Web Data Extraction & ETL Pipeline
تفاصيل العمل
Web Data Extraction & ETL Pipeline
This project demonstrates a complete data engineering pipeline that extracts, transforms, and loads data from multiple sources into a structured and queryable format.
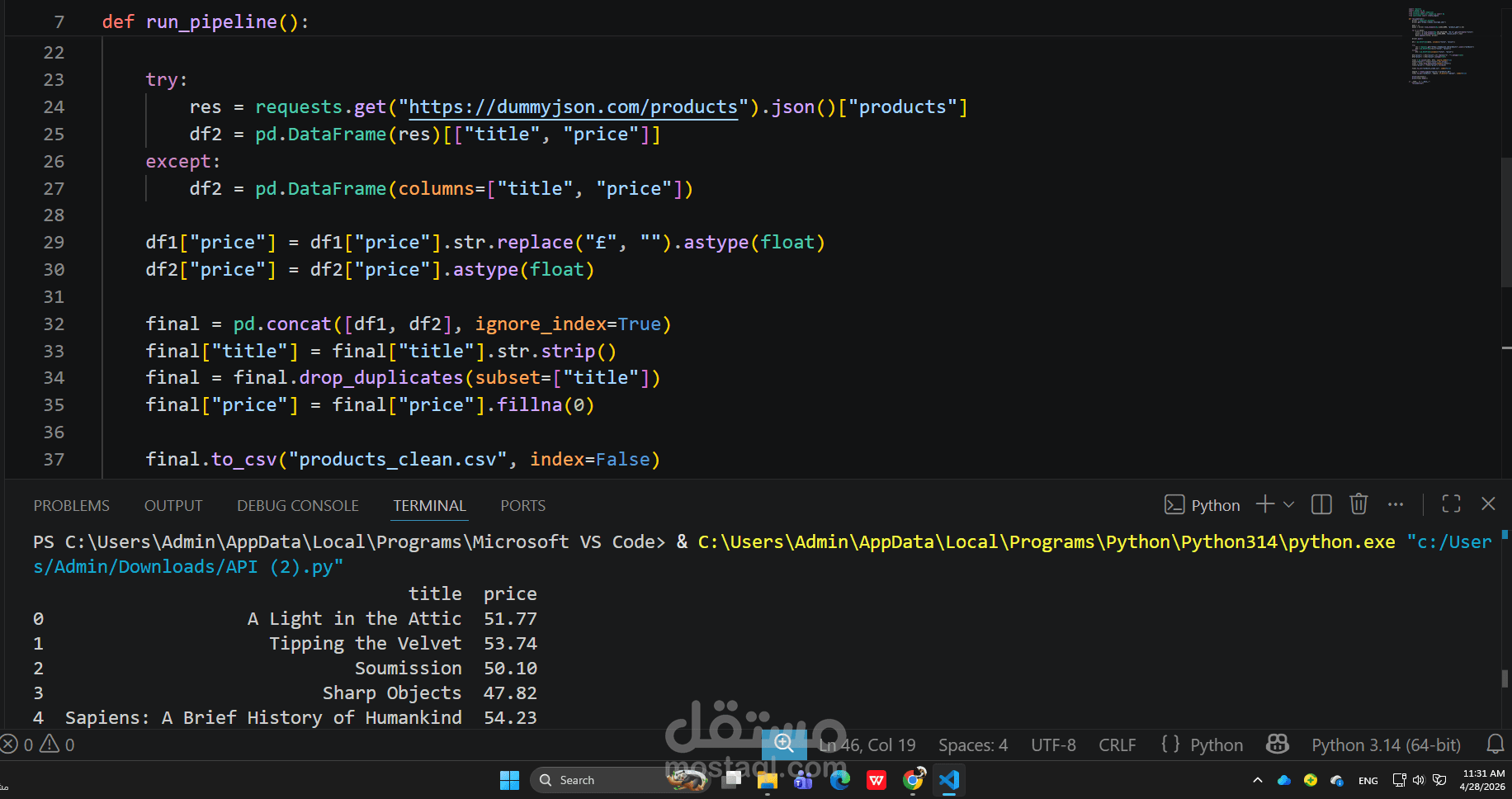
