Customer Segmentation Analysis using K-Means and DBSCAN
تفاصيل العمل
الملف يتناول مشروعاً لتطبيق خوارزميات التجميع
(Clustering) على بيانات العملاء (Mall Customers). إليك ملخص لأهم ما جاء
فيه:
1. تحميل ومعالجة البيانات: يتم تحميل ملف Mall_Customers.csv والتعامل
مع القيم المفقودة، ثم تحويل البيانات النصية (مثل النوع) إلى أرقام،
واستخدام StandardScaler لتوحيد مقاييس البيانات.
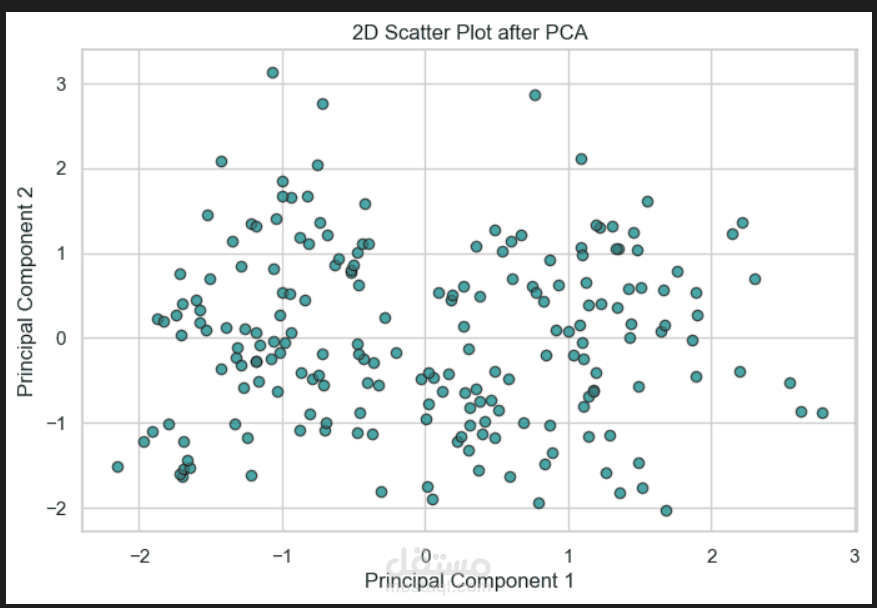
2. تقليل الأبعاد (PCA): استخدام تقنية تحليل المكونات الرئيسية (PCA)
لتقليل أبعاد البيانات إلى بُعدين فقط، مما يسمح برسمها وتصورها بوضوح
في شكل كروكي ثنائي الأبعاد.
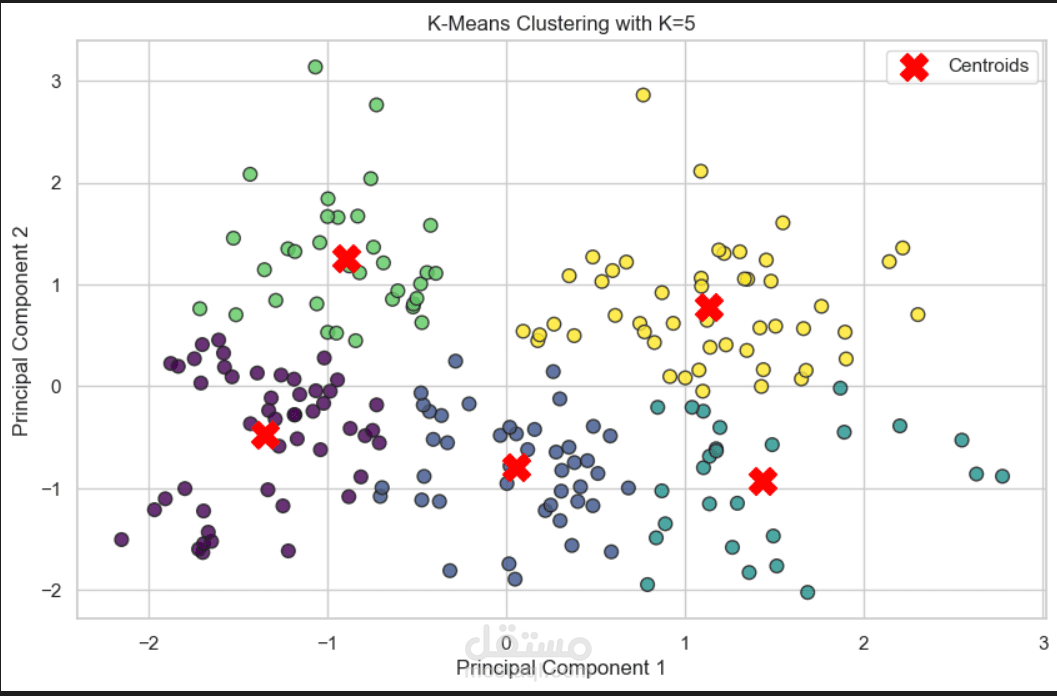
3. خوارزمية K-Means:
