Data Pipeline لاكتشاف الاحتيال باستخدام Apache Spark
تفاصيل العمل
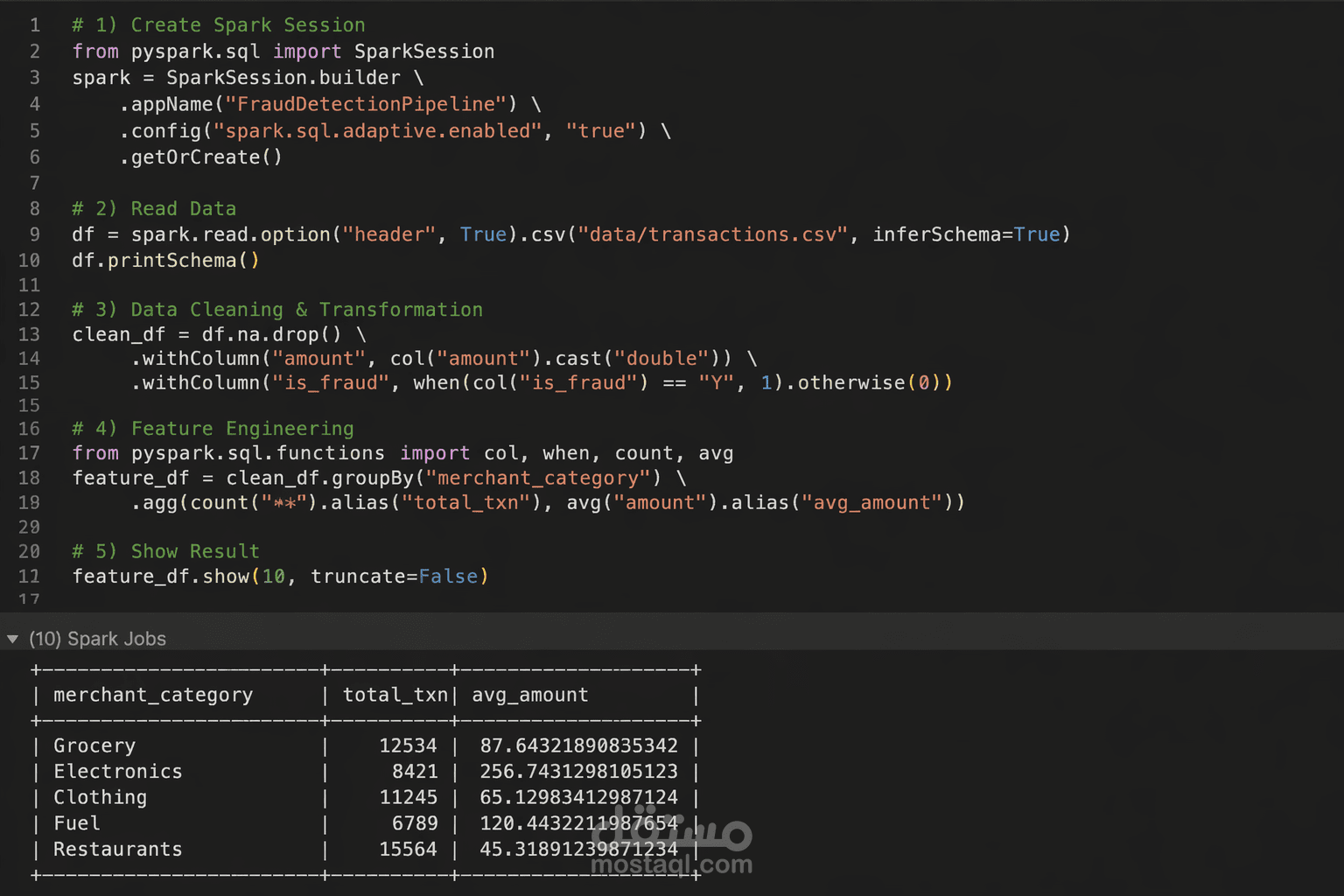
قمت بتصميم وتنفيذ Data Pipeline لمعالجة وتحليل بيانات المعاملات المالية بهدف اكتشاف العمليات الاحتيالية باستخدام تقنيات Big Data.
اعتمدت على Apache Spark لمعالجة البيانات بكفاءة عالية، حيث قمت بتنفيذ عمليات تنظيف البيانات (Data Cleaning) وتحويلها (Transformation) واستخراج الخصائص المهمة (Feature Engineering).
تم تصميم النظام ليكون قابل للتوسع (Scalable) وقادر على التعامل مع كميات كبيرة من البيانات.
مميزات المشروع:
معالجة بيانات ضخمة (Batch Processing)
تحليل الأنماط غير الطبيعية (Fraud Detection)
تحسين الأداء باستخدام Spark
تصميم Pipeline احترافية
الأدوات المستخدمة:
Python
Apache Spark
SQL