Amazon Product Analytics & Rating
تفاصيل العمل
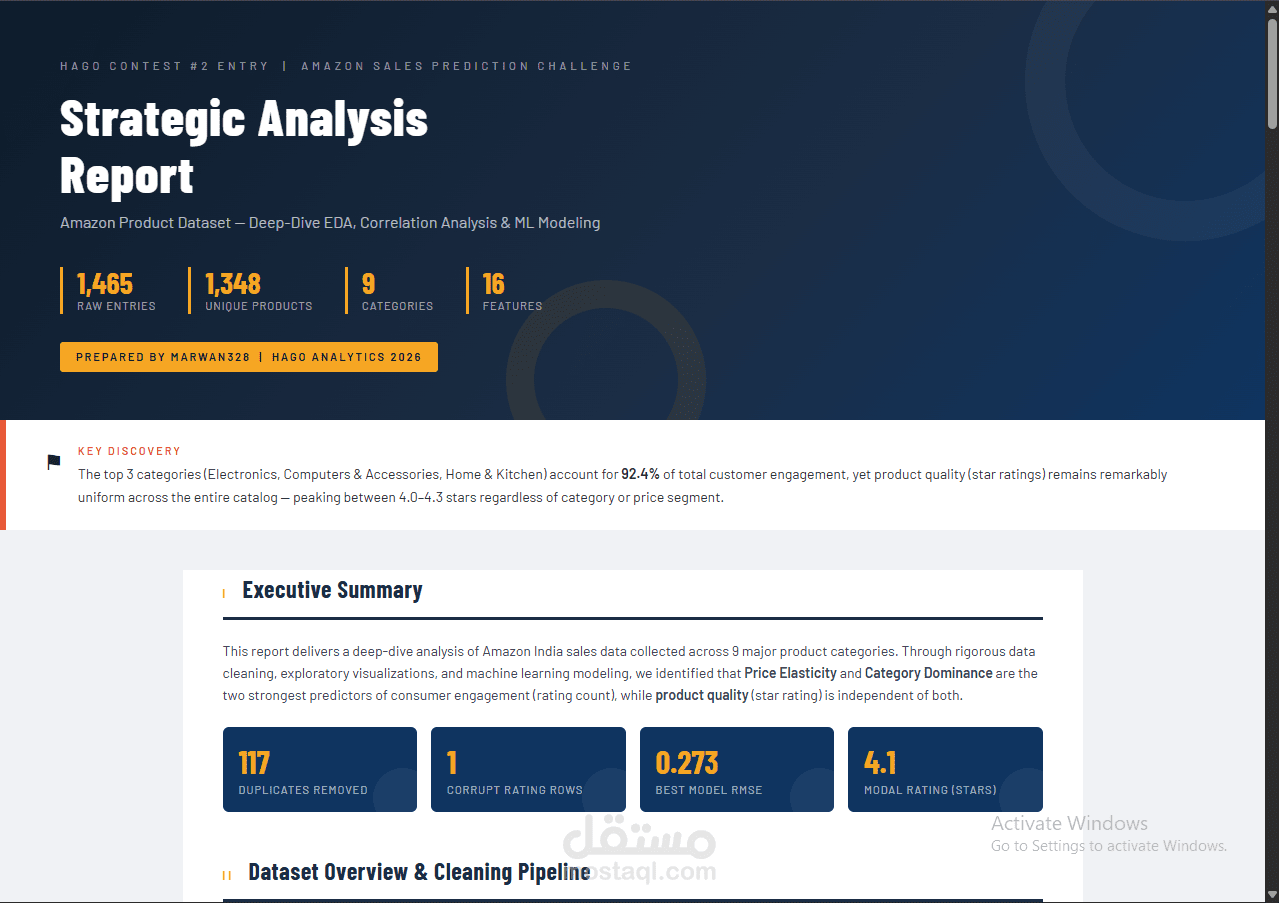
Built an end-to-end data science project analyzing Amazon product data and predicting product ratings using machine learning and NLP techniques.
Key contributions:
- Cleaned and preprocessed real-world dataset (handled missing values, duplicates, and inconsistent data types)
- Engineered meaningful features including pricing metrics, review statistics, and category encoding
- Applied TF-IDF vectorization on combined textual data (reviews, titles, product descriptions)
- Trained and compared multiple models, with Random Forest achieving RMSE ≈ 0.273
- Performed feature importance analysis to interpret model behavior
- Created visualizations to extract business insights from data
Technologies used:
Python, Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn
Impact:
Demonstrates ability to handle structured + unstructured data, build predictive models, and extract actionable insights for business use cases such as recommendation systems and pricing optimization.