"Car Price Analysis: Regression & Classification"
تفاصيل العمل
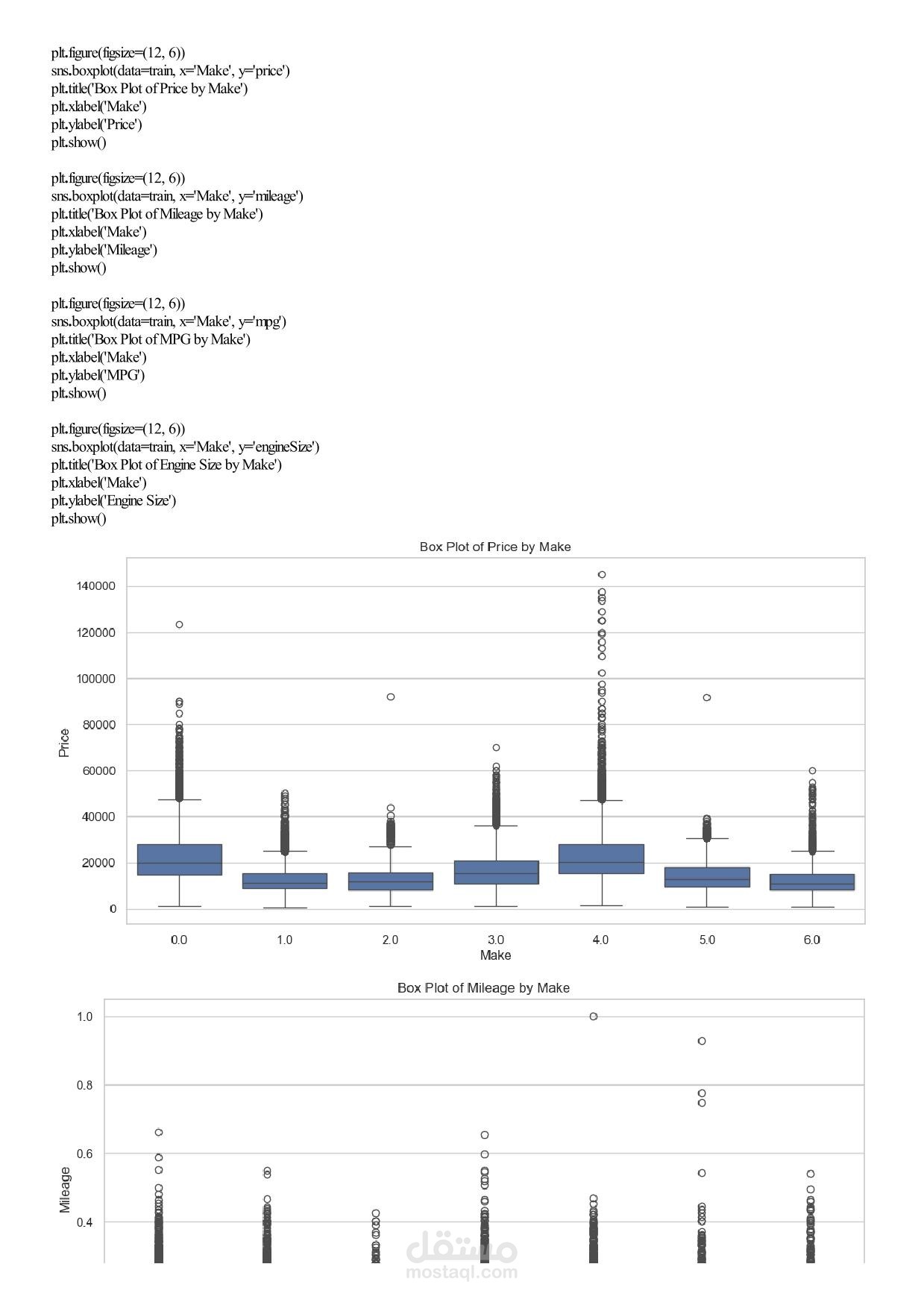
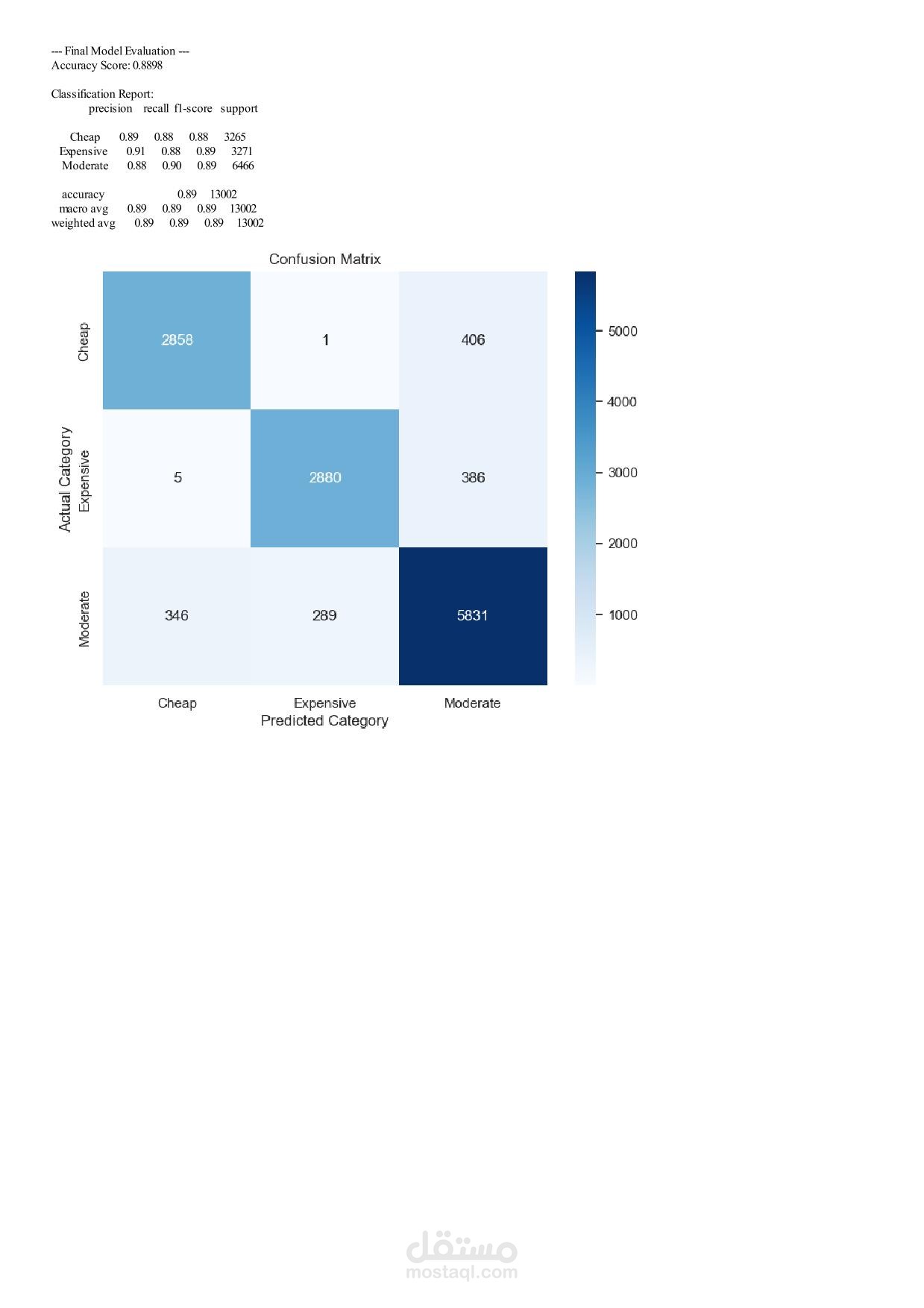





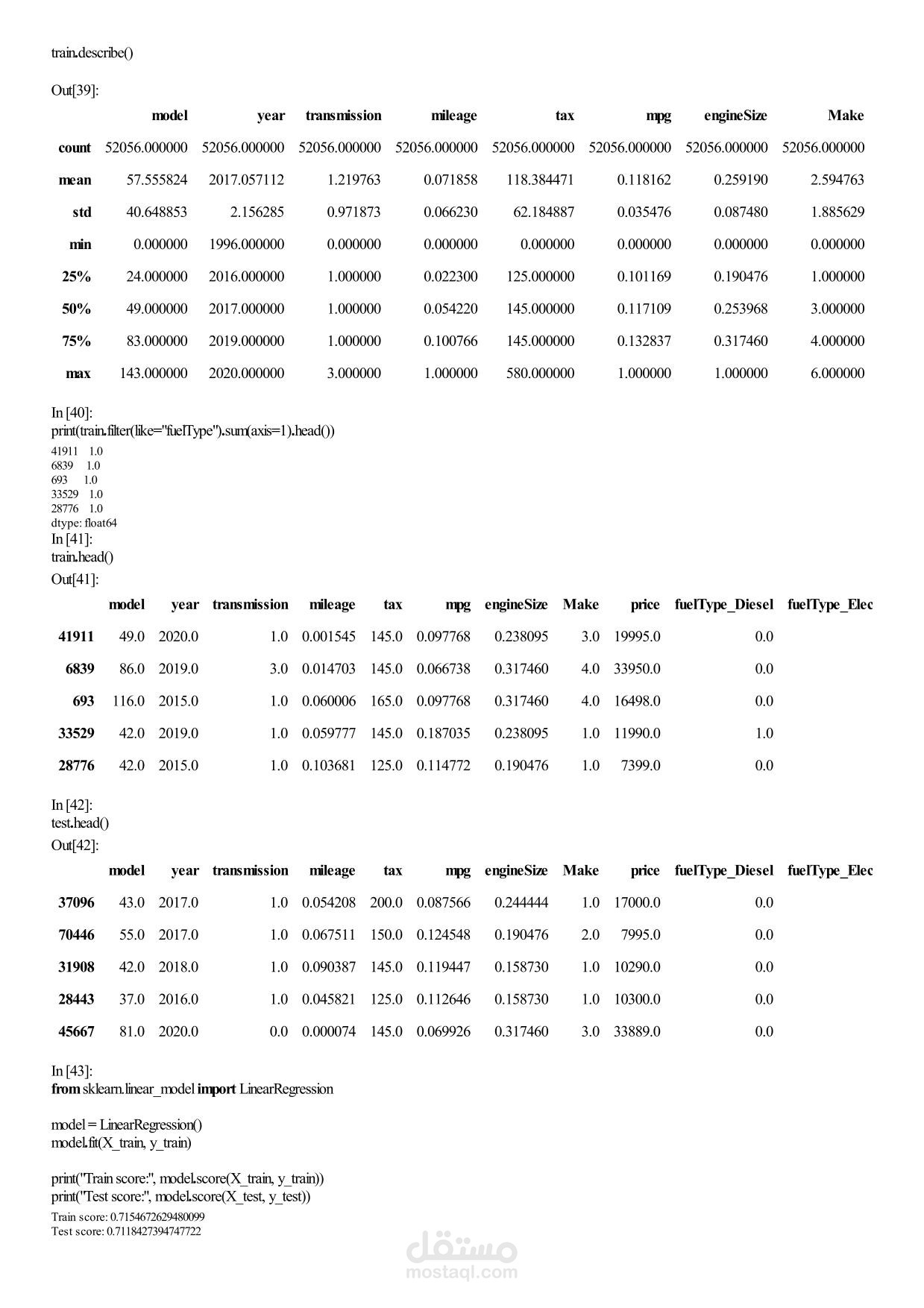

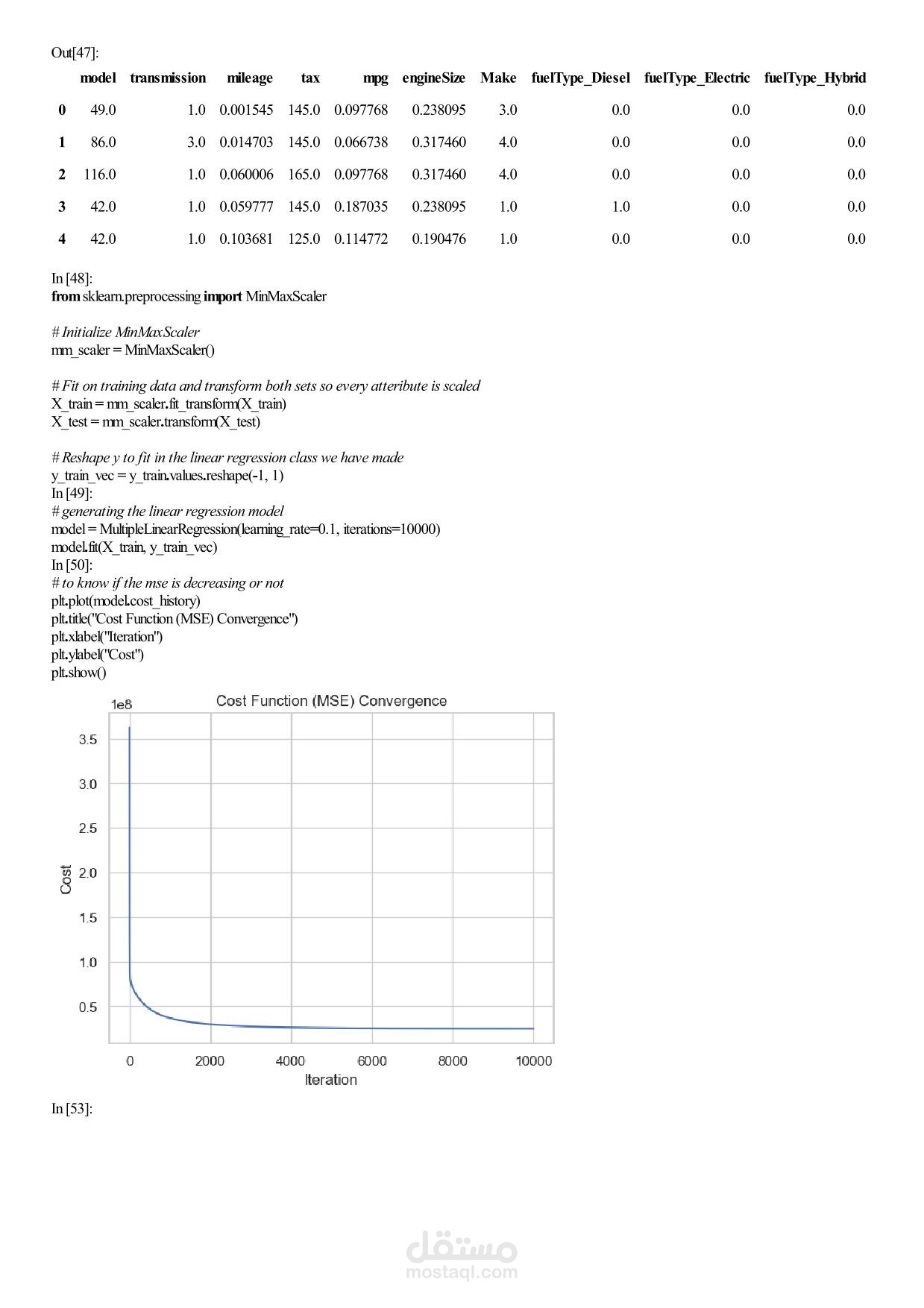
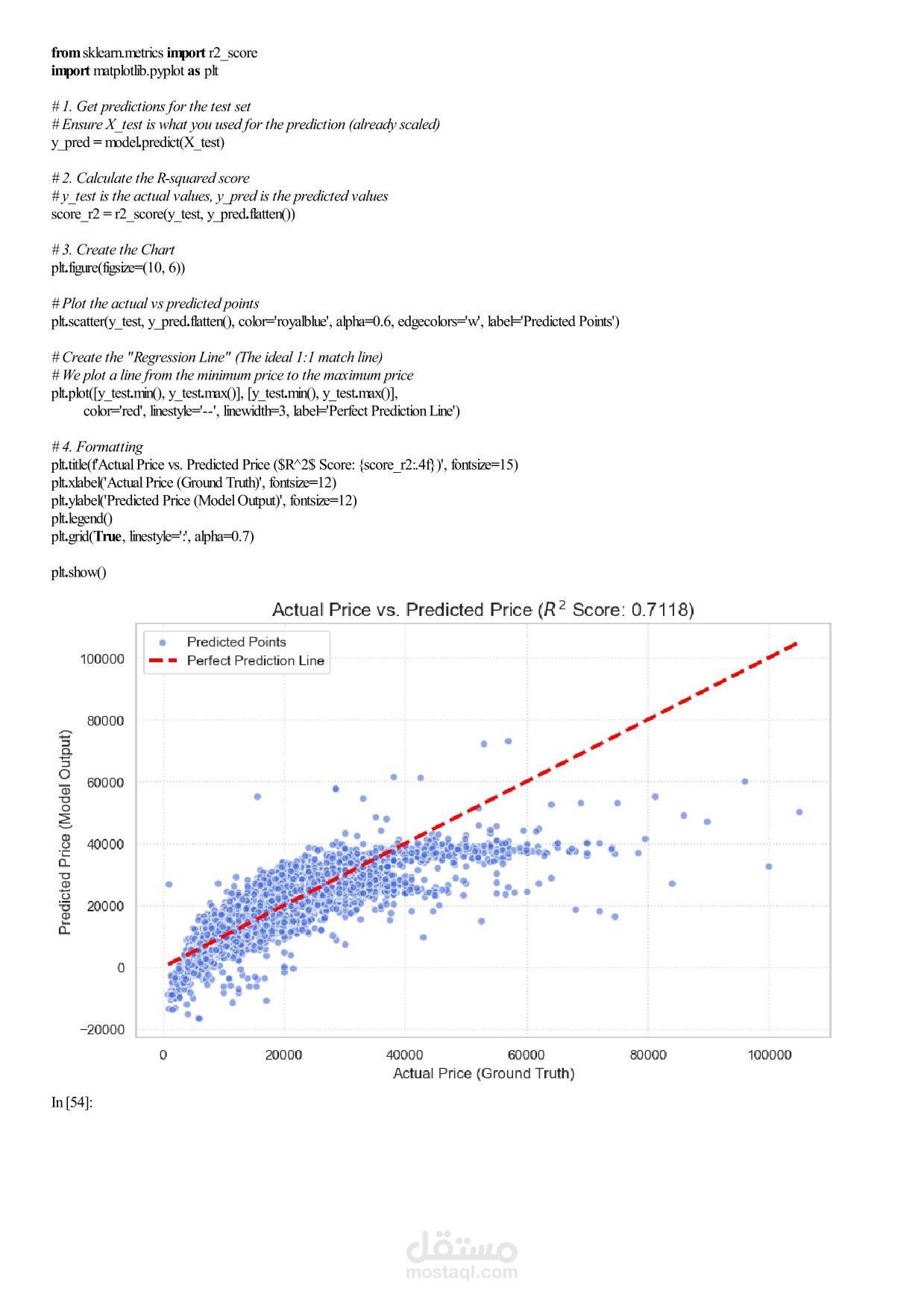

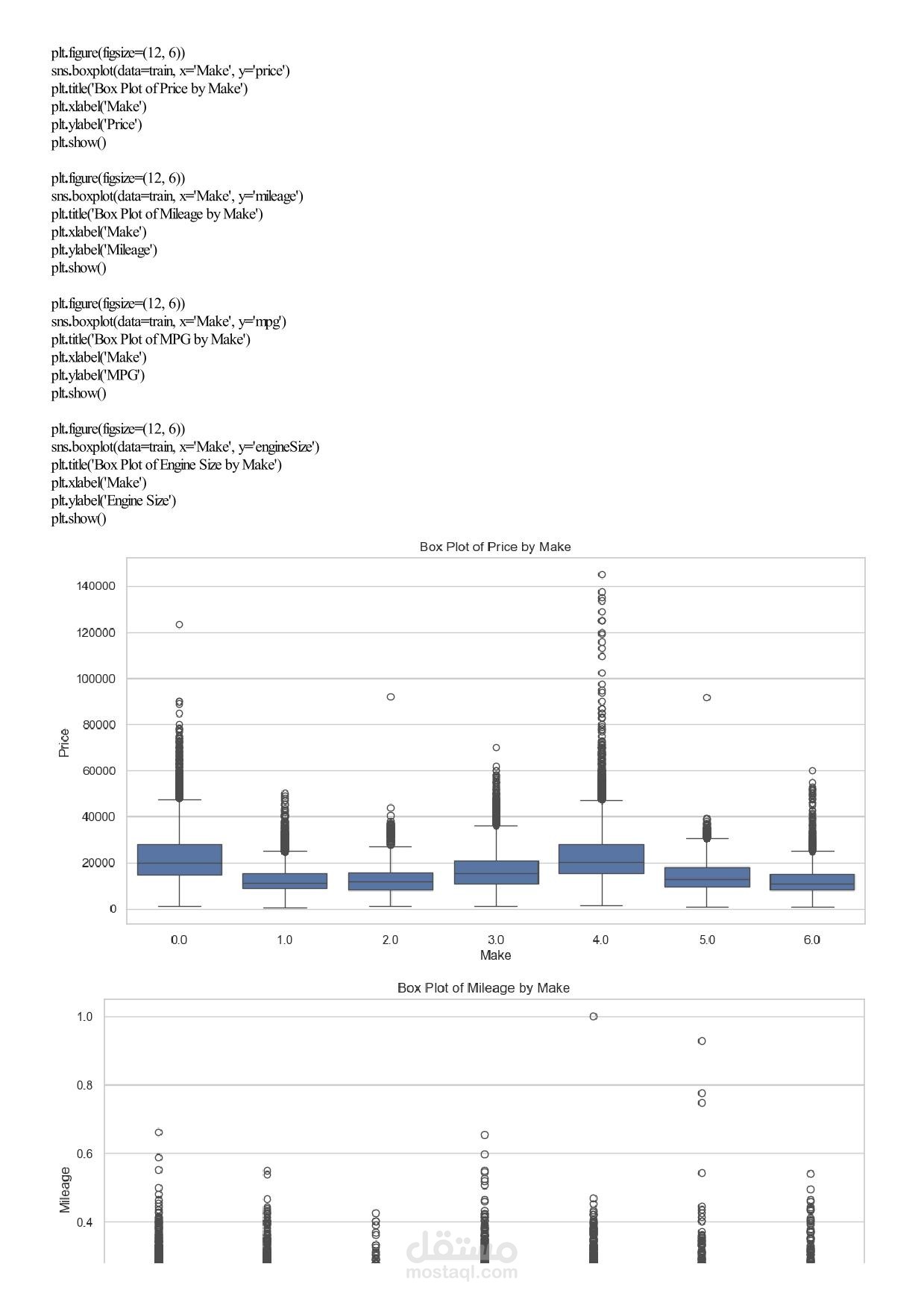
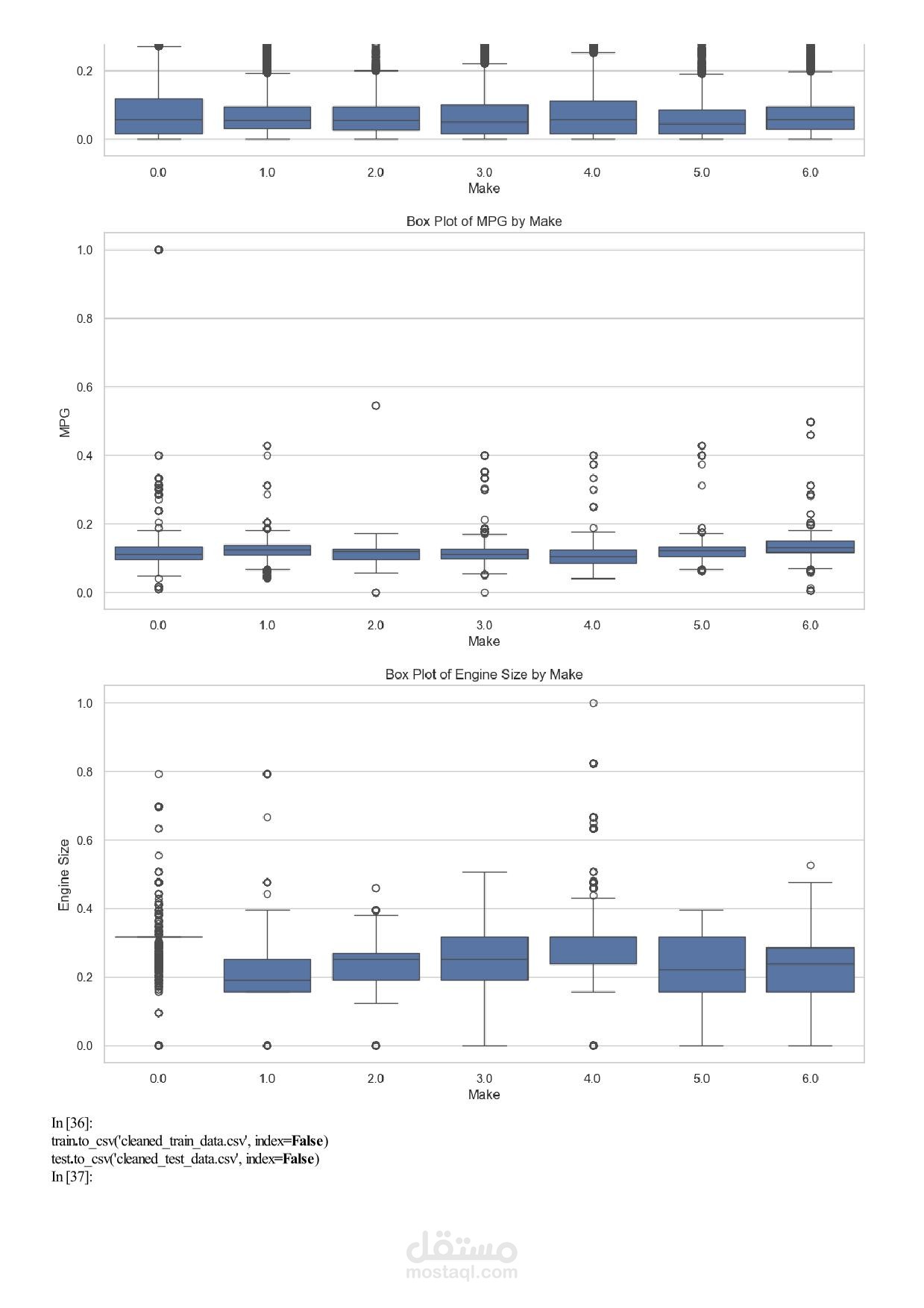

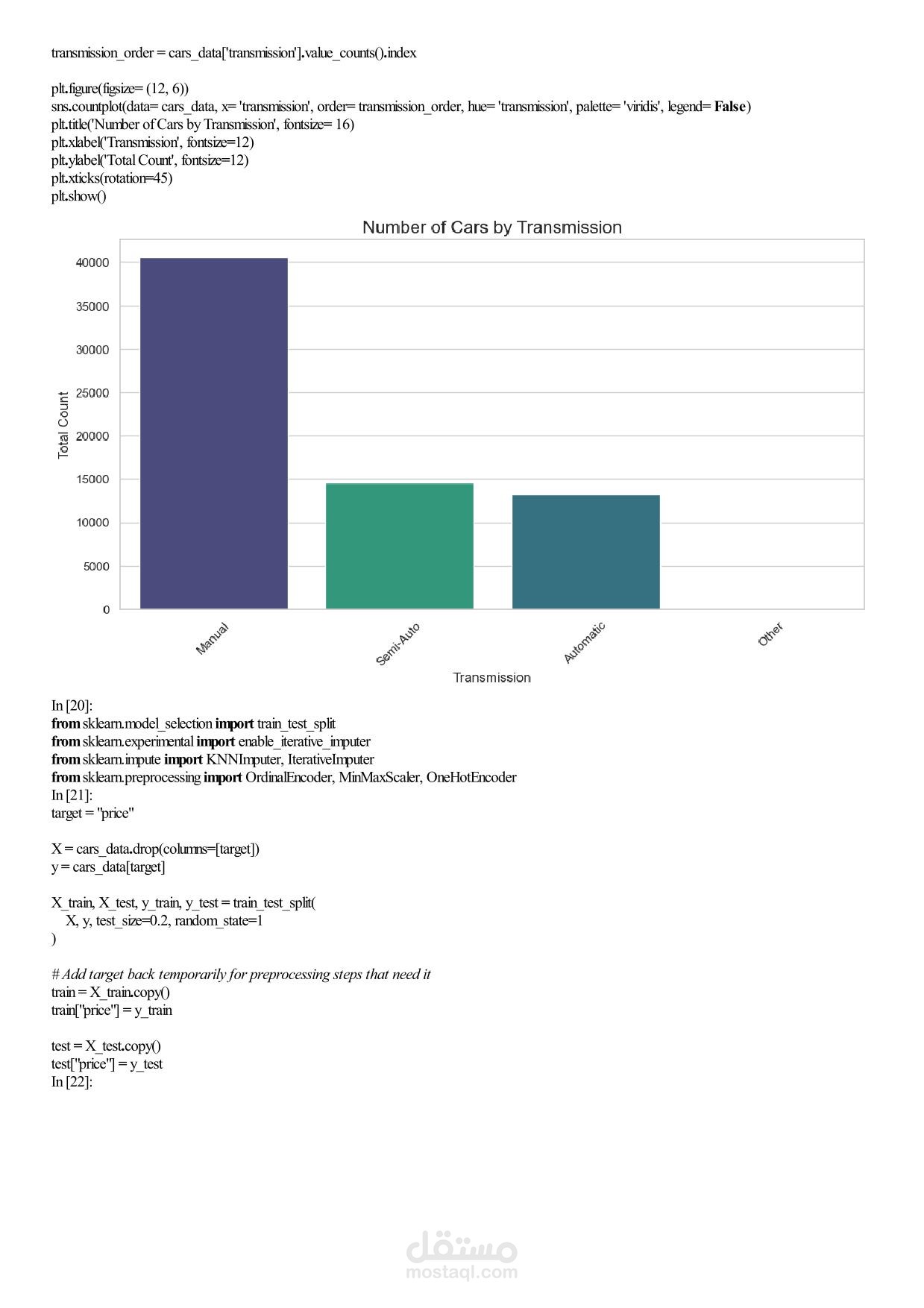




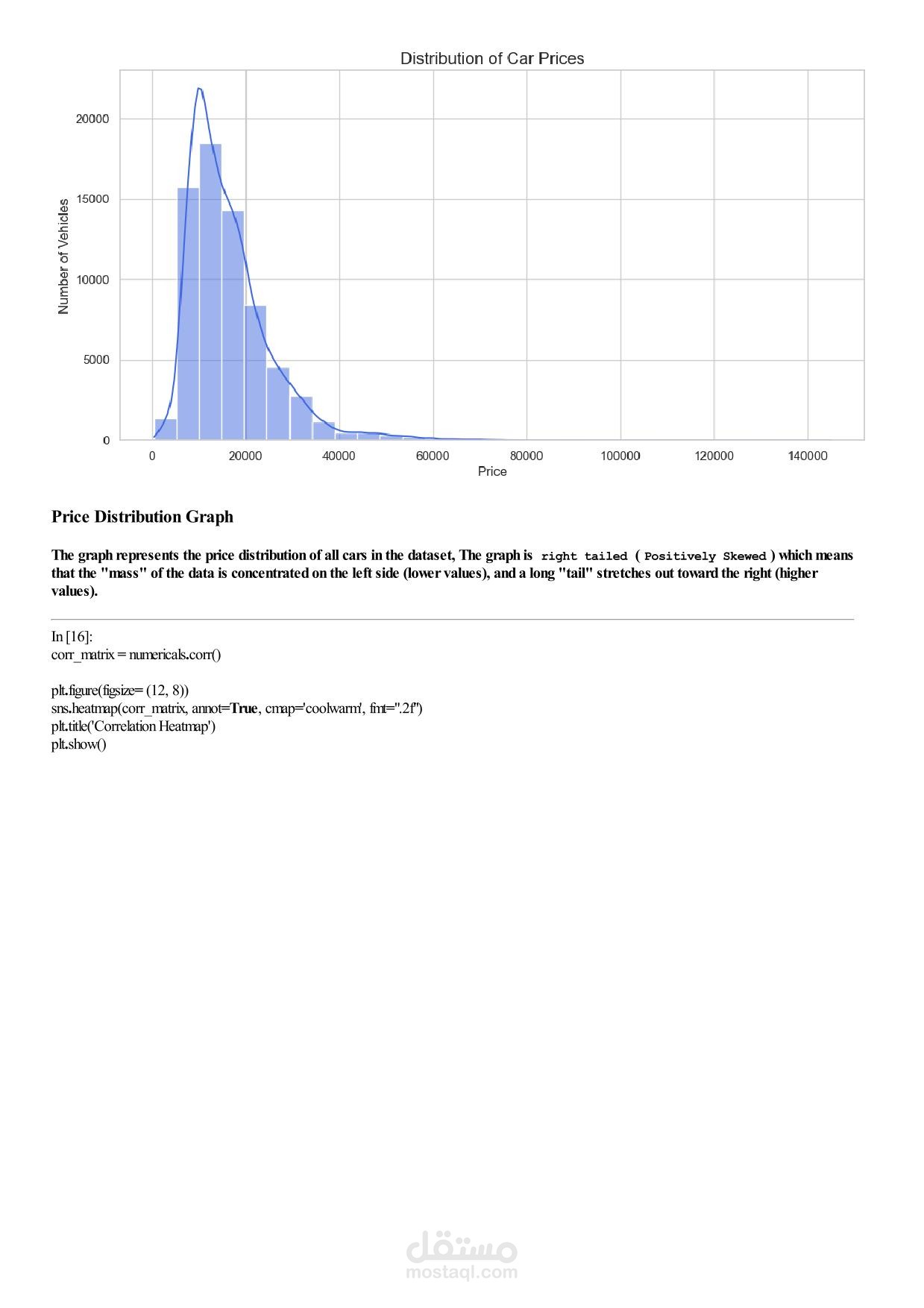
Machine Learning Assignment 1 – Car Price Analysis Overview In this assignment you will work with a real‑world car dataset to