Machine Learning Project -Housing Price Prediction Regression Models Evaluation
تفاصيل العمل


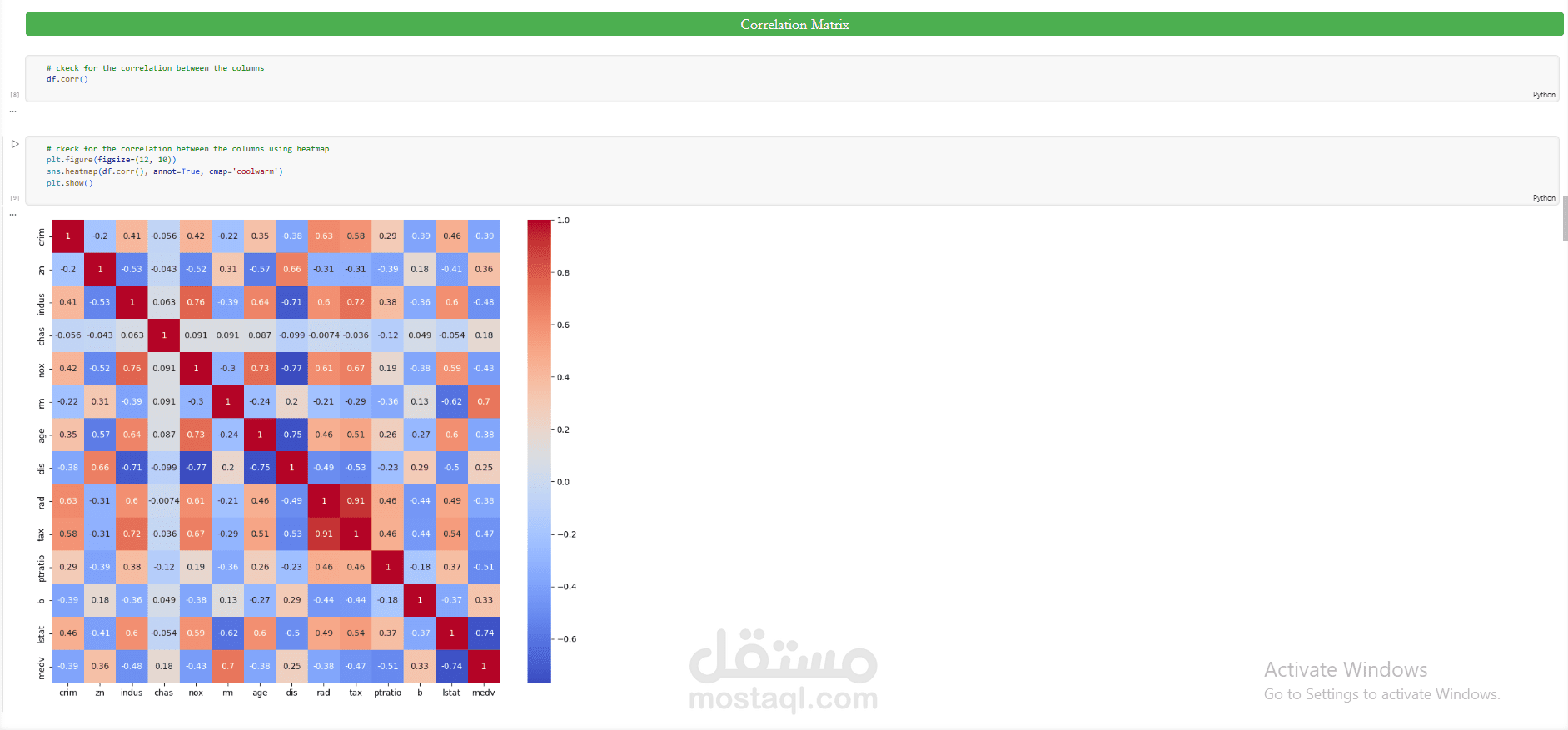



يتناول هذا المشروع بناء end-to-end Machine Learning pipeline للتنبؤ بأسعار المساكن (house price prediction) باستخدام tabular dataset يحتوي على 13 features تمثل خصائص بيئية واقتصادية للمناطق السكنية، مثل معدل الجريمة (crim)، نسبة الأراضي السكنية (zn)، نسبة الأنشطة غير التجارية (indus)، تركيز أكسيد النيتروجين (nox)، متوسط عدد الغرف (rm)، ومعدل الضرائب العقارية (tax). بينما يمثل المتغير الهدف (target variable) القيمة المتوسطة للمنازل (medv).
