Loan Risk
تفاصيل العمل
1. تحميل البيانات والاستكشاف الأولي (Data Loading and Exploration)
استيراد البيانات: تم تحميل مجموعة البيانات loan_risk_prediction_dataset.csv والتي تتكون من 5000 صف و 10 أعمدة (مثل: العمر، الدخل، مبلغ القرض، درجة الائتمان، سنوات الخبرة، الجنس، التعليم، المدينة، نوع التوظيف، الموافقة على القرض).
استكشاف البيانات: تم فحص هيكل البيانات باستخدام df.info()، والحصول على الإحصائيات الوصفية باستخدام df.describe()، بالإضافة إلى التحقق من القيم المفقودة (Null values) والصفوف المكررة.
2. تنظيف البيانات (Data Cleaning)
حذف الميزات: تم إسقاط (Drop) عمود "الجنس" (Gender) من مجموعة البيانات.
التعامل مع القيم المفقودة:
تم ملء القيم المفقودة في الأعمدة الرقمية (Income و CreditScore) باستخدام الـ الوسيط (Median).
تم ملء القيم المفقودة في عمود Education باستخدام المنوال (Mode) (القيمة الأكثر تكراراً).
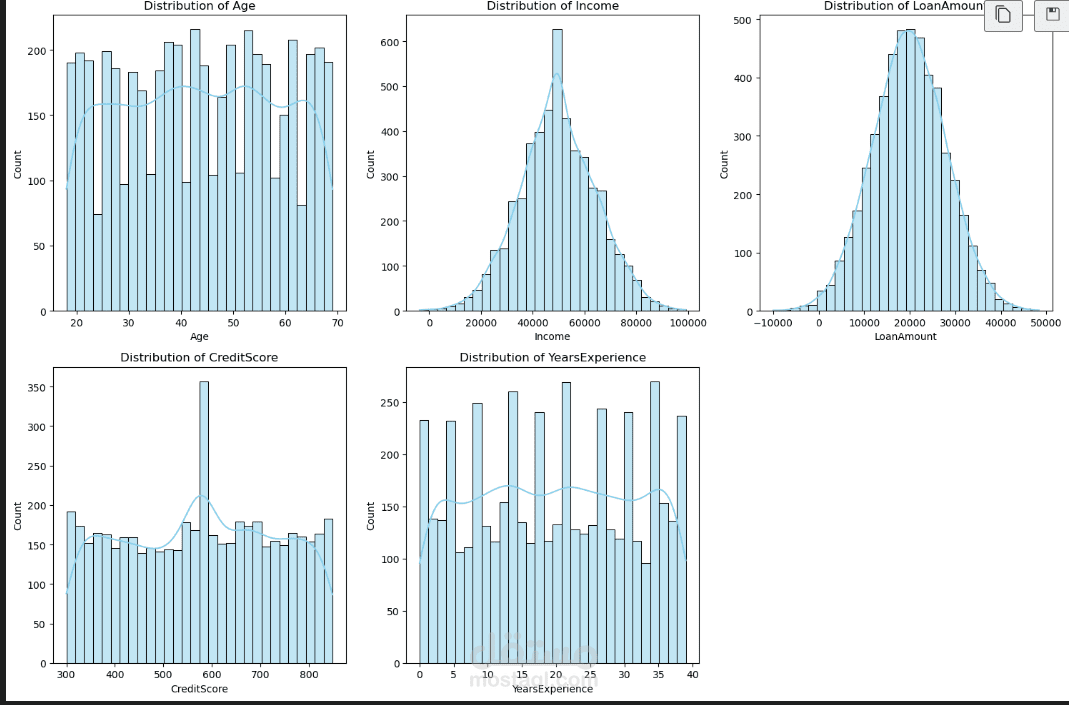
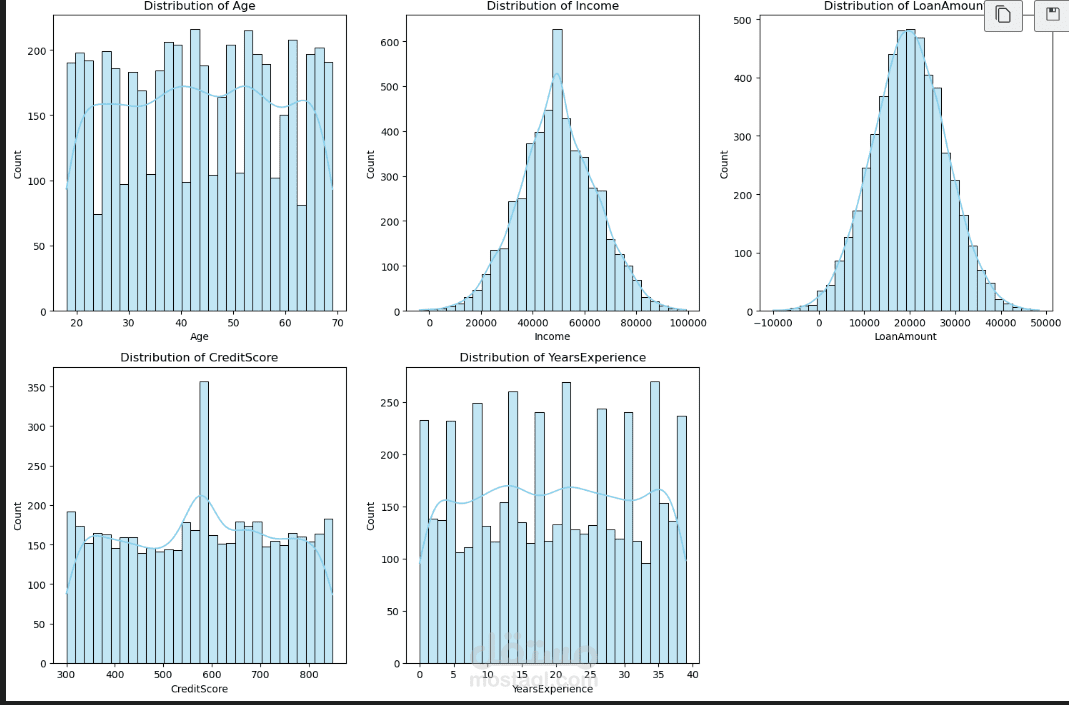
3. تحليل البيانات الاستكشافي وتصور البيانات (EDA & Visualization)
تم رسم رسم بياني شريطي (Count plot) لفهم توزيع المتغير المستهدف (LoanApproved).
تم إنشاء رسومات بيانية (Bar charts) لتوزيع الميزات الفئوية (Categorical columns) مثل Education، City، و EmploymentType.
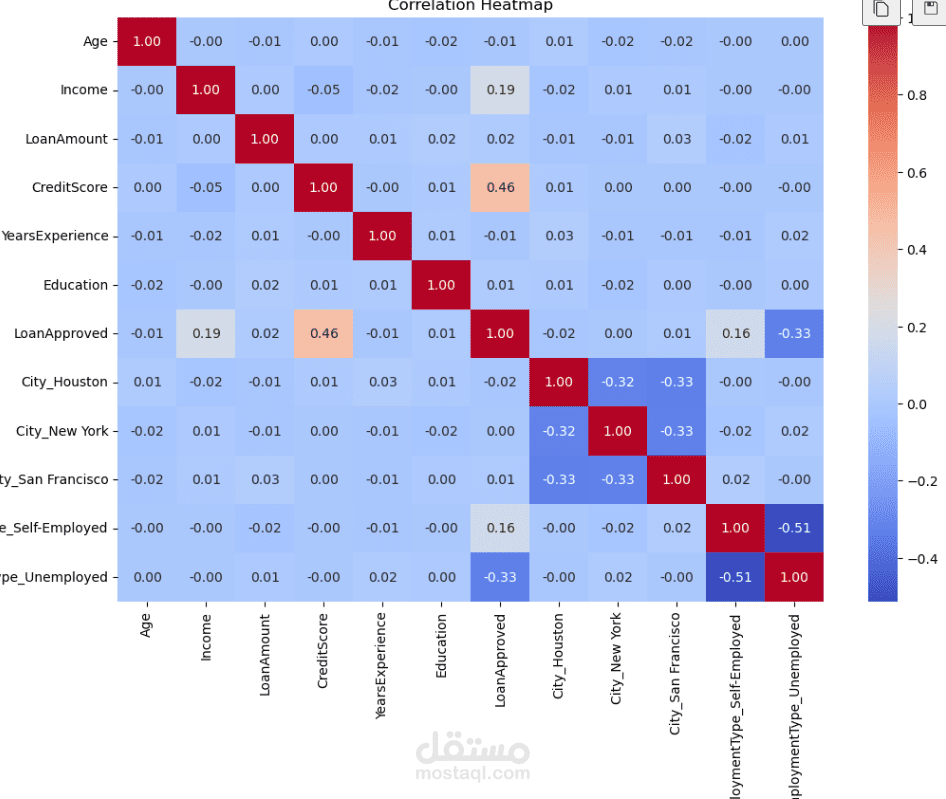
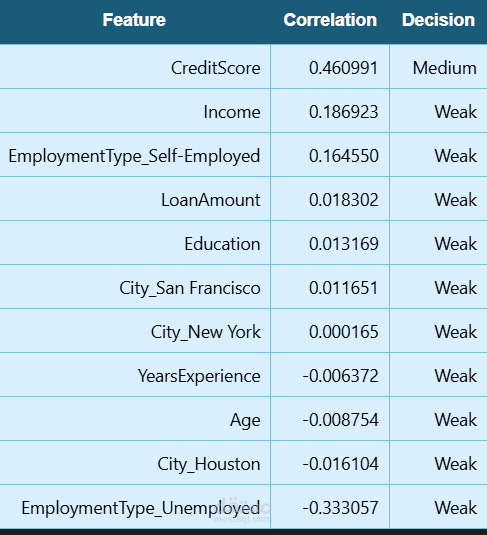
تم رسم خريطة حرارية للارتباط (Correlation Heatmap) لتحليل العلاقات الخطية بين المتغيرات الرقمية.
