Breast Cancer Classification
تفاصيل العمل
تطوير نموذج تعلم آلي (Machine Learning) متقدم قادر على تصنيف أورام الثدي إلى (خبيثة أو حميدة) بدقة عالية. يعتمد المشروع على تحليل الخصائص السريرية للخلايا المستخلصة من الفحوصات، ويهدف إلى دعم اتخاذ القرار الطبي السريع والدقيق في مراحل التشخيص المبكر.
المهام التي قمت بتنفيذها:
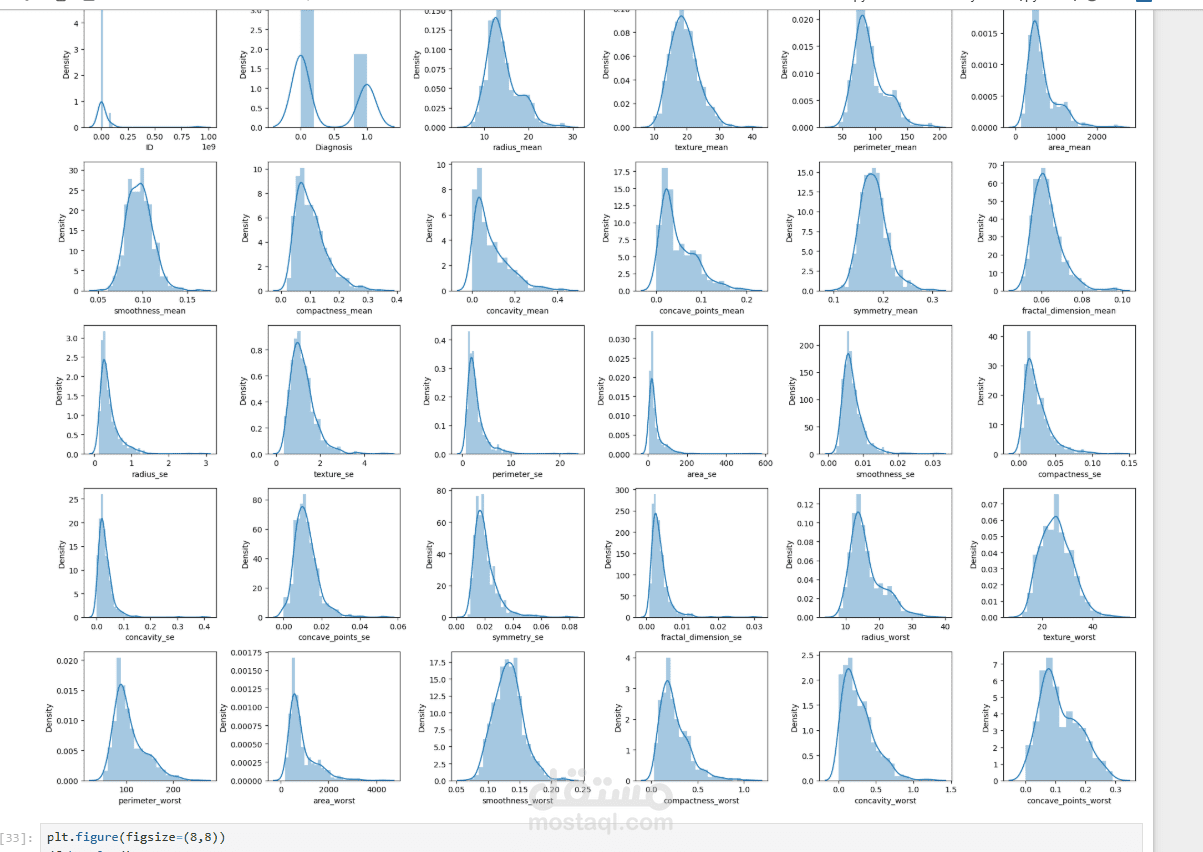
هندسة وتنظيف البيانات (Data Preprocessing): التعامل مع البيانات المفقودة، وتطبيع الميزات (Feature Scaling) لضمان عدم انحياز النموذج لمتغير دون الآخر.
