مكتبة WebScraping using Scrapy & BS4
تفاصيل العمل
لأدوات المستخدمة: Requests, BeautifulSoup, Scrapy, Pandas.
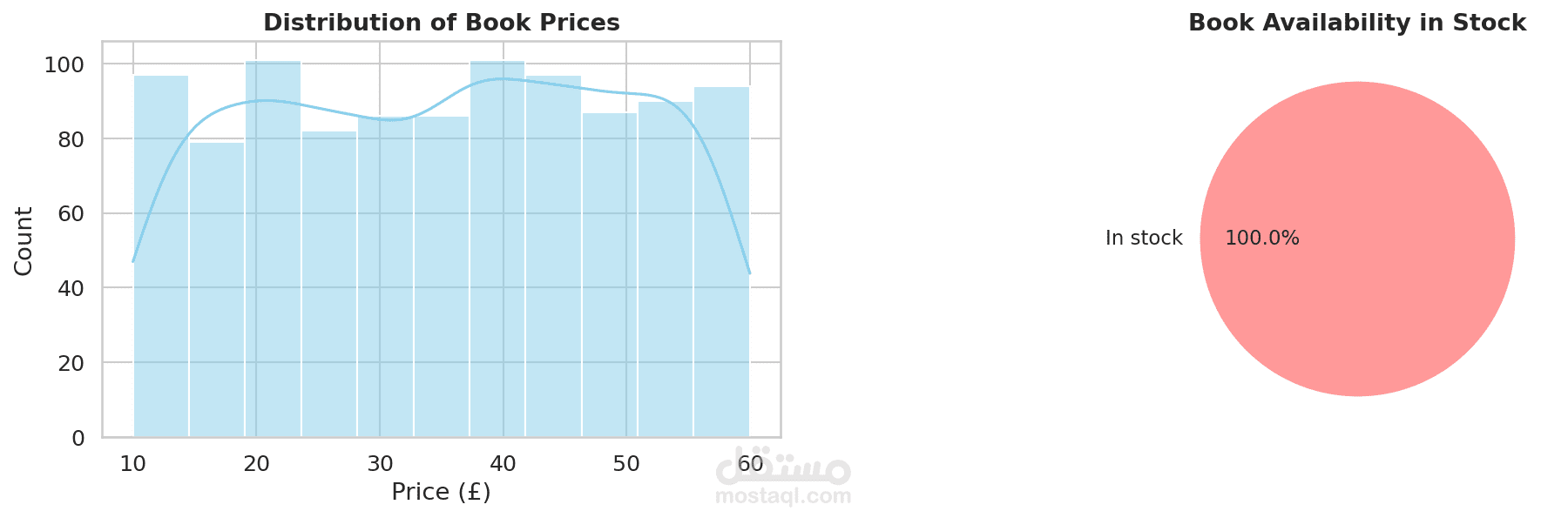
الهدف من المشروع: جمع بيانات ضخمة بشكل آلي من موقع ويب (تتضمن اسم الكتاب، السعر، وحالة التوفر) وحفظها في صيغة CSV للتحليل اللاحق.
أداة آلية وقوية لاستخراج بيانات الويب (Web Scraping) صُممت لجمع بيانات الكتالوجات الضخمة من المتاجر الإلكترونية. باستخدام نهج مزدوج يجمع بين BeautifulSoup لتحليل صفحات HTML وإطار عمل Scrapy للزحف السريع والقابل للتوسع، ينجح المشروع في حصد تفاصيل شاملة مثل عناوين الكتب، الوصف، الأسعار، وحالة التوفر في المخزون. يتم تنظيف البيانات المستخرجة وتصديرها بتنسيق CSV مهيكل، لتكون جاهزة تماماً للتحليل الاستكشافي للبيانات (EDA) أو إدراجها في قواعد البيانات.