Wazzuf web scraping
تفاصيل العمل
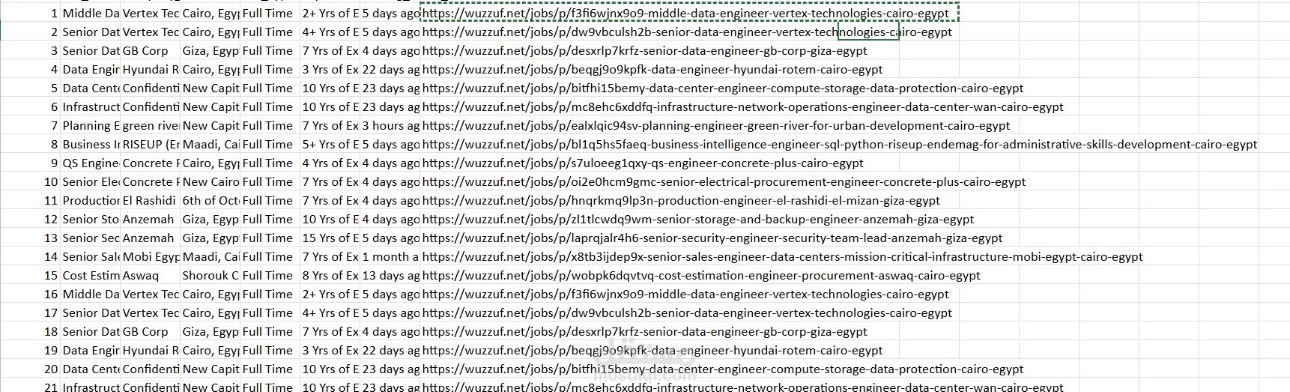

قمت بتطوير أداة متكاملة باستخدام لغة Python لاستخراج بيانات وظائف "هندسة البيانات" من منصة Wuzzuf بشكل آلي ودقيق. المشروع لا يقتصر فقط على سحب البيانات، بل يركز على معالجتها وتجهيزها لتكون صالحة للتحليل المباشر، مما يخدم مراحل الـ Data Pipeline الأولى في أي مشروع هندسة بيانات.
المميزات التقنية للمشروع:
• Dynamic Scraping: القدرة على التعامل مع الـ Pagination لسحب البيانات من صفحات متعددة بشكل متتالٍ دون توقف.
• Data Cleaning & Extraction: استخدام المكتبات المتقدمة مثل BeautifulSoup و Requests للوصول إلى محتوى الـ HTML واستخلاص المعلومات بدقة.
• Advanced Text Processing: توظيف الـ Regular Expressions (Regex) لاستخراج سنوات الخبرة المطلوبة وتنسيقها بشكل موحد (Standardized Format).
• Structured Storage: تحويل البيانات من صيغة غير منظمة إلى ملفات CSV منظمة باستخدام مكتبة Pandas، لضمان سهولة استيرادها في قواعد البيانات أو أدوات التحليل مثل Power BI.
الأدوات والتقنيات المستخدمة:
• Language: Python
• Libraries: BeautifulSoup, Requests, Pandas, Re (Regex)
• Environment: Jupyter Notebook / Scripting
قيمة المشروع المضافة:
يساعد هذا المشروع الشركات أو الباحثين في الحصول على "Big Data" محدثة لحظياً من سوق العمل، مع ضمان نظافة البيانات (Data Integrity) وجاهزيتها للاستخدام في اتخاذ القرارات أو بناء نماذج تنبؤية.