مساعد الصحة النفسية (RAG)
تفاصيل العمل
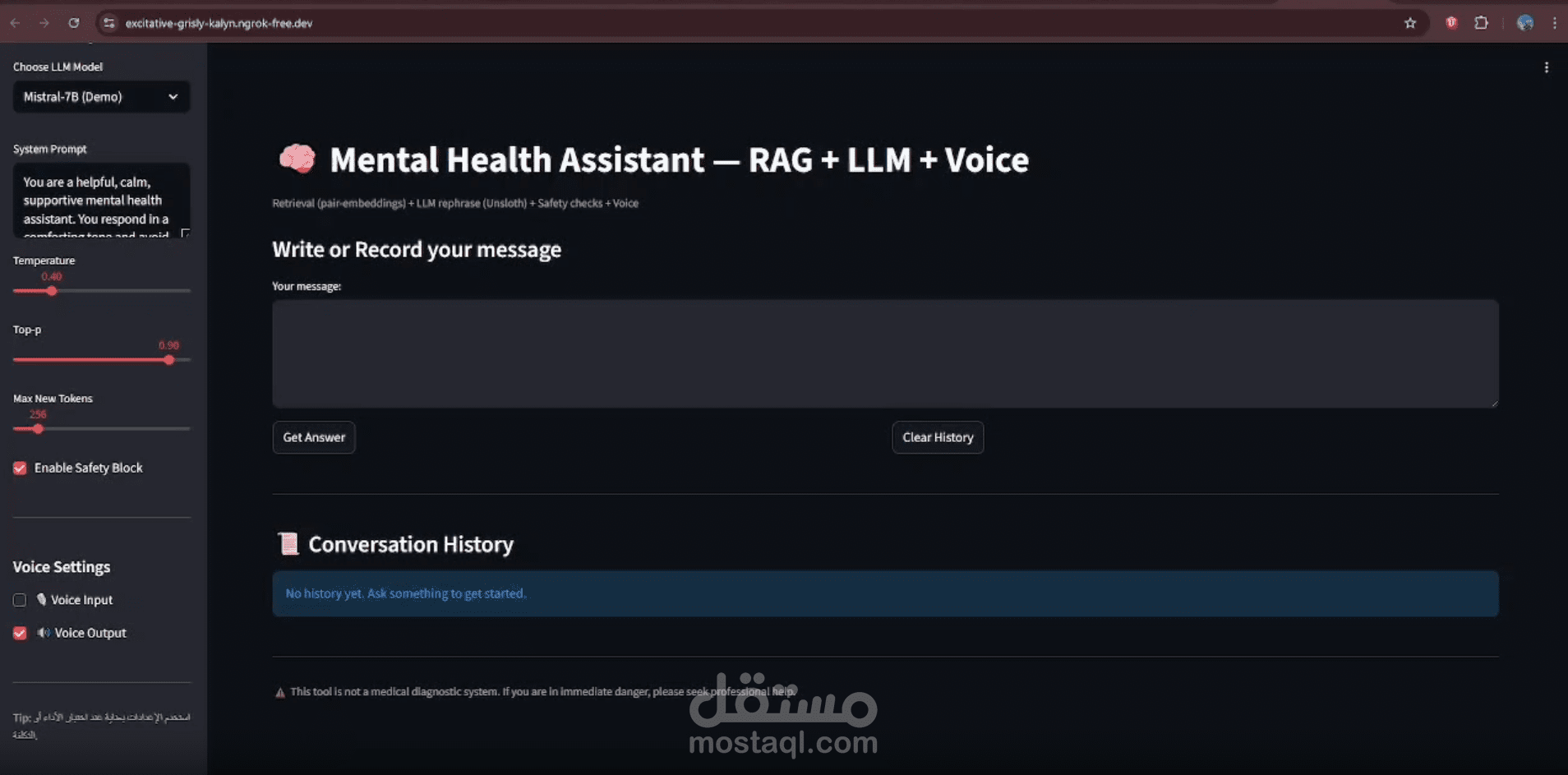
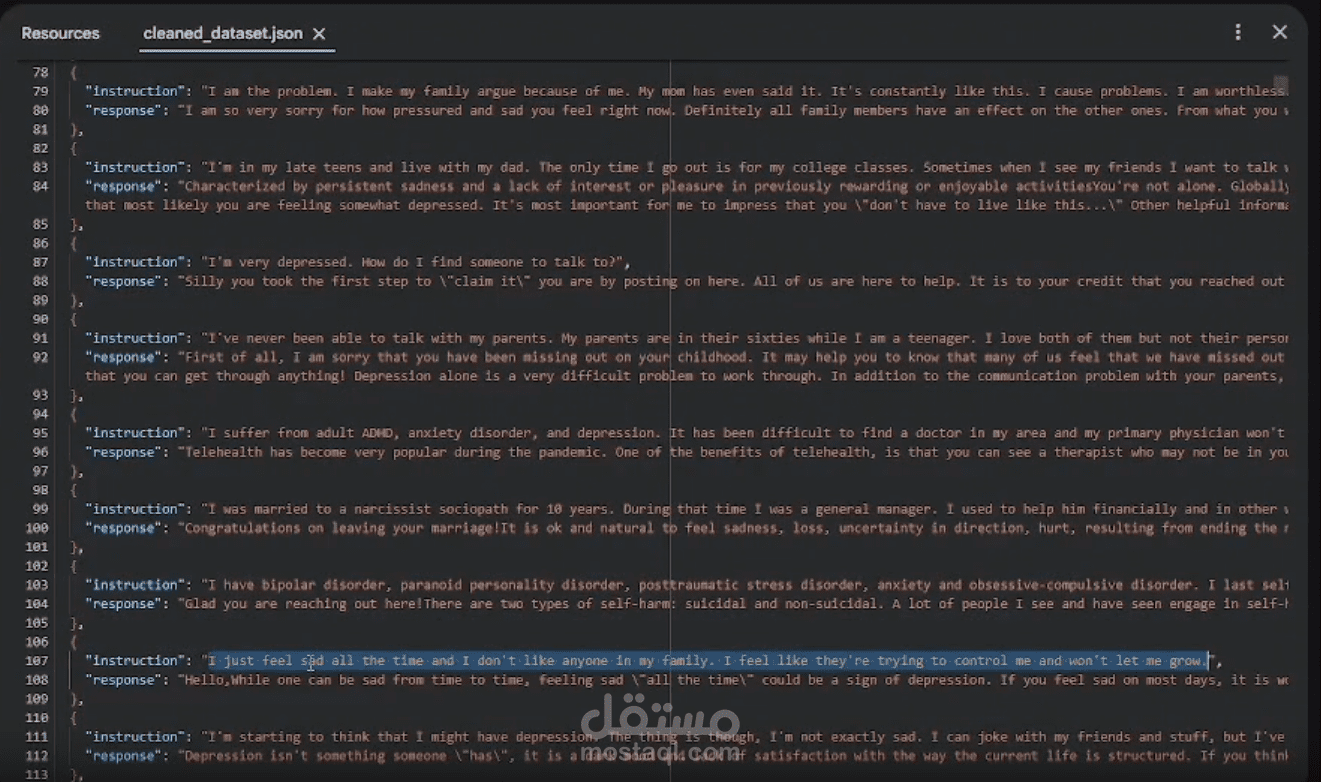
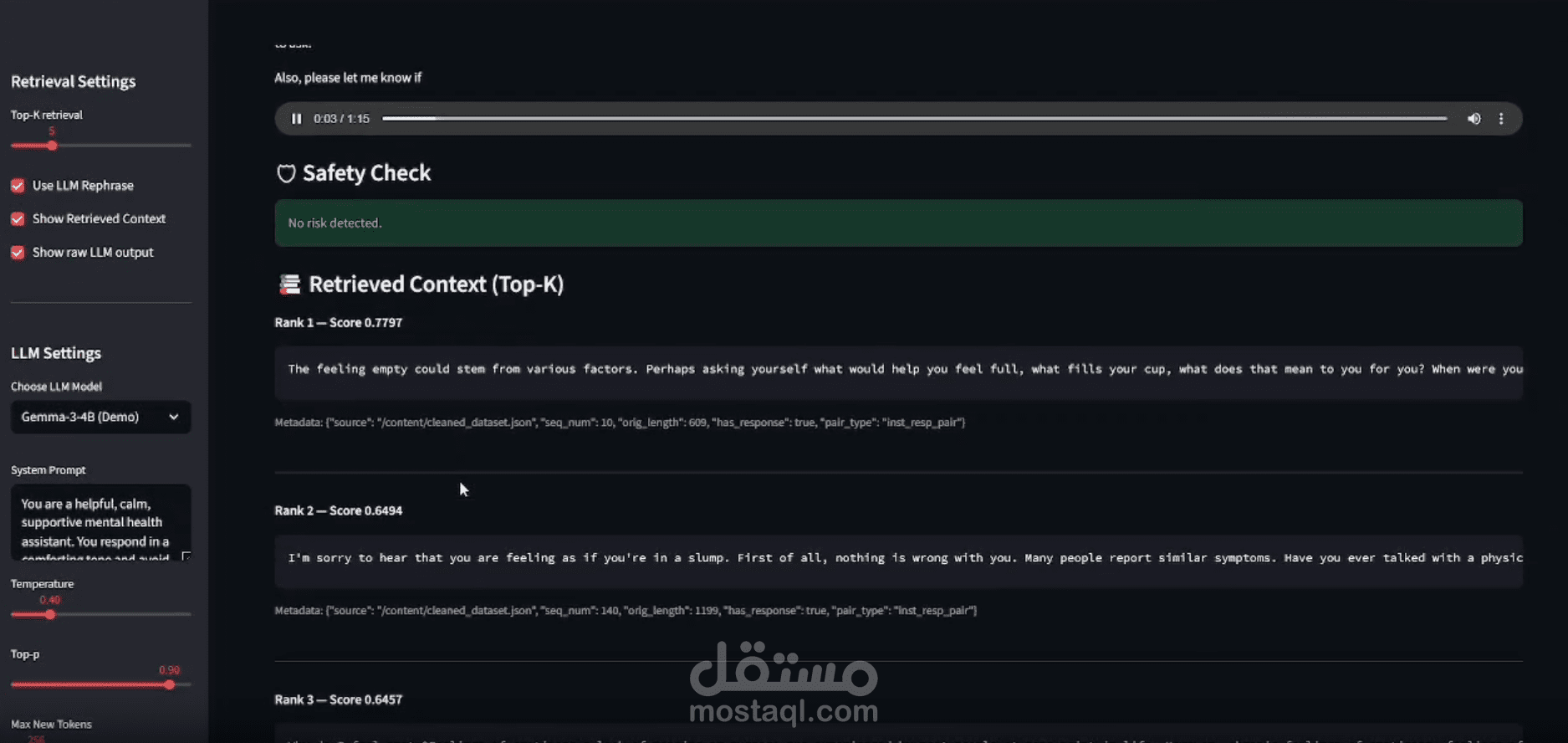
يقوم هذا المشروع بتنفيذ نظام "توليد النصوص المعزز بالاسترجاع" (RAG) المخصص لدعم الصحة النفسية.
بدلاً من الاعتماد الكلي على النموذج اللغوي (LLM) لإنتاج إجابات من العدم — مما قد يعرض النظام لخطر
"الهلوسة البرمجية" أو تقديم نصائح غير آمنة — يقوم النظام باسترجاع إجابات حقيقية لمعالجين نفسيين
من قاعدة بيانات منقحة، ثم يعيد صياغتها بأسلوب داعم ومتعاطف.
لماذا يمثل هذا المشروع أهمية؟
- الذكاء الاصطناعي ليس مصدر الحقيقة: النموذج اللغوي لا يبتكر المعلومة الطبية.
