نظام تصنيف الإيميلات (Spam vs Ham) باستخدام التعلم الآلي ومعالجة اللغة الطبيعية
تفاصيل العمل
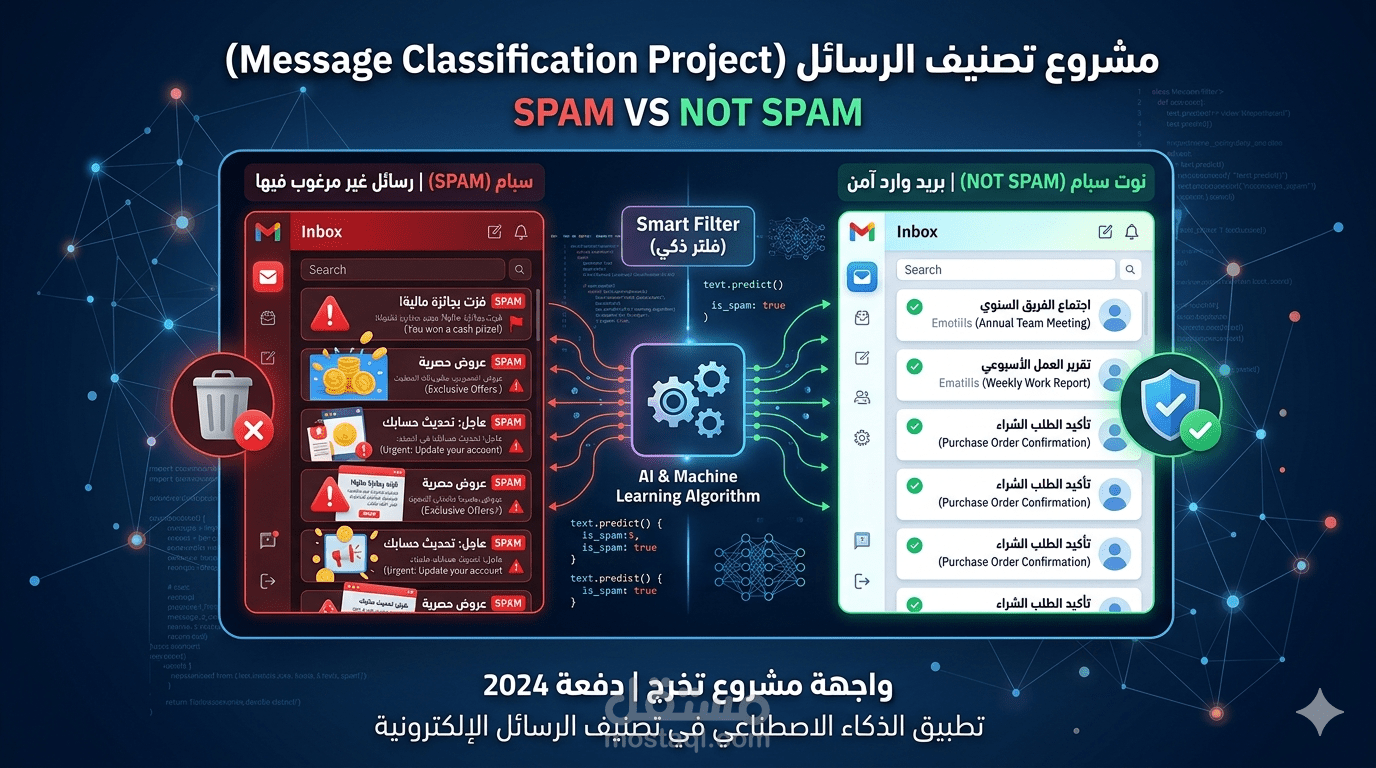
قمت بتطوير نموذج ذكي لتصنيف الإيميلات إلى سبام أو هام (غير سبام) باستخدام مجموعة بيانات Enron Spam Dataset الشهيرة والتي تحتوي على أكثر من 33,000 إيميل.
مميزات المشروع:
- دمج عمودي Subject + Message للحصول على أفضل تمثيل للإيميل.
- تنظيف ومعالجة النصوص باستخدام NLTK (Lowercase, Tokenization, Stopwords Removal, Lemmatization).
- تحويل النصوص إلى أرقام باستخدام **TF-IDF Vectorizer** (5000 feature).
- تجربة 4نماذج مختلفة للمقارنة
- SVM
- Logistic Regression
- Random Forest
- Naive Bayes
- تقييم النماذج باستخدام Accuracy و Classification Report.
- دالة تنبؤ جاهزة لتصنيف أي إيميل جديد.
المشروع ساعدني أتعمق أكثر في مجال معالجة اللغة الطبيعية وكيفية بناء نماذج تصنيف نصوص فعالة.