solve two machine learning problems using the same data preprocessing pipeline: Regression – predict the exact selling price of a car. Classification – group cars into price categories: Cheap, Moderate, Expensive. You will perform exploratory data analysis (EDA), preprocess the data, train and evaluate both models, and discuss the results. Team & Rules Group size: exactly 5 students per group. No cheating – any form of plagiarism will be severely penalised for both parties. Deadline: 17 April 2026, 11:59 PM. Dataset Use the Car Price Dataset from the following link: https://drive.google.com/... Download the dataset, explore it, and understand what each column represents before writing any code. Task 1 – Exploratory Data Analysis (EDA) Apply all relevant EDA techniques in Python to answer the following questions: How many rows and columns does the dataset have? Which features are numerical? Which are categorical? Are there any missing values? How many, and in which columns? What does the distribution of car prices look like? Which features seem most related to price? Task 2 – Data Preprocessing Apply the same preprocessing steps for both models. You must: Handle missing values – drop rows, fill with mean/mode, or another strategy. Justify your choice. Encode categorical columns – use Label Encoding or One‑Hot Encoding. Explain which one you chose and why. Scale numerical features – important for KNN. Use StandardScaler or MinMaxScaler. Detect and handle outliers – use boxplots or the IQR method. Task 3 – Create Two Target Variables A. Regression Target (for Linear Regression) Use the original car prices as the target. B. Classification Target (for KNN) Transform the prices into three