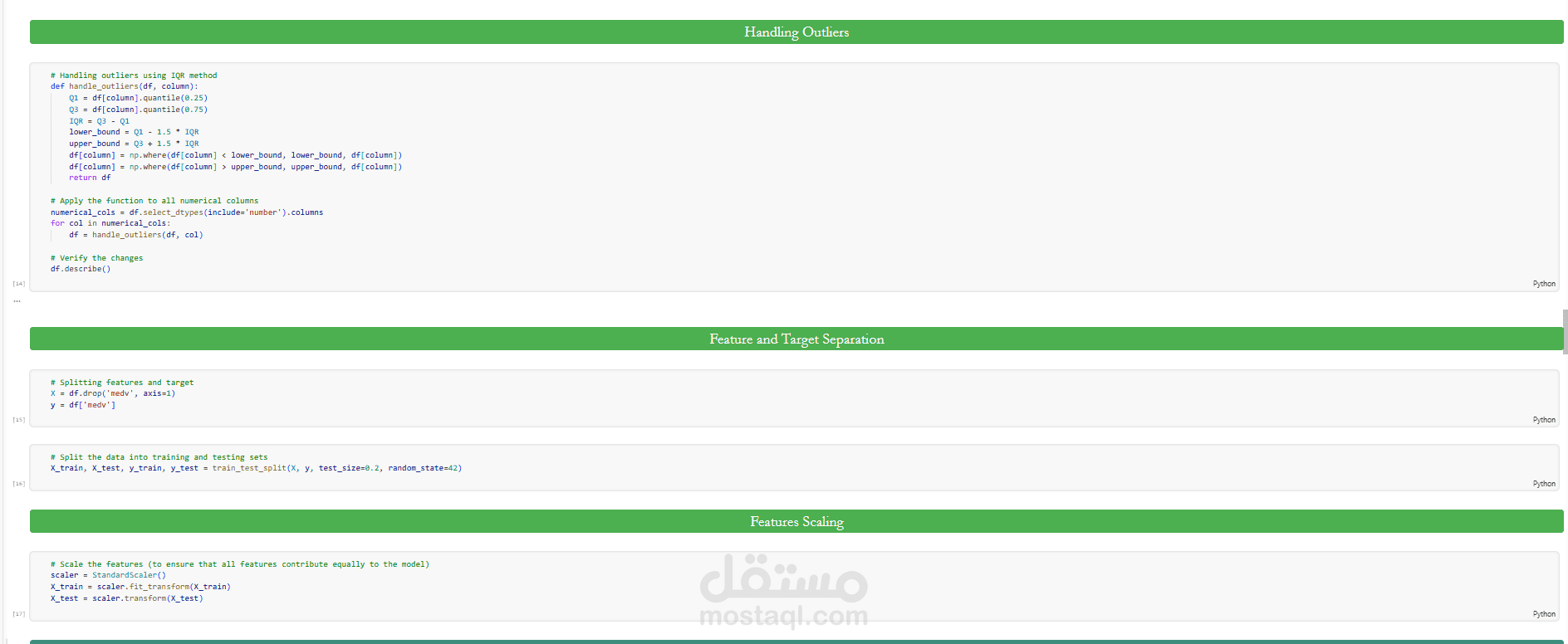
تم تنفيذ المشروع وفق منهجية Data Science workflow تبدأ بمرحلة Exploratory Data Analysis (EDA) بهدف فهم توزيع البيانات، تحليل العلاقات بين المتغيرات، واكتشاف الأنماط الإحصائية داخل البيانات. ثم مرحلة Data Preprocessing والتي شملت معالجة القيم المفقودة، التعامل مع outliers، وتطبيق feature scaling (Normalization & Standardization) لضمان تحسين أداء النماذج.
