تحليل بيانات البنوك و نسبة حصول الفرد علي قرض و سداده
تفاصيل العمل

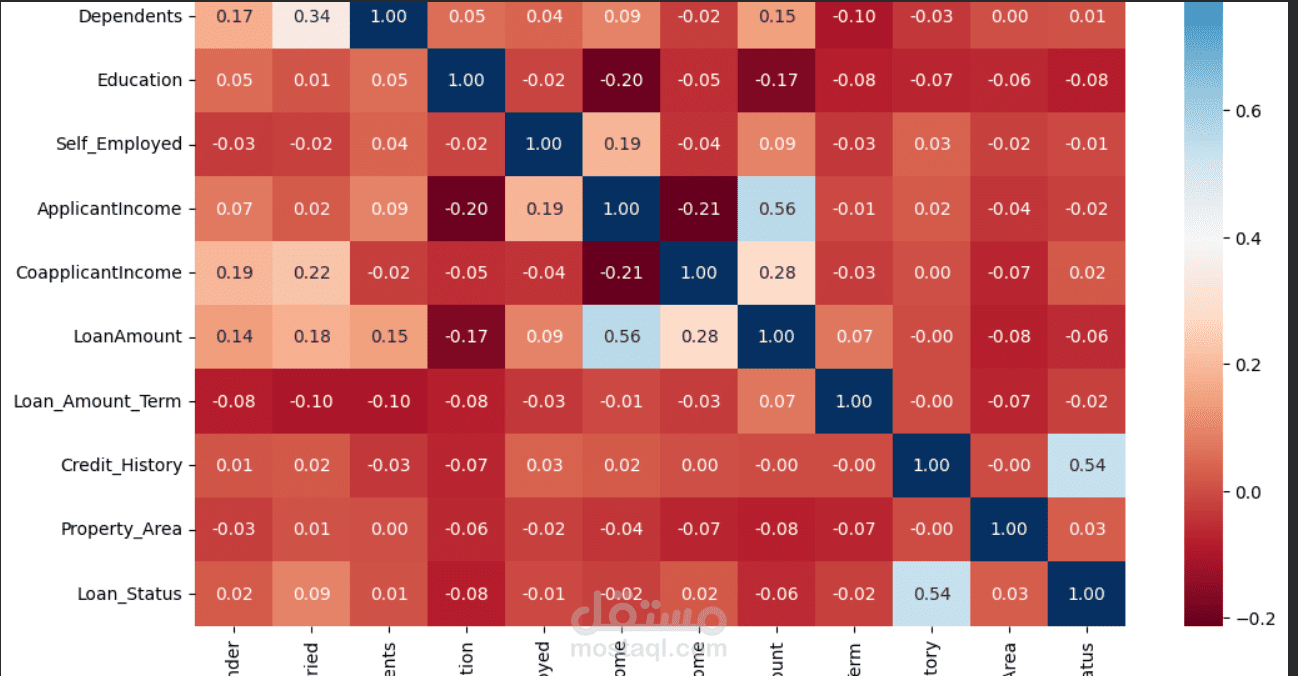
يهدف المشروع إلى استكشاف وتحليل العوامل التي تؤثر على قرارات الموافقة على القروض البنكية، وتجهيز البيانات (Preprocessing) لاستخدامها لاحقاً في نماذج الذكاء الاصطناعي للتنبؤ بما إذا كان العميل سيحصل على القرض أم لا.
2. محتويات الملف والخطوات المنفذة
بناءً على الكود المكتوب، تم تنفيذ المراحل التالية:
استيراد المكتبات الأساسية: تم استخدام مكتبات pandas و numpy لمعالجة البيانات، و matplotlib و seaborn للرسم البياني، ومكتبة sklearn لتحويل البيانات.
تحميل البيانات: تم استيراد ملف البيانات بصيغة CSV باسم LoanApprovalPrediction.csv.
التحليل البصري للمتغيرات الفئوية (Categorical Analysis):
قام الكود بإنشاء رسوم بيانية (Countplots) لخمسة متغيرات أساسية هي: الجنس (Gender)، الحالة الاجتماعية (Married)، التعليم (Education)، منطقة العقار (Property_Area)، وحالة القرض (Loan_Status).