4. المعالجة المسبقة للبيانات (Data Preprocessing & Feature Engineering)
الترميز الترتيبي (Ordinal Encoding): تم تحويل عمود التعليم Education إلى قيم رقمية ترتيبة (0 للثانوية، 1 للبكالوريوس، 2 للماجستير، 3 للدكتوراه).
التشفير الثنائي (One-Hot Encoding): تم استخدام وظيفة pd.get_dummies مع drop_first=True لتحويل أعمدة City و EmploymentType إلى متغيرات وهمية (Dummy variables).
تم فصل مجموعة البيانات إلى متغيرات مستقلة / ميزات (X) والمتغير المستهدف (y).
5. معالجة البيانات غير المتوازنة وتوحيد المقاييس (Imbalanced Data & Scaling)
تقنية SMOTE: تم استخدام تقنية أخذ العينات الزائدة للأقلية (SMOTE) لمعالجة عدم توازن الفئات في المتغير المستهدف، حتى لا ينحاز النموذج للفئة الأكبر.
توحيد المقاييس (Standardization): تم استخدام StandardScaler لتوحيد مقاييس قيم الميزات للتأكد من أن جميعها تساهم بشكل متساوٍ في النموذج.
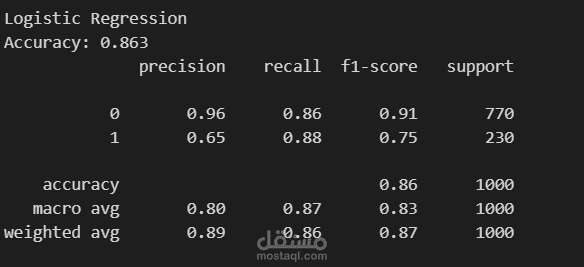
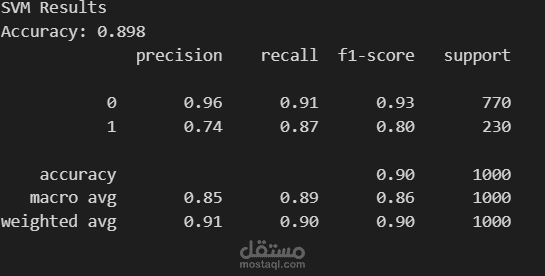
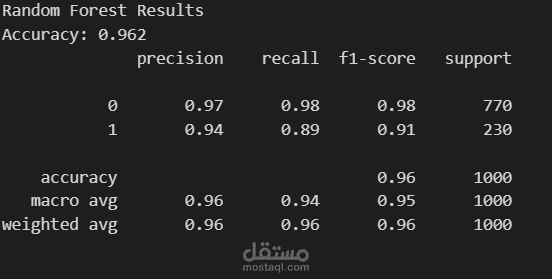
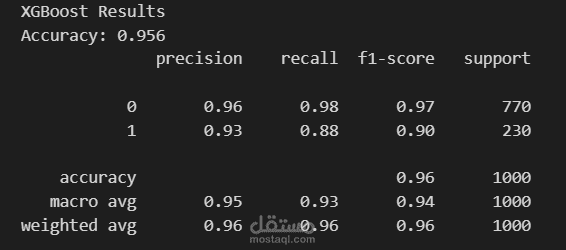
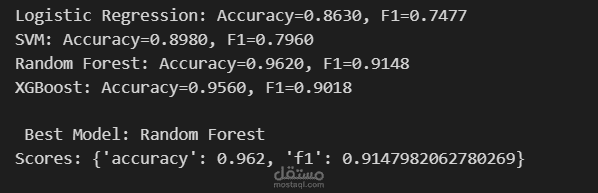
6. تدريب وتقييم النموذج (Model Training and Evaluation)
تم تقسيم البيانات (المتوازنة والموحدة المقاييس) إلى مجموعة تدريب ومجموعة اختبار باستخدام train_test_split.
تم تهيئة وتدريب خوارزمية الغابة العشوائية (Random Forest Classifier).
تم تقييم أداء النموذج على مجموعة الاختبار، حيث حقق دقة ممتازة بلغت حوالي 99.4%. كما تم استخراج مصفوفة الارتباك (Confusion matrix) وتقرير التصنيف (Classification report) لعرض مقاييس الدقة والاستدعاء (Precision, Recall, F1-score).