- الاستناد لخبرات واقعية: ضمان دقة الإجابات بناءً على معرفة معالجين مختصين.
- إعادة صياغة آمنة: ينحصر دور الذكاء الاصطناعي في تحسين الأسلوب فقط.
- موثوقية أعلى ومخاطر أقل: دقة أكبر في تقديم الدعم وبناء جسر من الثقة مع المستخدم.
================================================================================
المواصفات التقنية (Technical Stack)
================================================================================
* استرجاع النصوص (Pair Embedding Retrieval): استخدام التعليمات (Instructions) مع دمج ردود المعالجين.
* تمثيل البيانات (Dense MPNet Embeddings): استخدام نموذج (all-mpnet-base-v2).
* البحث الدلالي (FAISS Vector Search): لضمان سرعة فائقة في استرجاع المعلومات.
* النماذج اللغوية (Multiple LLMs via Unsloth): دعم نماذج (Llama, Gemma, Mistral).
* تحسين الأداء (4-bit quantization): لضمان سرعة الاستنتاج (Inference).
* معايير الأمان (Safety prompting): لتجنب أي مخرجات ضارة أو غير آمنة.
* واجهة المستخدم (Streamlit UI): لتوفير تجربة تفاعلية وسهلة.
* أدوات التقييم (Evaluation pipeline): لقياس جودة الاسترجاع ودقة مخرجات النموذج.
================================================================================