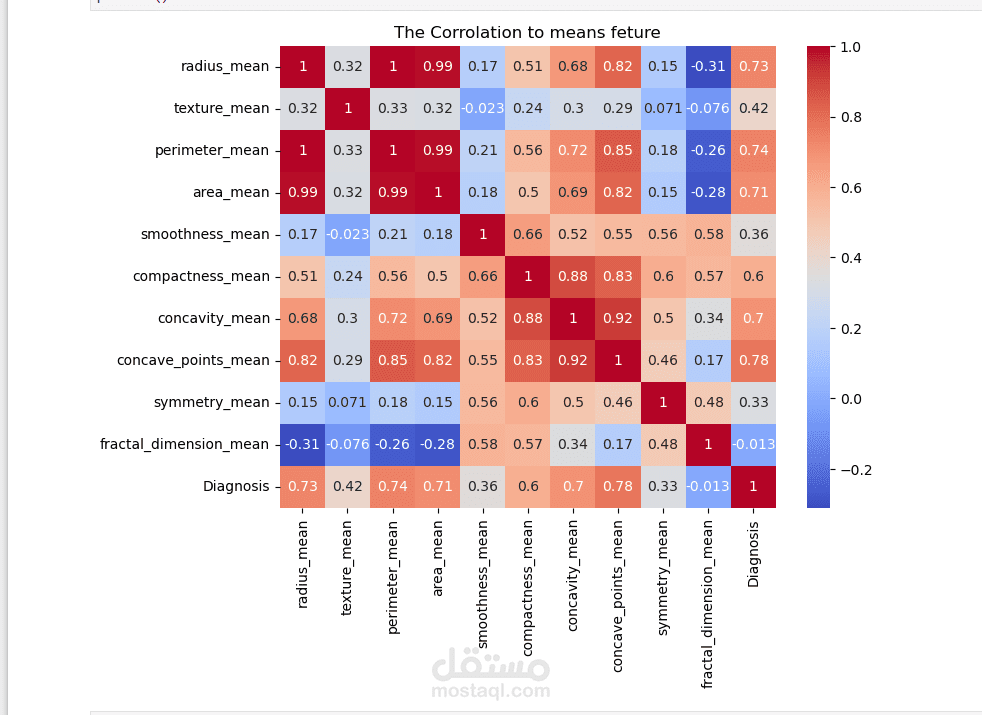
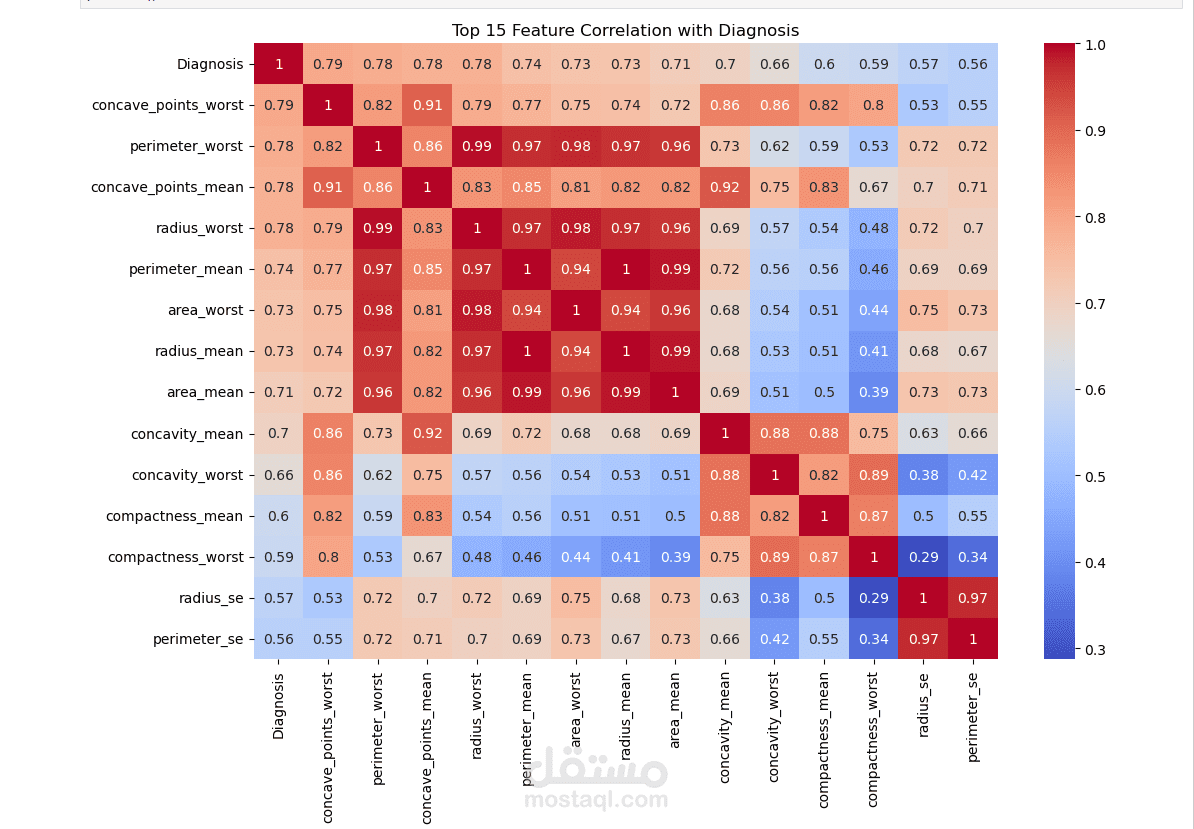
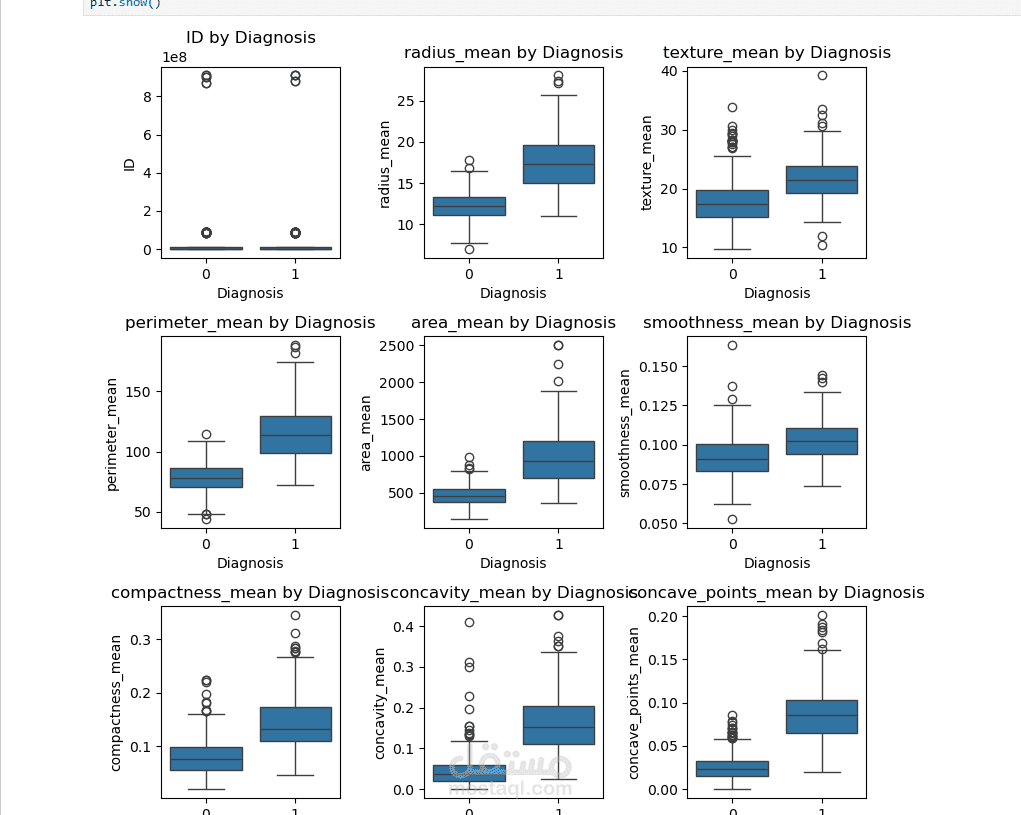
التحليل الإحصائي (Statistical Analysis): دراسة الارتباط بين الخصائص الفيزيائية للخلايا (مثل نصف القطر، الملمس، والمساحة) وتأثيرها على نوع الورم.
بناء واختيار النماذج (Model Selection): مقارنة أداء عدة خوارزميات تصنيف مثل (Random Forest, SVM, XGBoost) لاختيار النموذج الأكثر استقراراً ودقة.
التحسين الفائق (Hyperparameter Tuning): ضبط معايير النموذج للوصول إلى أفضل أداء ممكن وتقليل نسبة الخطأ.
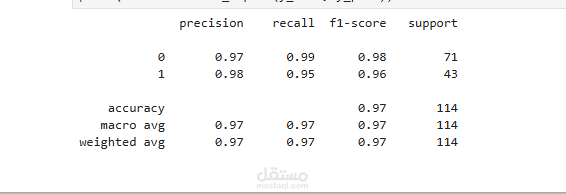
تقييم النموذج (Evaluation Metrics): التركيز على مقاييس الـ Recall و F1-Score لضمان أقل نسبة ممكنة من "النتائج السلبية الكاذبة" (False Negatives)، وهو أمر حيوي في التطبيقات الطبية.
الأدوات والتقنيات المستخدمة:
لغة البرمجة: Python.
المكتبات التقنية: Scikit-learn لتدريب النماذج، Pandas و NumPy لمعالجة البيانات.
تصوير البيانات: Seaborn و Matplotlib لتحليل مصفوفة الارتباك (Confusion Matrix) ومنحنيات الـ ROC.
النتائج المحققة:
تحقيق نموذج تصنيف بدقة تصل إلى [اكتبي النسبة التي حققتِها، مثلاً 98%].
بناء نظام قادر على تحديد الأنماط الخفية في البيانات الطبية التي قد يصعب ملاحظتها يدوياً.
توفير تقرير فني يوضح العوامل الأكثر تأثيراً في تحديد نوع الورم، مما يساعد الأطباء في فهم مسببات القرار الآلي.