MLops House Prediction Price
تفاصيل العمل
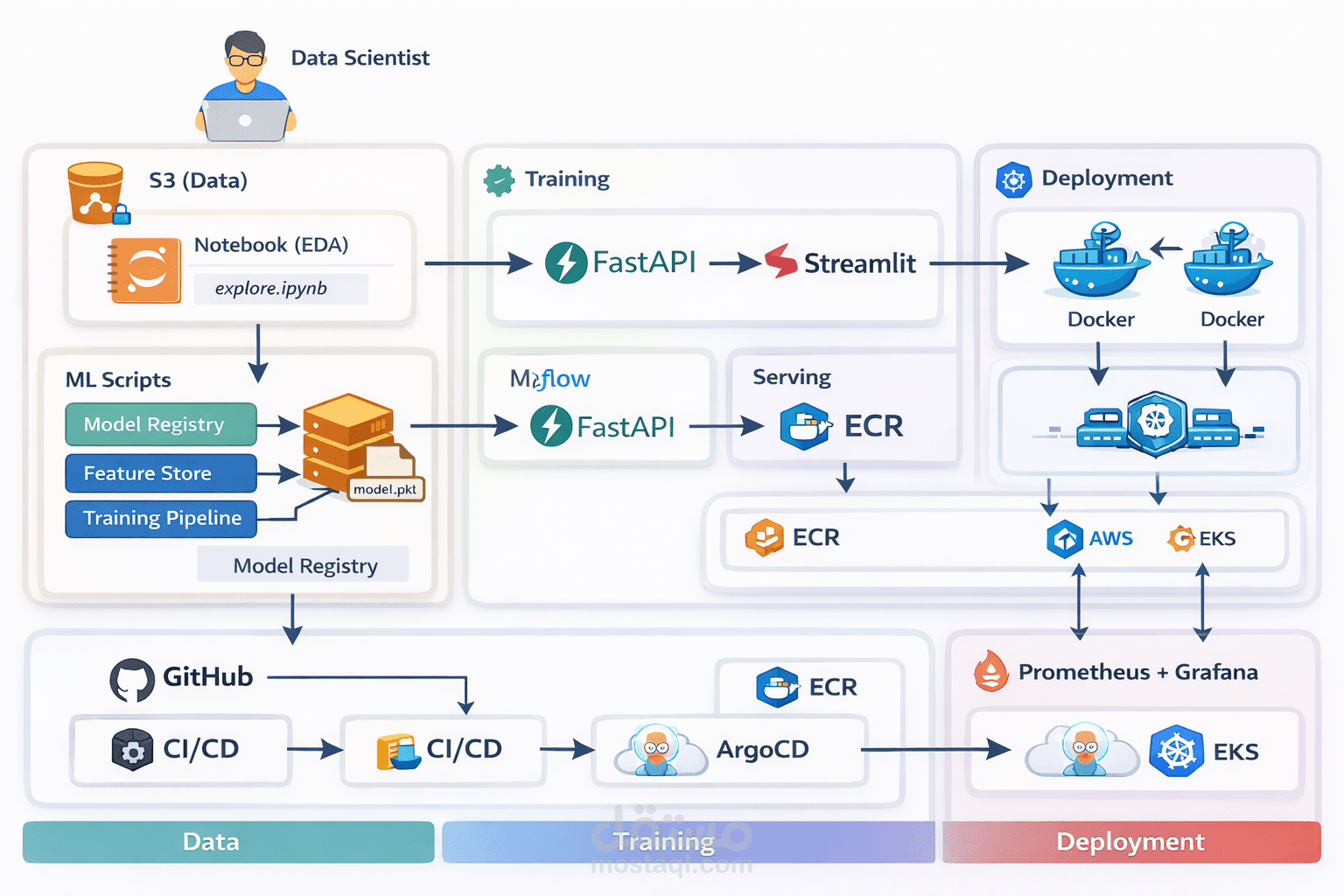
? Project Description
This project demonstrates a production-ready MLOps pipeline that integrates data processing, model training, versioning, deployment, and monitoring using modern cloud-native tools.
? 1. Data Layer (Storage & Exploration)
Data is stored in Amazon S3.
A data scientist performs EDA (Exploratory Data Analysis) using Jupyter notebooks (explore.ipynb).
This stage ensures data understanding and preprocessing before training.
? 2. Machine Learning Pipeline
ML scripts handle:
Feature Engineering (Feature Store)
Model Training Pipeline
Model Versioning (Model Registry)
The trained model is saved as an artifact (e.g., model.pkl).
? 3. Experiment Tracking & Serving
MLflow is used for:
Experiment tracking
Model version control
FastAPI is used to expose the model as an API for inference.
? 4. Application Layer
Streamlit provides a simple UI for interacting with the model.
Users can input data and get predictions through a web interface.
? 5. Containerization & Registry
Applications are containerized using Docker.
Images are stored in Amazon ECR.
? 6. CI/CD & GitOps
Source code is managed in GitHub.
CI/CD pipelines automate:
Build
Test
Deployment
Argo CD is used for GitOps-based deployment.
? 7. Deployment (Cloud Infrastructure)
The application is deployed on Amazon EKS.
Kubernetes ensures:
Scalability
High availability
Container orchestration
? 8. Monitoring & Observability
Prometheus collects metrics.
Grafana visualizes performance dashboards.
This ensures system health and model performance tracking.
? Overall Flow
Data → stored in S3 → analyzed in notebooks
Training pipeline → model saved & tracked in MLflow
Model → served via FastAPI → UI via Streamlit
Docker images → pushed to ECR
CI/CD → deployed via ArgoCD to EKS
Monitoring → Prometheus & Grafana
? Key Value
This project showcases:
End-to-end MLOps lifecycle
Cloud-native deployment on AWS
Automation using CI/CD + GitOps
Scalable and production-grade architecture