Data Pipeline: Web Scraping + API Integration + Data Cleaning + MySQL Storage
تفاصيل العمل
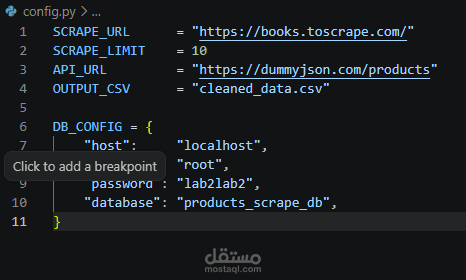
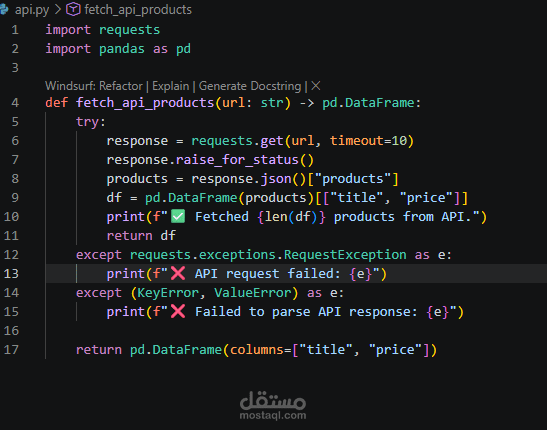
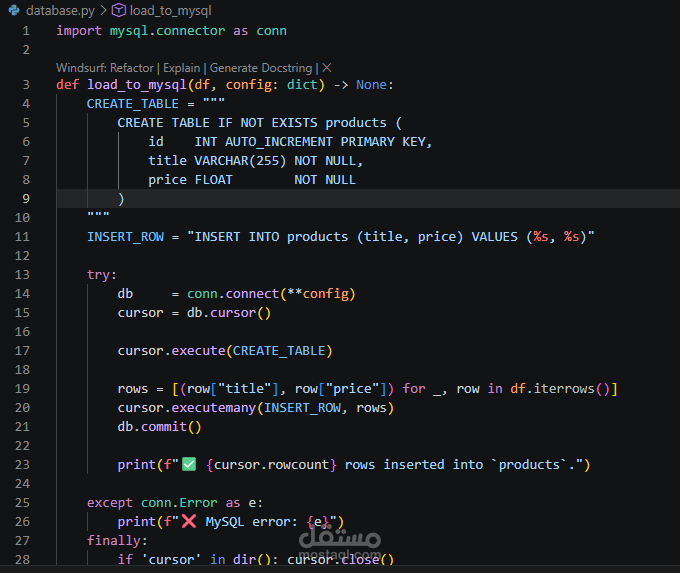
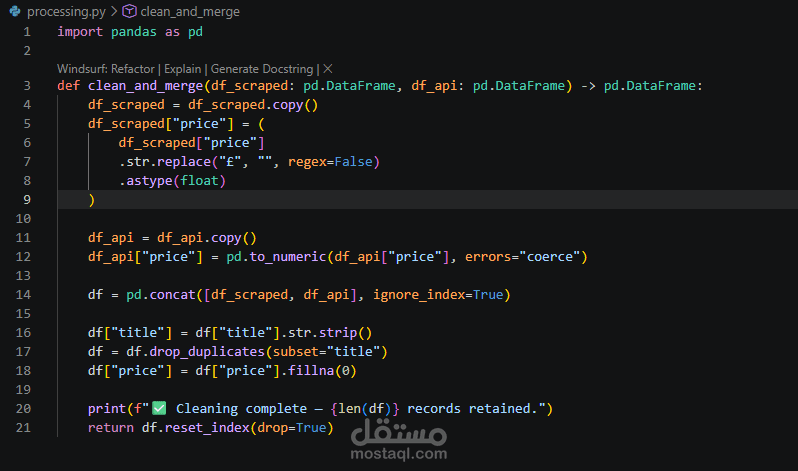
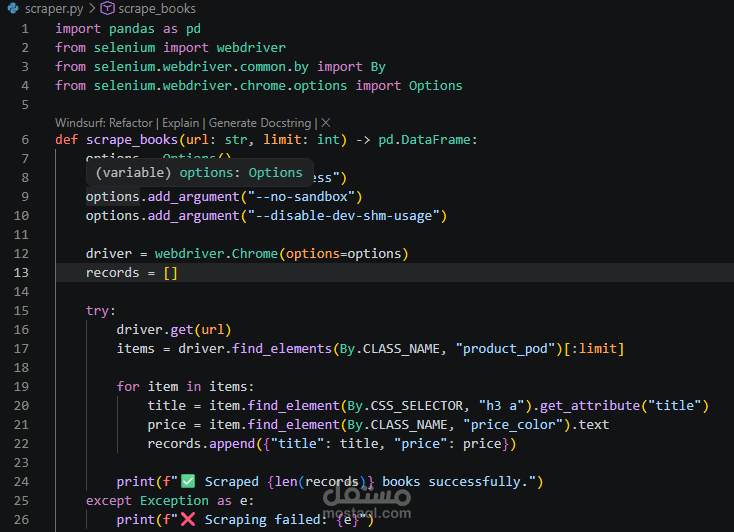
هذا المشروع عبارة عن خط معالجة بيانات متكامل (Data Pipeline) تم تطويره باستخدام لغة Python، ويهدف إلى جمع البيانات من مصادر متعددة، معالجتها، ثم تخزينها بشكل منظم.
مميزات المشروع:
استخراج البيانات من موقع ويب باستخدام Selenium (Web Scraping)
جلب بيانات إضافية من خلال API خارجي
تنظيف البيانات ومعالجتها باستخدام مكتبة Pandas
دمج البيانات من أكثر من مصدر وإزالة التكرار
حفظ البيانات النهائية في ملف CSV
تخزين البيانات داخل قاعدة بيانات MySQL
التقنيات المستخدمة:
Python
Pandas
Selenium
Requests
MySQL
آلية العمل:
استخراج البيانات من الموقع
جلب بيانات إضافية من الـ API
تنظيف البيانات وتحسين جودتها
دمج البيانات في Dataset واحدة
حفظ النتائج في CSV وقاعدة البيانات
يعكس هذا المشروع تطبيقًا عمليًا لمفاهيم هندسة البيانات (Data Engineering)، ويمكن تطويره لاحقًا ليعمل كـ Pipeline متكامل في بيئة Production.