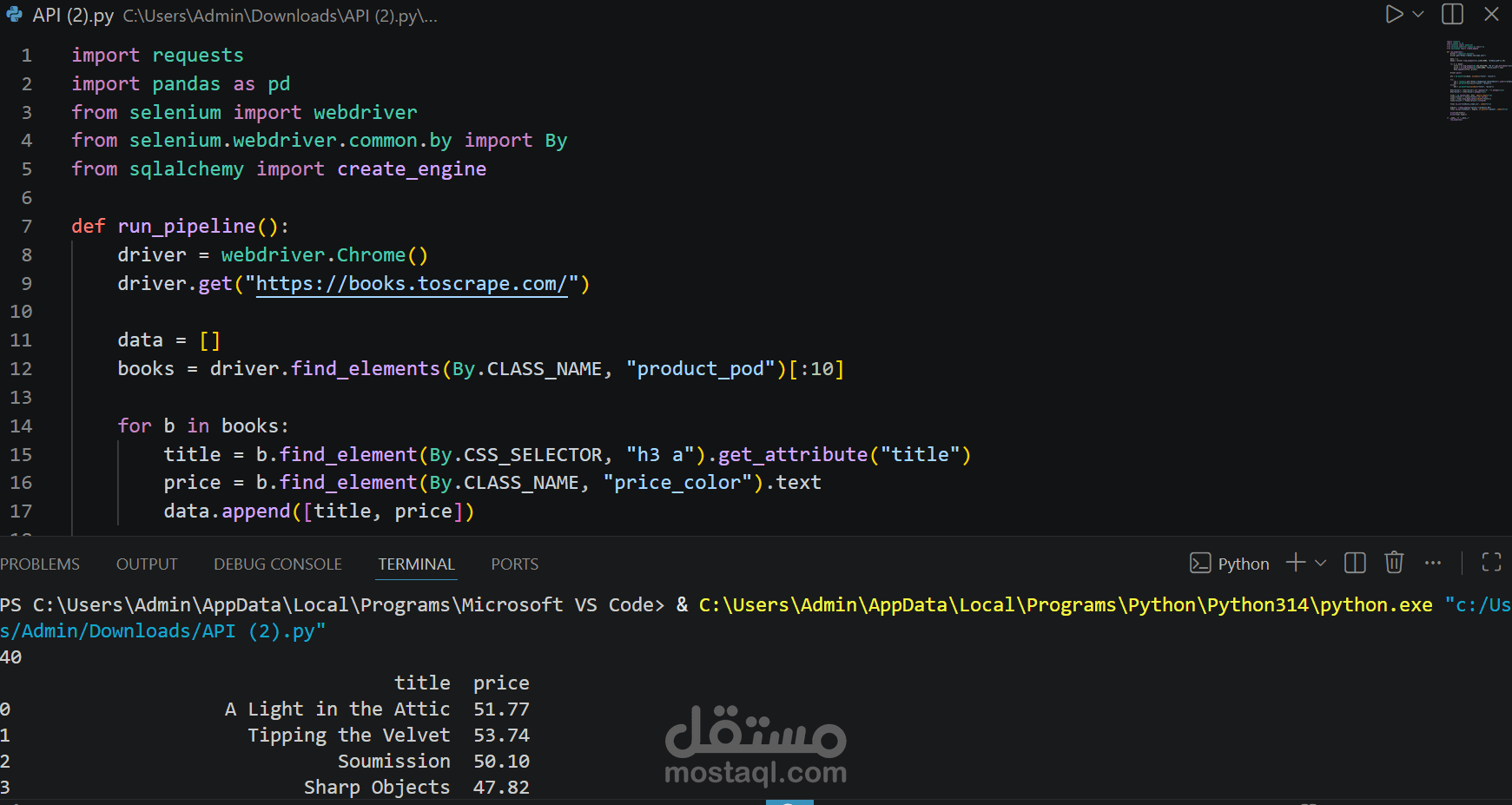
The pipeline integrates both web scraping and API ingestion. Data is extracted from an e-commerce website using Selenium and combined with external product data retrieved via a REST API. This simulates real-world scenarios where data engineers work with heterogeneous data sources.