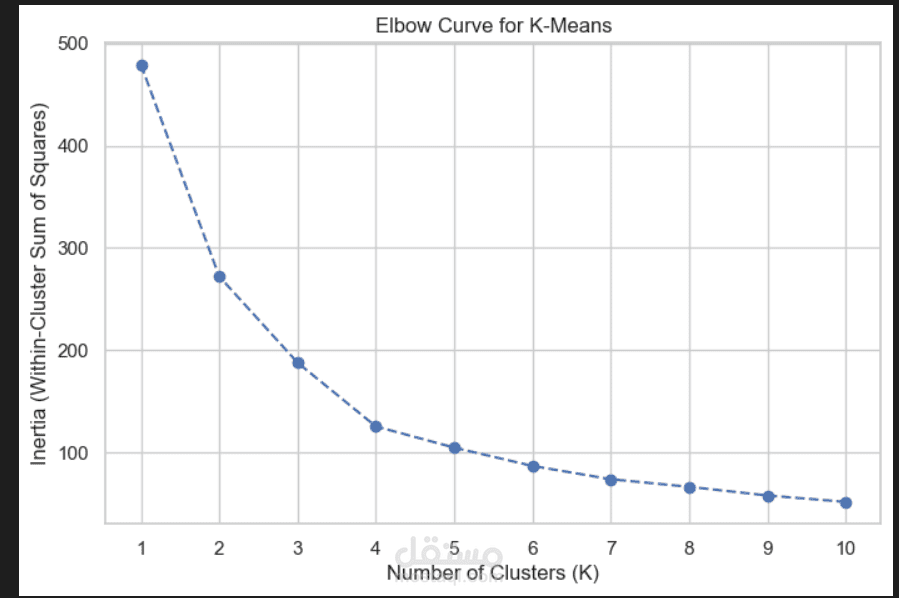
* رسم منحنى المرفق (Elbow Curve) لاختيار أفضل عدد للمجموعات ($K$)
عبر تجربة قيم من 1 إلى 10.
* تدريب النموذج باستخدام العدد الأمثل ($K=5$) وتحديد مراكز
المجموعات (Centroids).
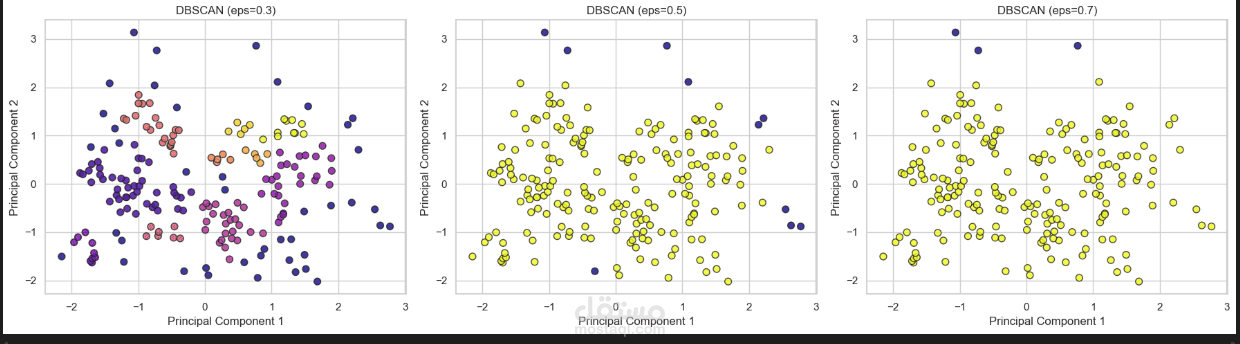
4. خوارزمية DBSCAN: تطبيق هذه الخوارزمية مع تجربة قيم مختلفة للمسافة
($eps$) للتعرف على المجموعات الكثيفة وتحديد نقاط الضوضاء أو
البيانات الشاذة (Noise points).
5. دالة التنبؤ (Recommendation Function): بناء وظيفة برمجية تأخذ
مواصفات العميل (النوع، العمر، الدخل السنوي، ومعدل الإنفاق) وتقوم
بمعالجتها بنفس الخطوات السابقة لتحدد آلياً المجموعة (Cluster ID)
التي ينتمي إليها هذا العميل.