Automated Book Catalog Scraper
تفاصيل العمل
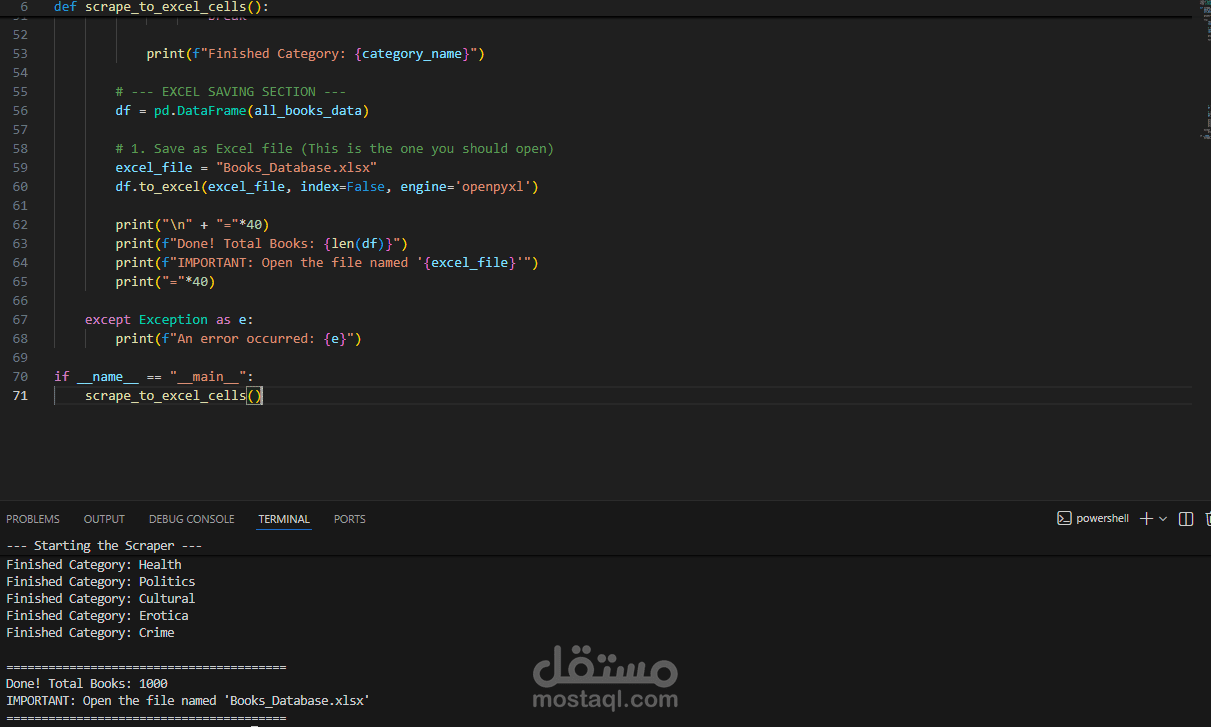
? Overview
An end-to-end Web Scraping tool developed in Python to extract a comprehensive dataset from the Books to Scrape website. The scraper automates the collection of information for over 1,000 books across 50 different categories, converting unstructured HTML data into a clean, structured Excel/CSV database.
? Key Features
Full Catalog Extraction: Scrapes all 1,000 books by dynamically navigating through 50 different category pages.
Deep Pagination Handling: Implemented a logic to follow "Next" buttons, ensuring 100% data coverage even for categories spanning multiple pages.
Data Points Collected:
Book Title (Full titles extracted from HTML attributes).
Category (Categorized according to the website’s taxonomy).
Price (Cleaned and converted to numerical format).
Star Rating (Parsed from CSS class names).
Availability Status (Cleaned text).
Professional Export: Data is processed using Pandas and exported into a formatted Excel (.xlsx) file with proper columns and rows for immediate analysis.
?️ Tech Stack
Python: The core programming language.
BeautifulSoup4: For parsing and navigating the HTML tree.
Requests: For handling HTTP protocols.
Pandas: For data structuring and cleaning.
Openpyxl: To generate native Excel files.
? Key Challenges & Solutions
Challenge: The website uses relative URLs for pagination which can break the scraper.
Solution: Used urllib.parse.urljoin to ensure robust and absolute URL generation.
Challenge: Large data spread across many pages.
Solution: Optimized the script with nested loops to iterate through categories and pages systematically.