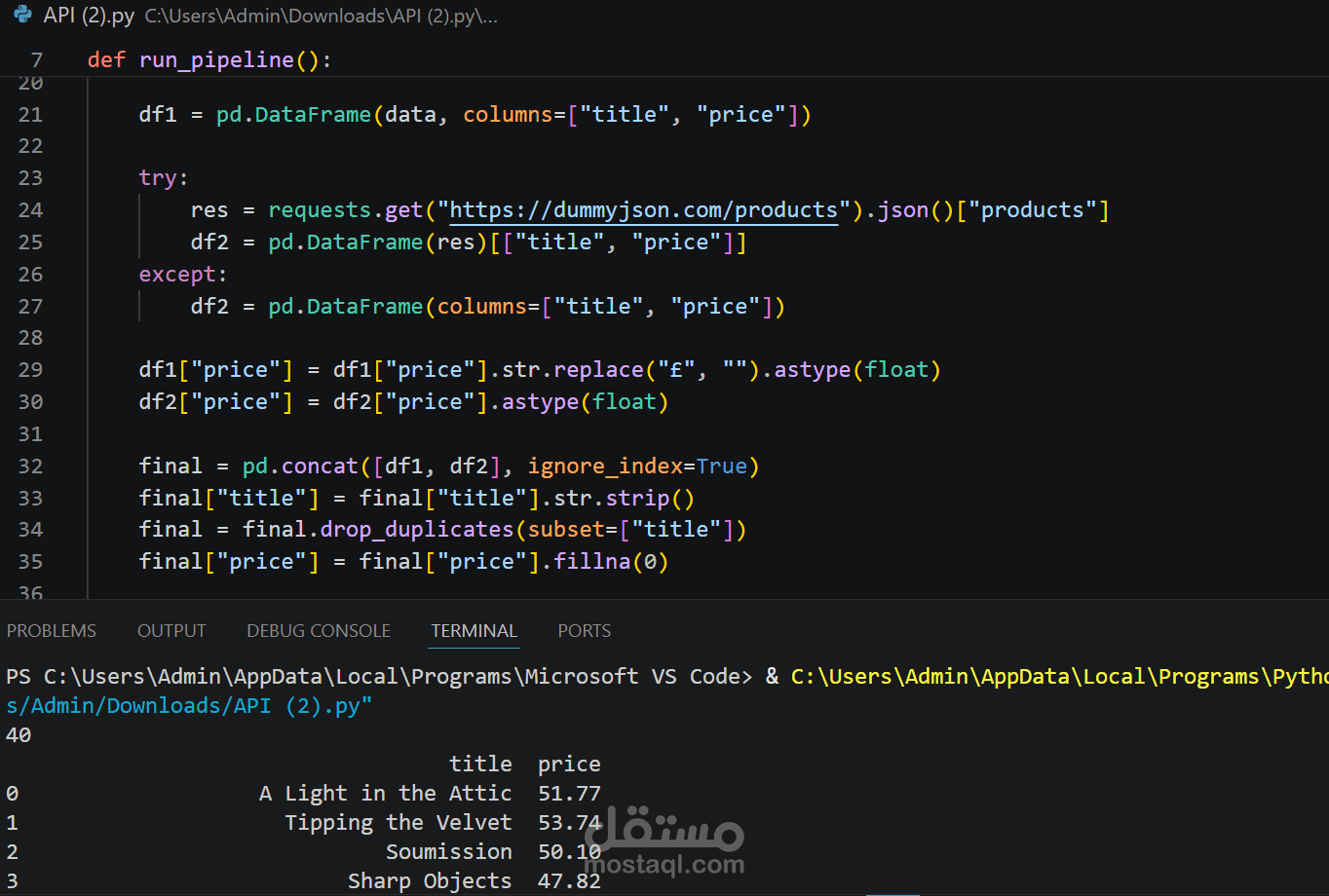
During the transformation phase, raw data is cleaned and standardized by handling missing values, removing duplicates, normalizing text fields, and converting price formats into consistent numerical values.