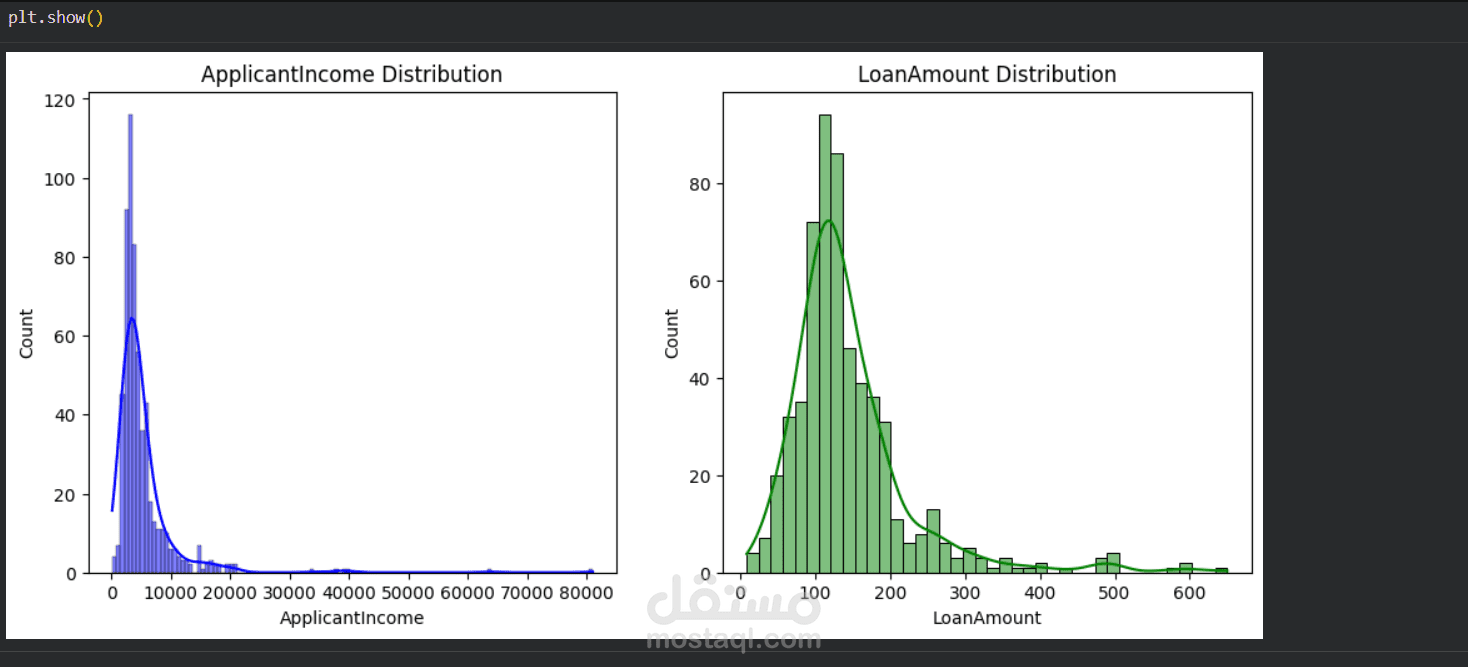
تحليل التوزيعات العددية (Numerical Analysis):
استخدام الرسوم البيانية التكرارية (Histograms) مع منحنى الكثافة (KDE) لتحليل توزيع دخل المتقدم (ApplicantIncome) ومبلغ القرض (LoanAmount).
معالجة البيانات (Data Cleaning & Preprocessing):
حذف التكرار: تنظيف البيانات من أي سجلات مكررة.
معالجة القيم المفقودة (Null Values):
تم ملء القيم المفقودة في المتغيرات الفئوية باستخدام "القيمة الأكثر تكراراً" (Mode).
تم ملء القيم المفقودة في مبالغ القروض ومدة القرض باستخدام "الوسيط" (Median).
معالجة القيم الشاذة (Outliers): تم تطبيق دالة لتقليل تأثير القيم المتطرفة في الدخل ومبالغ القروض باستخدام طريقة المدى الربيعي (IQR) لضمان دقة التحليل.
الترميز الرقمي (Label Encoding):
تم تحويل النصوص (مثل "ذكر/أنثى" أو "متزوج/أعزب") إلى أرقام (0 و 1...) باستخدام LabelEncoder لتكون صالحة للعمليات الحسابية والبرمجية.
3. ملخص للمديرين (لماذا هذا الملف مهم؟)
تحسين جودة البيانات: الكود يضمن أن البيانات "نظيفة" تماماً من القيم المفقودة والشاذة قبل البدء في أي قرار.
فهم العميل: الرسوم البيانية توضح من هم الفئات الأكثر طلباً للقروض وما هي مستويات دخولهم.
جاهزية النمذجة: بنهاية هذا الملف، تصبح البيانات جاهزة تماماً لإدخالها في نموذج تنبؤ آلي يساعد البنك في اتخاذ قرارات ائتمانية أسرع وأدق.