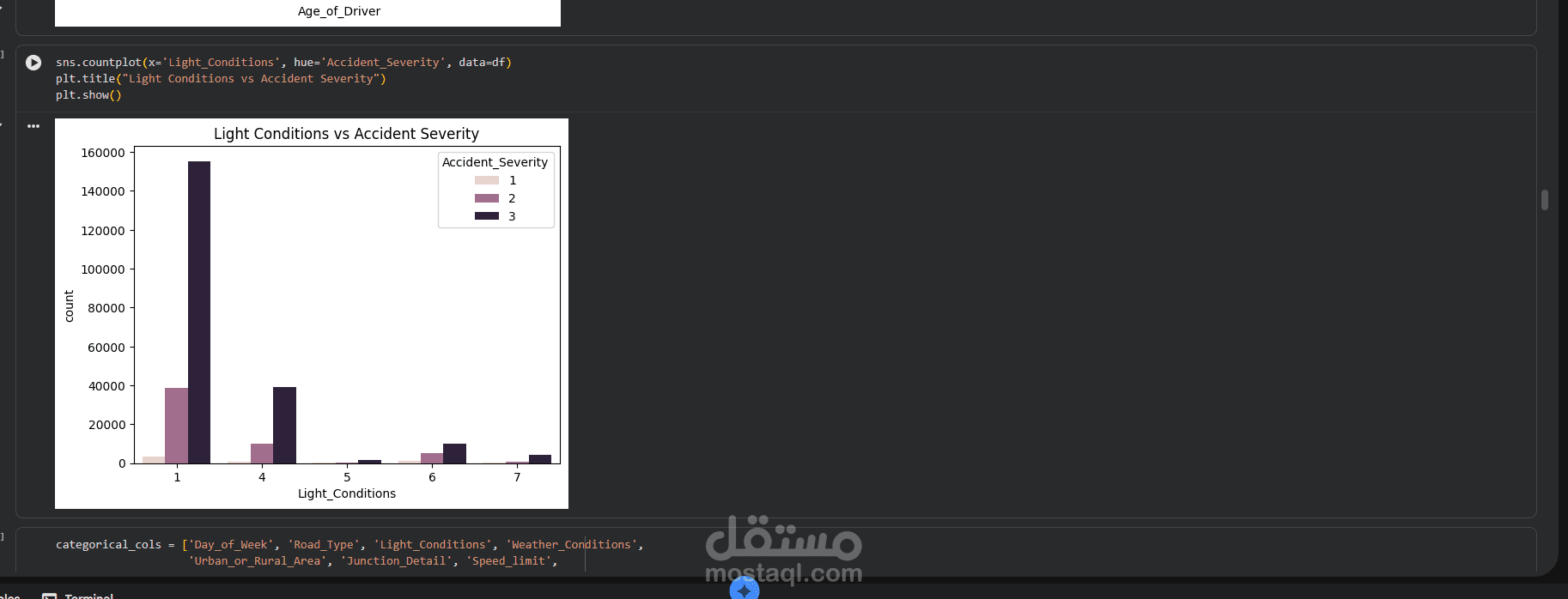
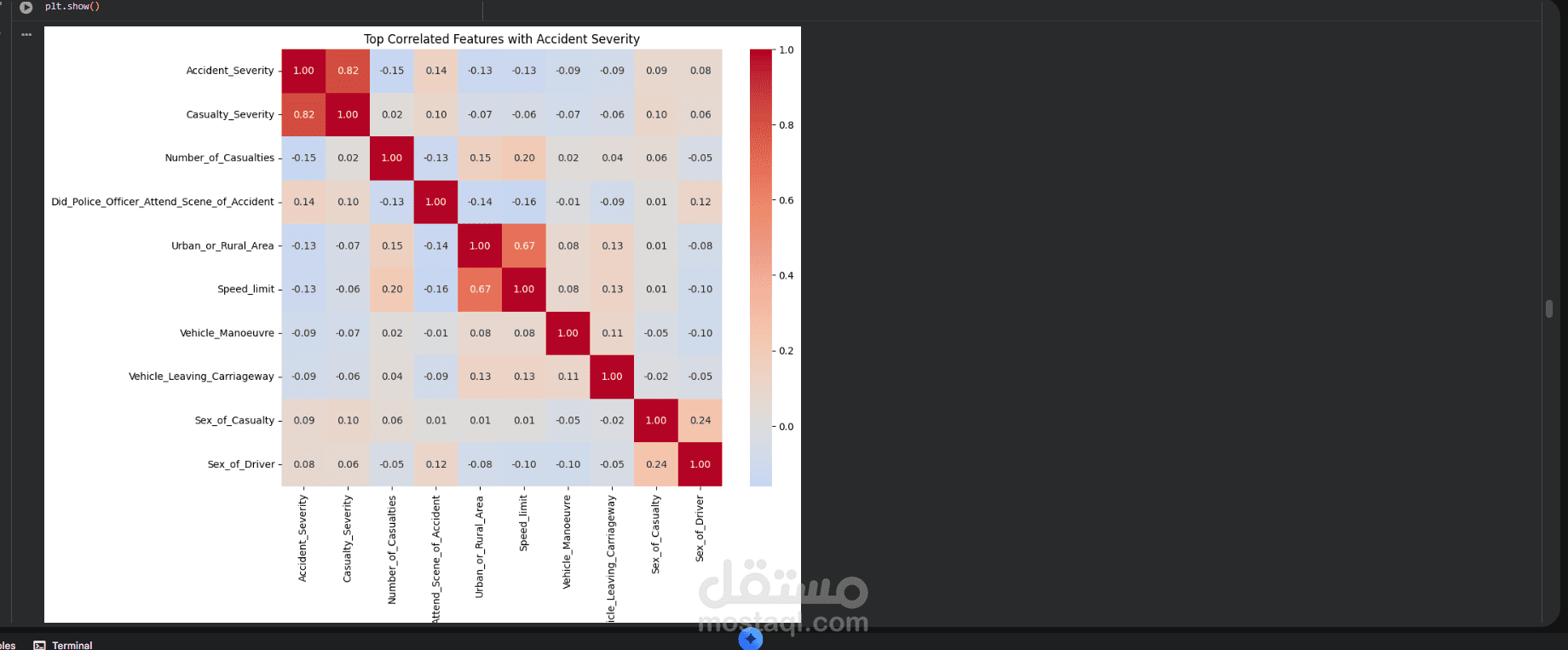
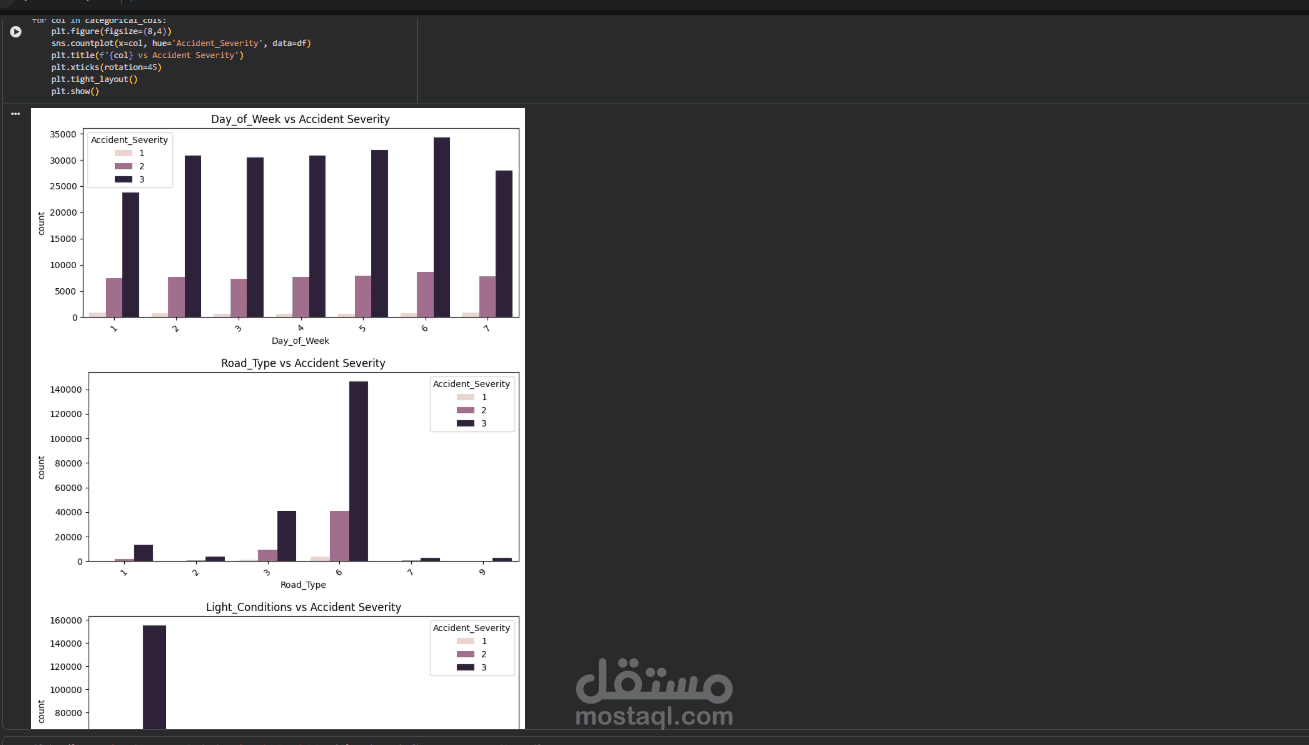
This project focuses on building a complete and professional Data Preprocessing pipeline as a crucial step in any Machine Learning workflow.
The project includes handling real-world dataset issues such as missing values, duplicate records, and inconsistent data types. It also covers encoding categorical variables, feature scaling, and preparing the dataset for machine learning models.
Key steps implemented:
- Data Cleaning (handling missing values & duplicates)
- Exploratory Data Understanding
- Encoding categorical features
- Feature Scaling and normalization
- Outlier detection and treatment
- Data transformation ready for ML models
The workflow is implemented using Python in Google Colab with libraries such as Pandas, NumPy, and Scikit-learn.
This preprocessing pipeline ensures high-quality structured data ready for training machine learning models with improved performance and accuracy.