Orange Data Mining Workflow
تفاصيل العمل
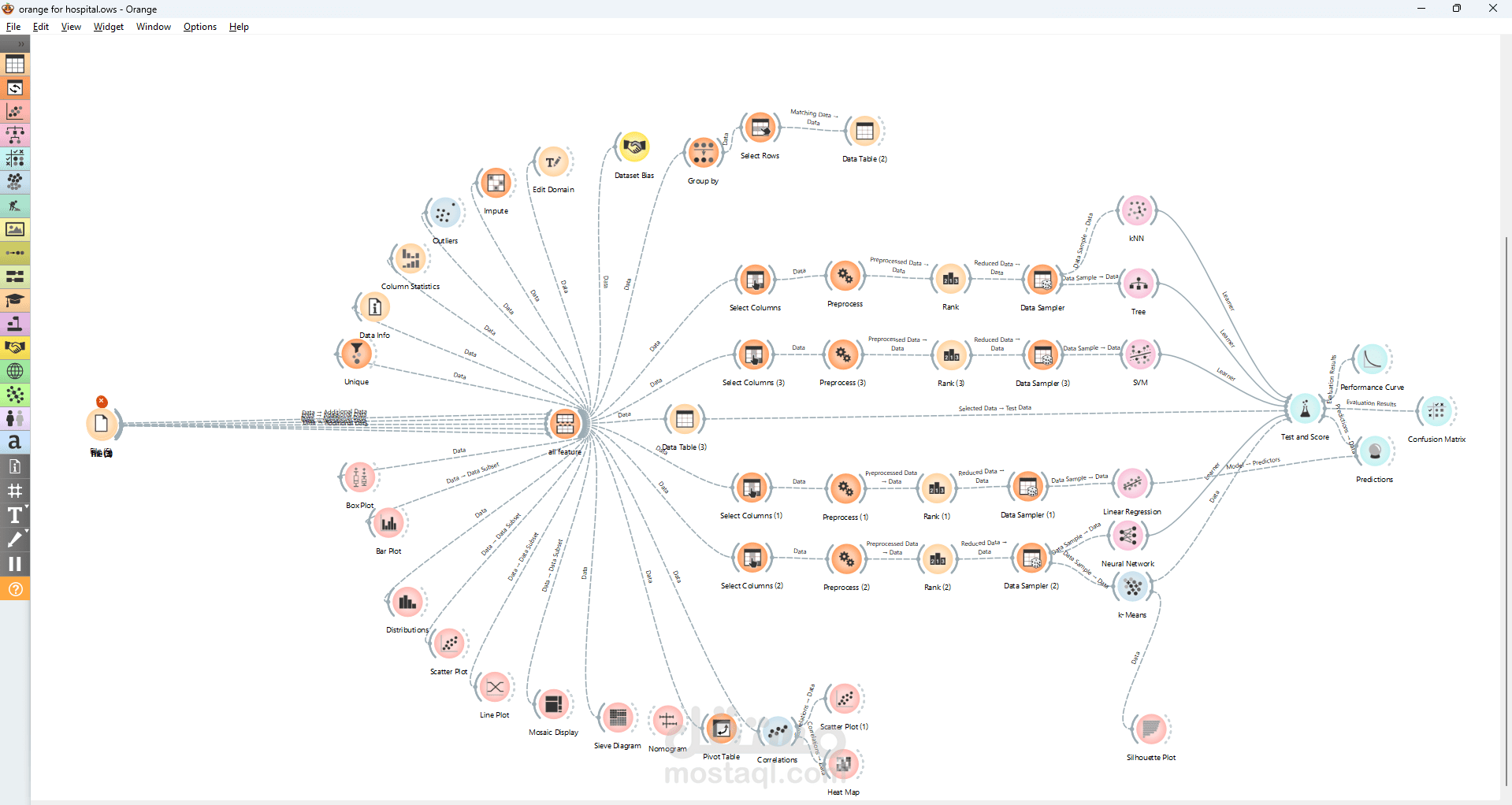
تصميم Data Pipeline كامل باستخدام Drag & Drop (من تحميل البيانات إلى التنبؤ)
إجراء Exploratory Data Analysis (EDA) باستخدام أدوات مثل:
توزيع البيانات (Distributions)
العلاقات بين المتغيرات (Scatter Plot, Correlation)
تطبيق خوارزميات Machine Learning مثل:
Classification (Logistic Regression / Decision Tree)
Clustering (K-Means)
تقييم النماذج باستخدام:
Confusion Matrix
ROC Curve
Accuracy & AUC
مقارنة أكثر من نموذج واختيار الأفضل بناءً على الأداء