Web Crawler
تفاصيل العمل
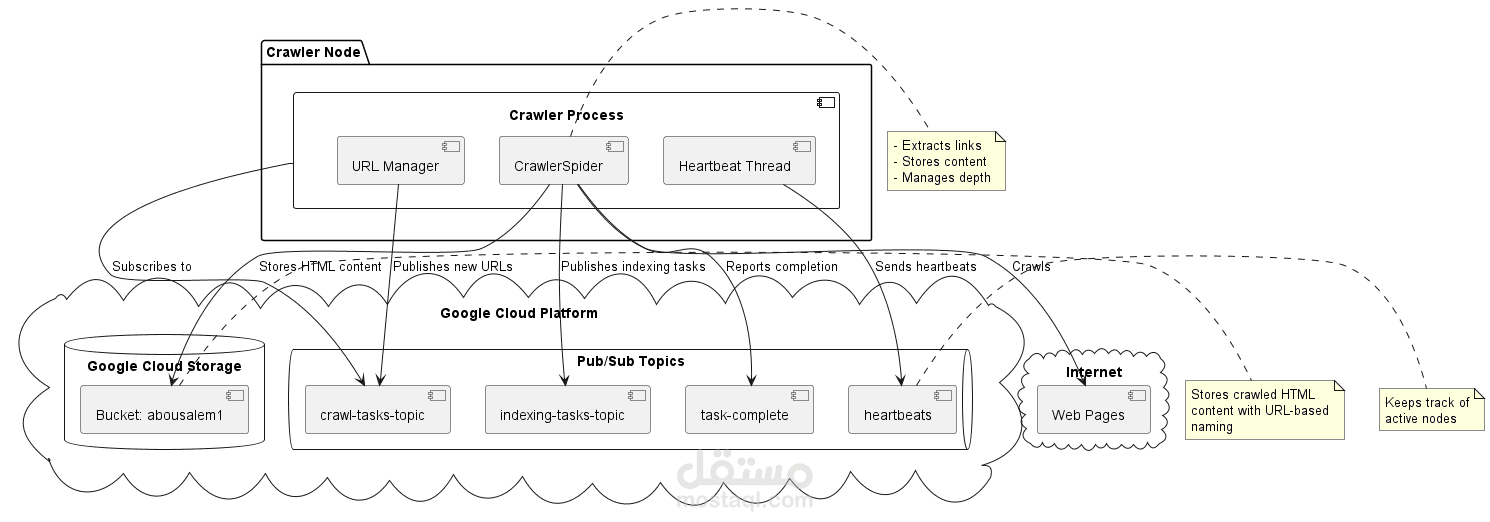
مشروع Web Crawler هو نظام زاحف ويب موزع ومتكامل تم تطويره بلغة بايثون، يوفر بنية متقدمة لإدارة مهام الزحف والمعالجة والفهرسة.
الميزات الأساسية:
نظام مركزي Master لتوزيع مهام الزحف وإدارة حالات العقد (Crawler Nodes) عبر بروتوكولات تواصل مثل Redis وGoogle Pub/Sub.
عقد زاحف متعددة تقوم بجلب صفحات الويب، استخراج النصوص والروابط، وإرسال النتائج للمعالج المركزي.
مؤشر بحث Indexer باستخدام مكتبة Whoosh لفهرسة المحتوى والعناوين، مما يتيح البحث السريع ضمن الصفحات المفهرسة.
دعم آليات مراقبة الحالة والتواقيت الحية (heartbeat) لاكتشاف العقد المتوقفة وإعادة جدولة المهام تلقائياً.
واجهة أمامية قائمة على React وTailwind لعرض حالة النظام وإرسال أوامر الزحف والتعامل مع نتائج البحث.
تكامل مع خدمات Google Cloud مثل Pub/Sub وCloud Storage للمراسلة وتخزين البيانات.