House Prices
تفاصيل العمل
1. استكشاف البيانات والمعالجة الأولية (EDA & Preprocessing):
استيراد البيانات: تحميل بيانات التدريب من ملف train.csv واستعراضها لفهم أنواع المتغيرات (عددية ونَصية).
معالجة الأنواع: تحويل جميع الأعمدة النصية (Object) إلى نوع فئوي (Category) لتسهيل تعامل النماذج معها.
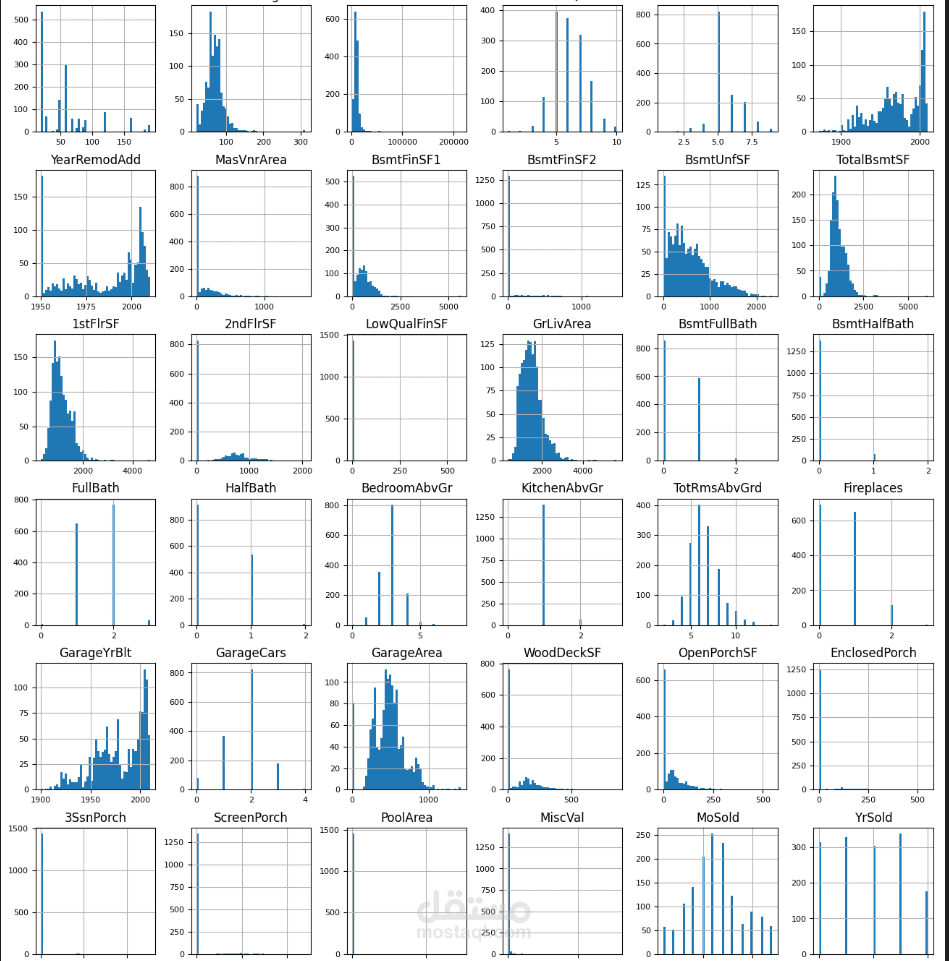
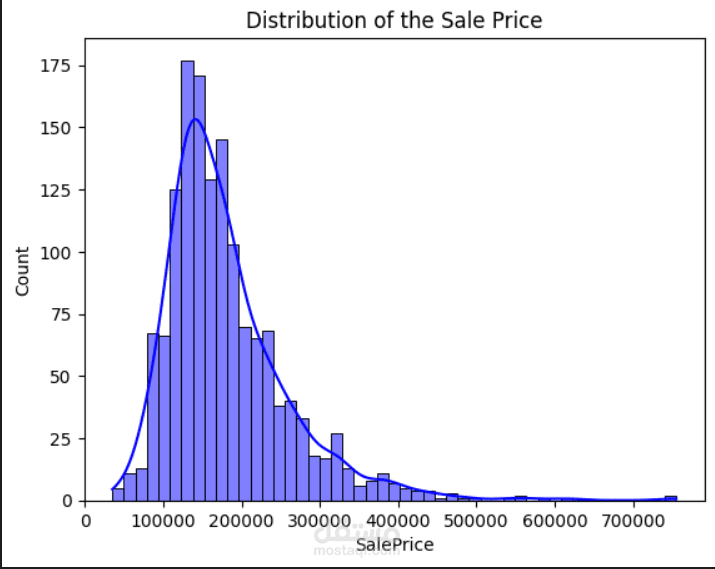
الرسوم البيانية: رسم توزيع المتغير المستهدف SalePrice (سعر المنزل) للتعرف على طبيعة بياناته، وكذلك رسم المدرجات التكرارية (Histograms) لجميع المتغيرات الرقمية الأخرى.