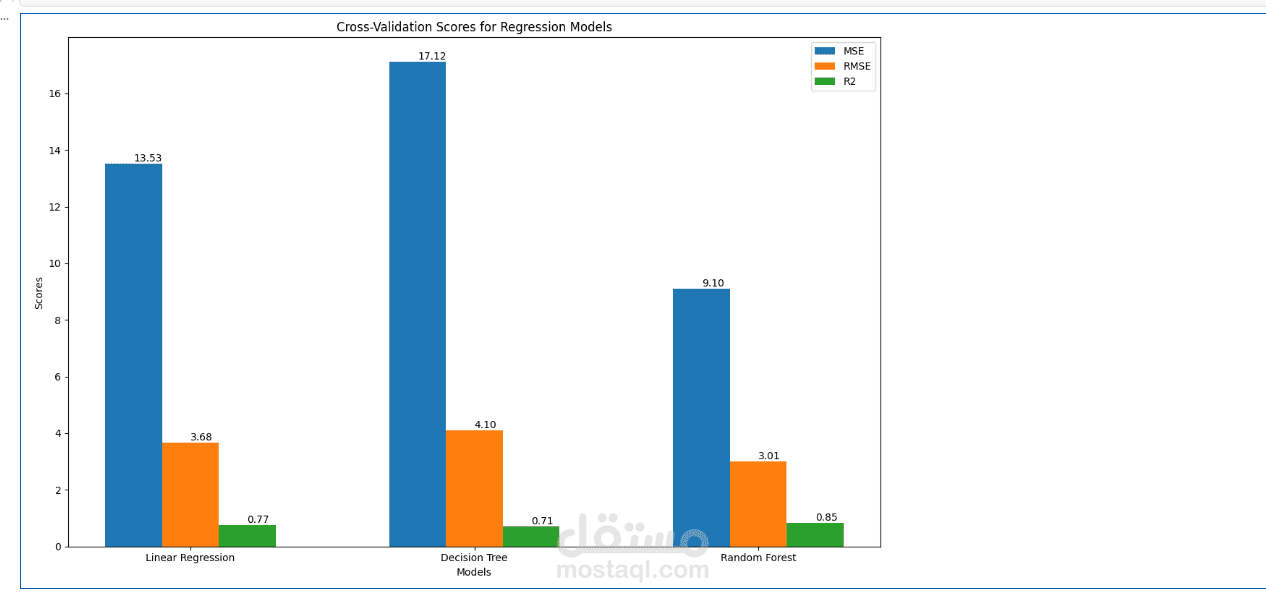
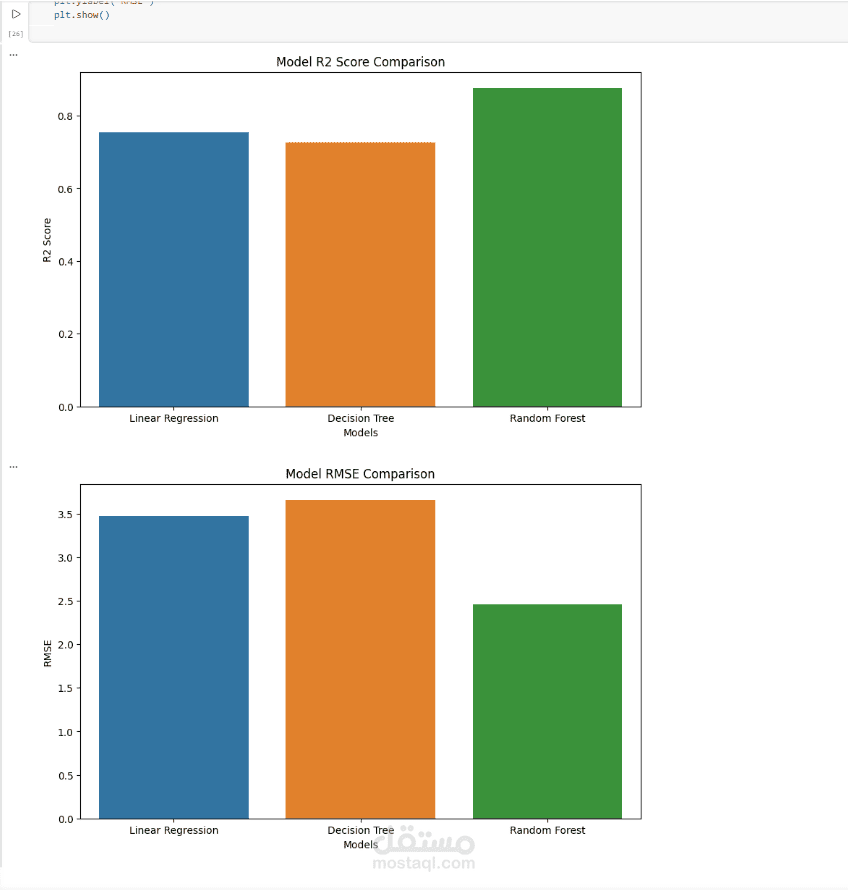
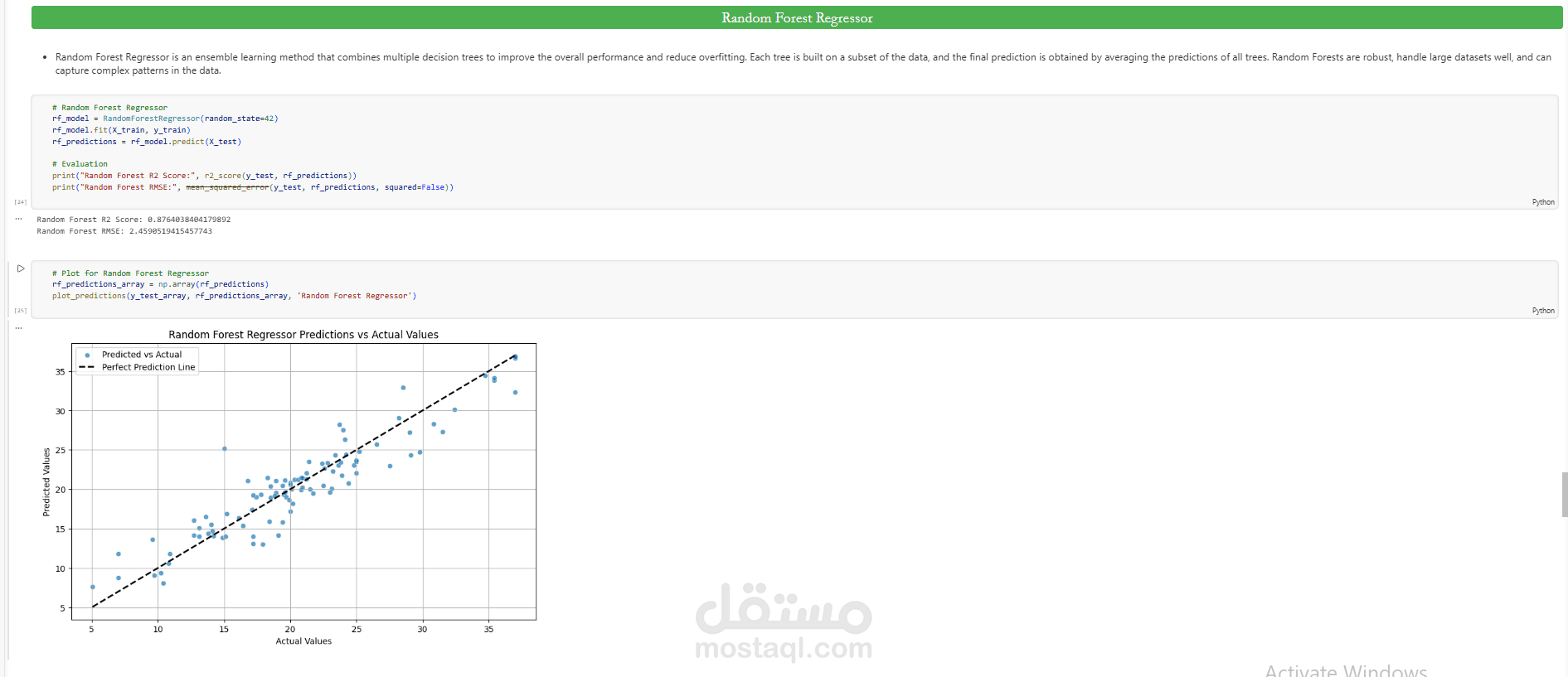
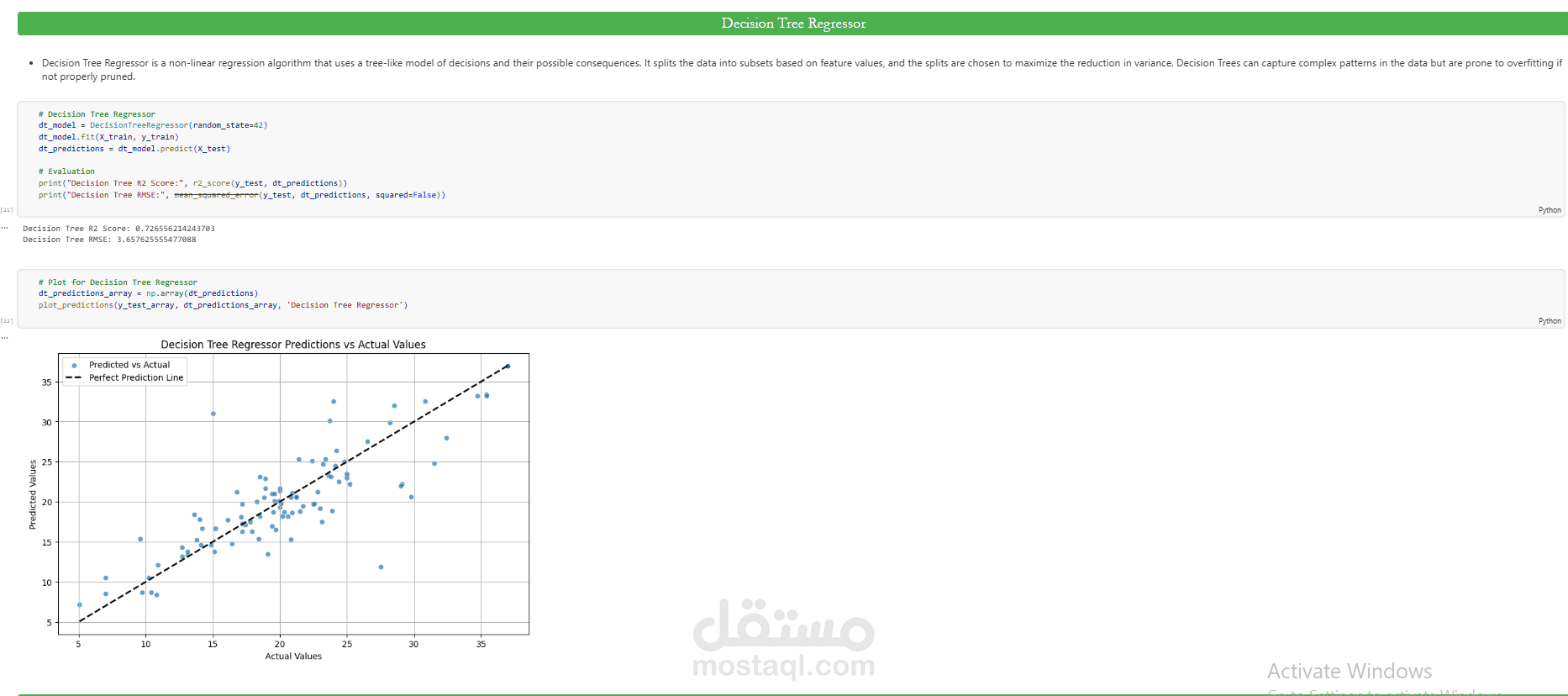
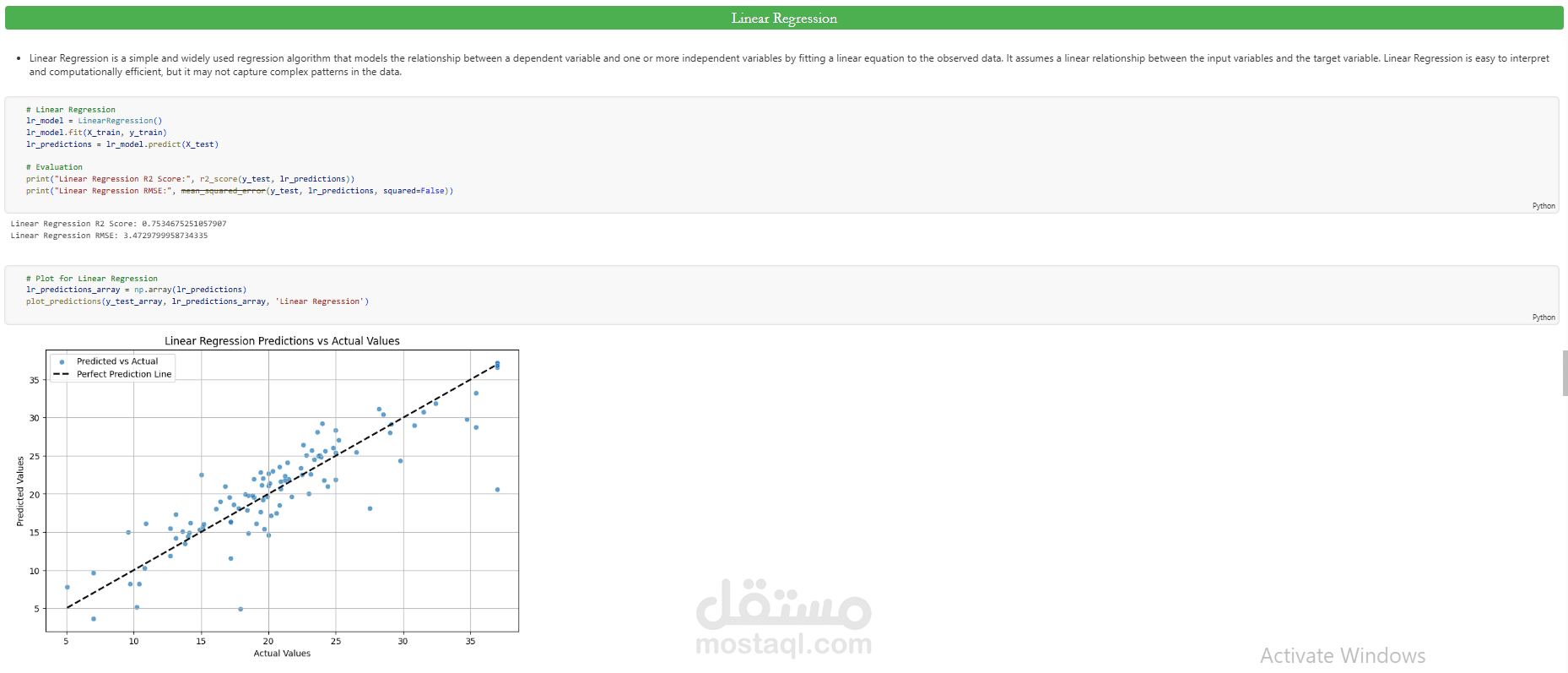
بعد ذلك تم تدريب عدة supervised learning regression models مثل Linear Regression وDecision Tree Regressor وRandom Forest Regressor بهدف إجراء model comparison واختيار أفضل أداء.
تم تقييم النماذج باستخدام regression evaluation metrics مثل Mean Squared Error (MSE) وRoot Mean Squared Error (RMSE) وR² Score، مع تطبيق Cross-Validation لضمان model robustness وقياس قدرة النموذج على التعميم (generalization).
في النهاية تم تحليل feature importance لاستخلاص أهم العوامل المؤثرة في أسعار المنازل، وتقديم insights تساعد في فهم ديناميكيات السوق العقاري، بالإضافة إلى اقتراح تحسينات مستقبلية مثل hyperparameter tuning وfeature engineering لرفع دقة النماذج.