categories: Cheap Moderate Expensive You must: Decide the price boundaries (thresholds) for each category. Justify your thresholds using the data distribution (e.g., percentiles, natural breaks). Show how many cars fall into each category after splitting. Task 4 – Model 1: Linear Regression (Regression) Train a Linear Regression model to predict the exact car price. Split the data into training and test sets (e.g., 80/20 split). Train the model on the training set. Evaluate on the test set using all relevant regression metrics (e.g., MAE, MSE, RMSE, R²). Task 5 – Model 2: KNN Classification Train a K‑Nearest Neighbors (KNN) classifier to predict the price category. Use Grid Search with k‑fold cross‑validation to find the best combination of: Number of neighbours: 3, 5, 7, 9, … (choose a reasonable range) Distance metric: euclidean, manhattan Evaluate the best model using: Accuracy, Precision, Recall, F1‑score. Show and explain the Confusion Matrix. Task 6 – Analysis and Discussion Answer the following questions inside your Jupyter Notebook (as markdown or text cells). 6.1 Model Comparison Which model performed better, and what does “better” mean in each context? Is classification easier than regression on this dataset? Why or why not? Does converting price into categories lose important information? 6.2 Sensitivity Analysis What happens if you remove the most correlated feature? Does performance drop significantly? Try running KNN without scaling – how much does performance change? Try a different threshold for your price categories – does KNN accuracy change significantly? Task 7 – Required Visualizations Include all of the following plots in your notebook: Price distribution histogram (from EDA) Correlation heatmap (from EDA) Predicted vs. Actual scatter plot (Regression) Confusion Matrix heatmap (Classification) At least two additional meaningful plots of your choice – explain what each plot shows. Deliverables Submit a single Jupyter Notebook (.ipynb) containing: All code, outputs, and visualisations. Markdown cells with explanations, justifications, and answers to Task 6. Clear section headings for each task. Important: The notebook must be self‑contained and runnable from start to finish without errors. Good luck, and happy modelling!