حذف الأعمدة غير الضرورية: إزالة عمود المعرّف Id لعدم أهميته في عملية التوقع.
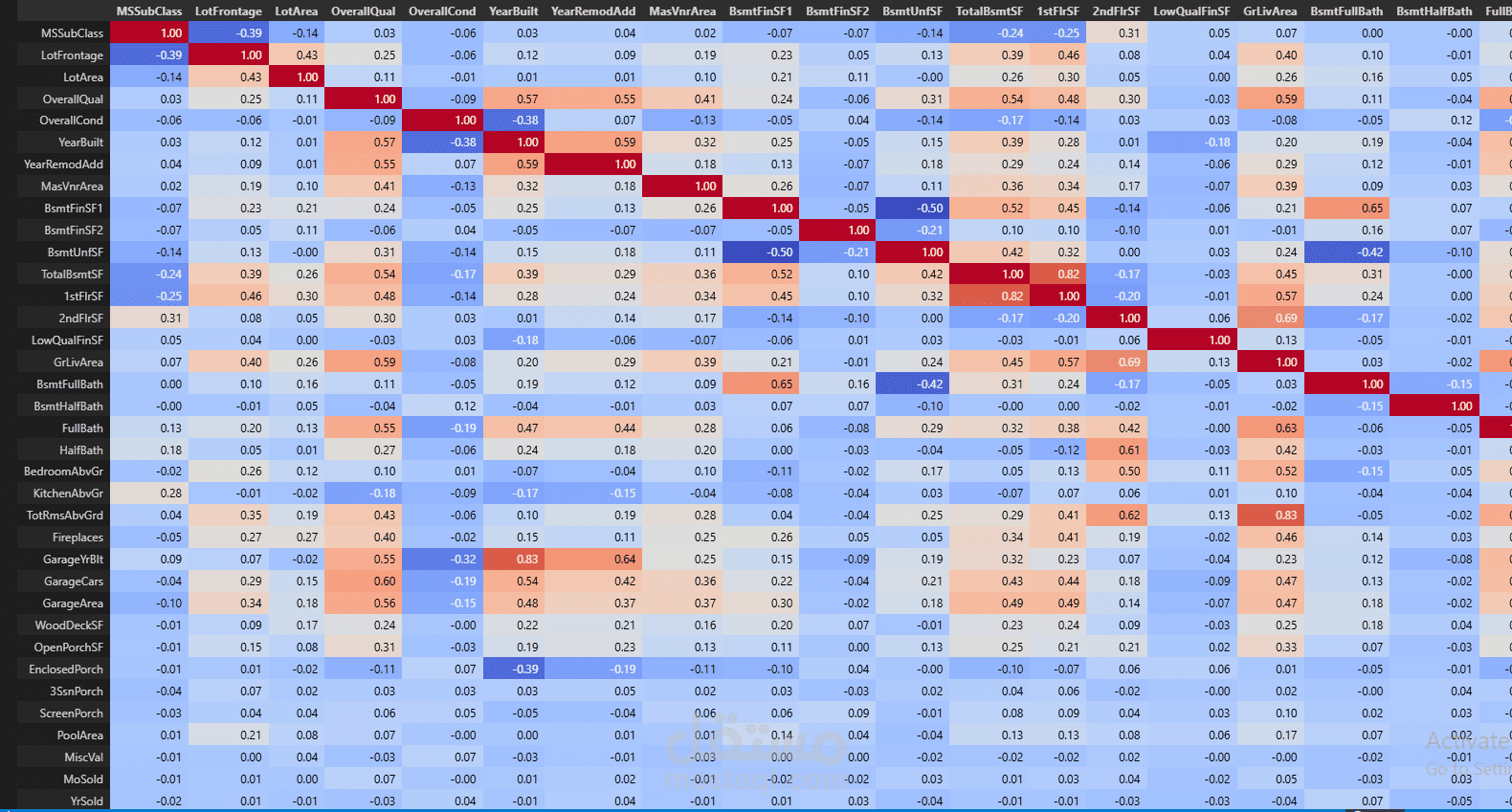
تحليل الارتباط (Correlation): حساب مصفوفة الارتباط بين المتغيرات الرقمية وسعر المنزل، وتقسيم قوة تأثير كل ميزة على السعر إلى فئات (قوي، متوسط، ضعيف)، وعرضها في جدول إحصائي ملون لتسهيل قراءتها.