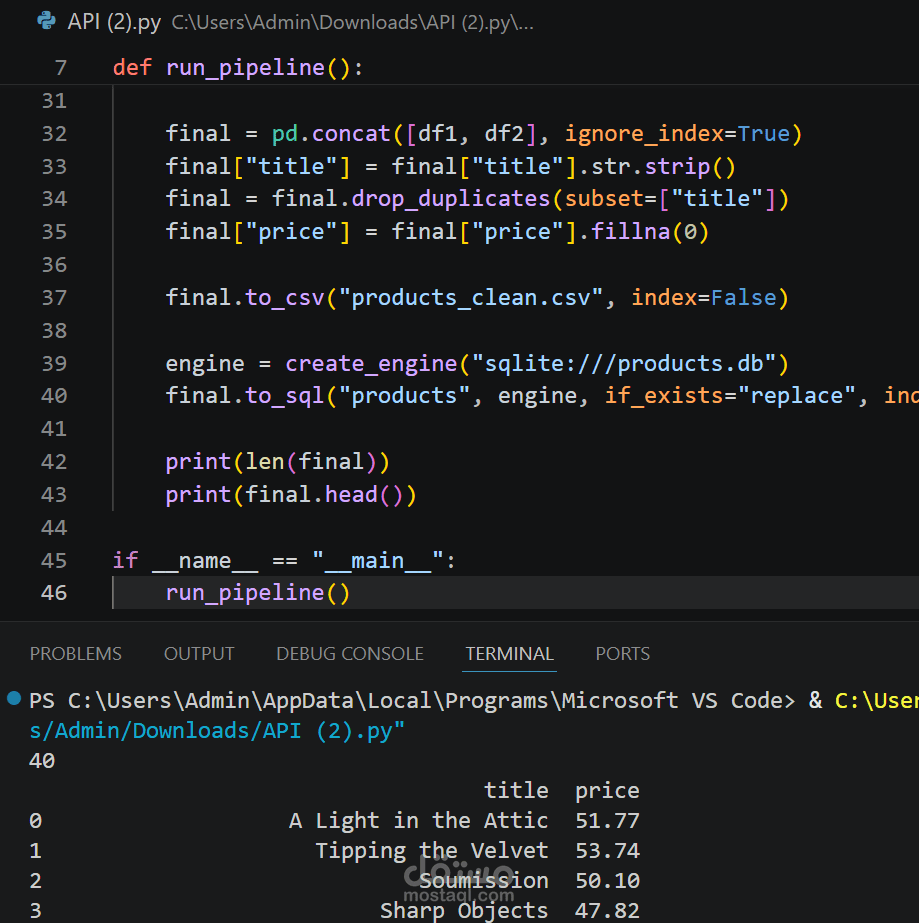
The processed data is then stored in two layers:
* A CSV file for easy access and sharing
* A SQLite database to support structured querying and downstream analytics
This project highlights the implementation of a lightweight ETL pipeline, focusing on data collection, cleaning, and storage while ensuring data quality and consistency.
**Key Features:**
* Web scraping using Selenium
* API data ingestion using requests
* Data cleaning and preprocessing with Pandas
* Data merging from multiple sources
* Duplicate handling and normalization
* Data storage in CSV and relational database
Tech Stack:** Python, Pandas, Selenium, Requests, SQLite, SQLAlchemy