2. بناء وتدريب نموذج XGBoost:
تقسيم البيانات: تقسيم مجموعة البيانات إلى قسمين: 70% للتدريب و 30% للاختبار.
التدريب: إعداد وتدريب نموذج XGBRegressor مع تفعيل خاصية التعامل المباشر مع البيانات الفئوية (Categorical Support)، باستخدام 1000 شجرة قرار ومعدل تعلم 0.05.
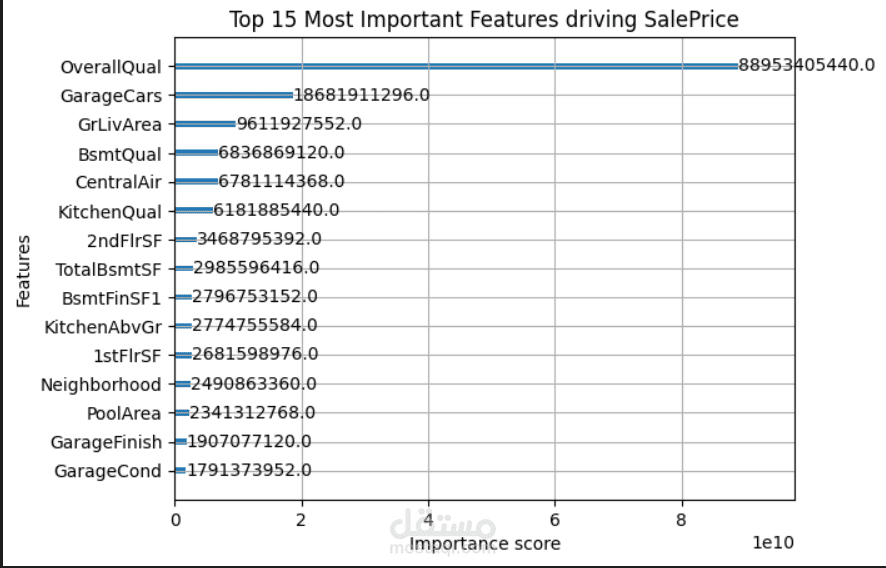
التقييم: حساب دقة النموذج على بيانات الاختبار باستخدام مقياس "جذر متوسط مربع الخطأ" (RMSE)، بالإضافة إلى استخراج ورسم أهم 15 ميزة (Feature Importance) مؤثرة في تحديد السعر النهائي للمنزل.
3. بناء وتدريب نموذج CatBoost:
تجهيز البيانات: ملء القيم المفقودة في الأعمدة الفئوية بكلمة "Missing" لكي يستطيع النموذج التعامل معها.
التدريب والتقييم: تدريب نموذج CatBoostRegressor لمقارنة أدائه مع أداء XGBoost، وتقييمه باستخدام مقياس (RMSE) للحصول على فكرة عن النموذج الأفضل.
4. تحضير ملف التسليم (Kaggle Submission):
معالجة بيانات الاختبار: تحميل ملف البيانات الجديدة test.csv، وحفظ عمود الـ Id جانباً، ثم توحيد أنواع البيانات (Dtypes) لتكون مطابقة تماماً لما تم في بيانات التدريب.
التوقع النهائي: استخدام نموذج XGBoost (والذي يبدو أنه تم اعتماده كالنموذج الأساسي) لتوقع أسعار المنازل في بيانات الاختبار.
التصدير: تجميع التوقعات النهائية وتصديرها في ملف جديد باسم submission_xgboost.csv جاهز للرفع على منصة Kaggle.