بناء نموذج تعلم آلة (Machine Learning) لتصنيف الرسائل النصية والبريد المزعج (Spam Detection)
تفاصيل العمل
نوع العمل:
بناء نموذج ذكاء اصطناعي لتحليل النصوص (NLP) ومعالجة اللغات الطبيعية لاكتشاف وتصنيف الرسائل غير المرغوب فيها (Spam) بدقة عالية.
ميزات العمل:
معالجة متقدمة للنصوص (Text Preprocessing): تنظيف البيانات وإزالة الرموز والكلمات الشائعة (Stopwords) وتجريد الكلمات (Stemming) للوصول إلى جوهر المعنى.
تحويل ذكي للبيانات: استخدام خوارزمية (TF-IDF) لتحويل النصوص إلى متجهات رقمية قابلة للفهم من قبل الآلة.
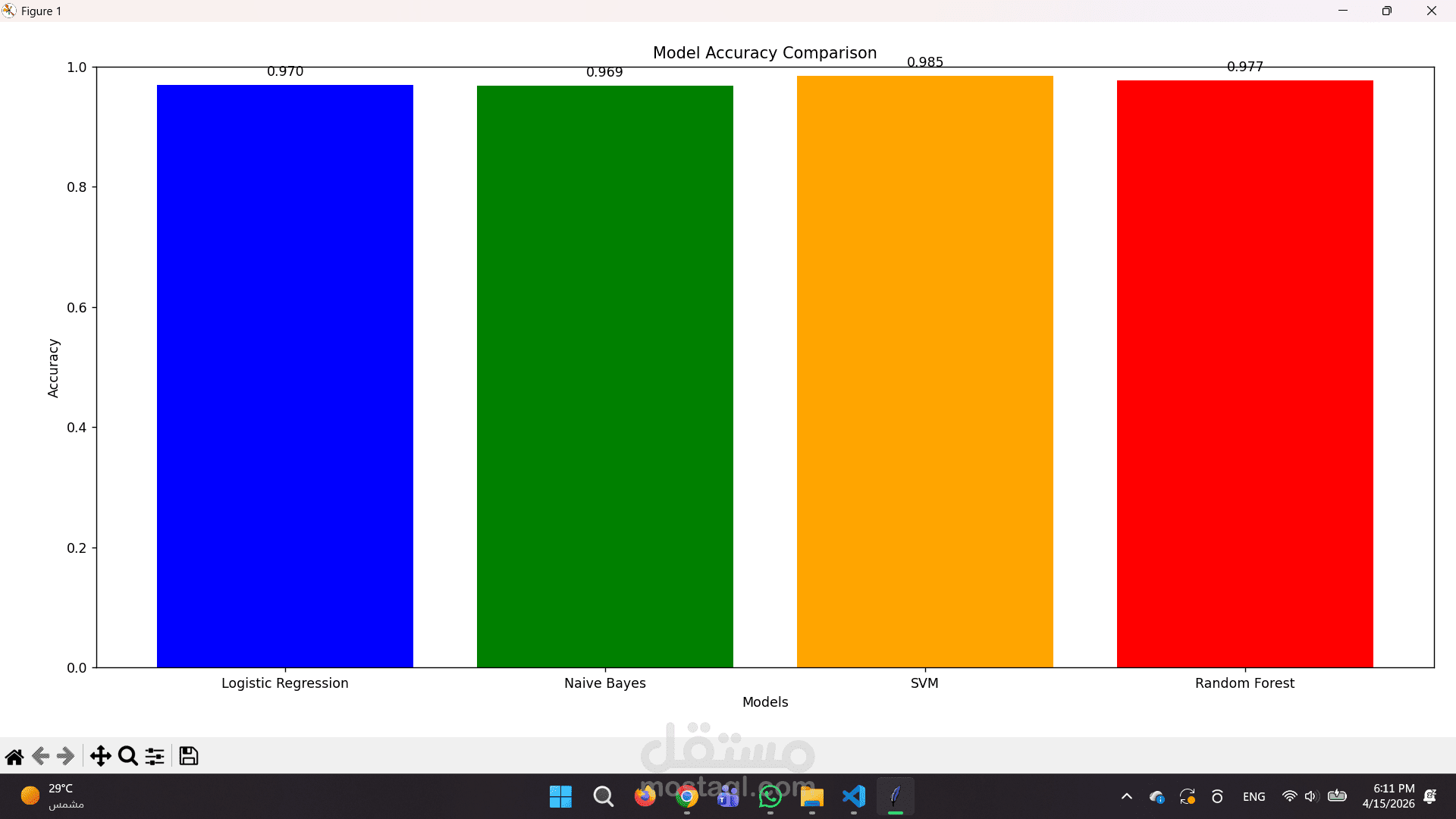
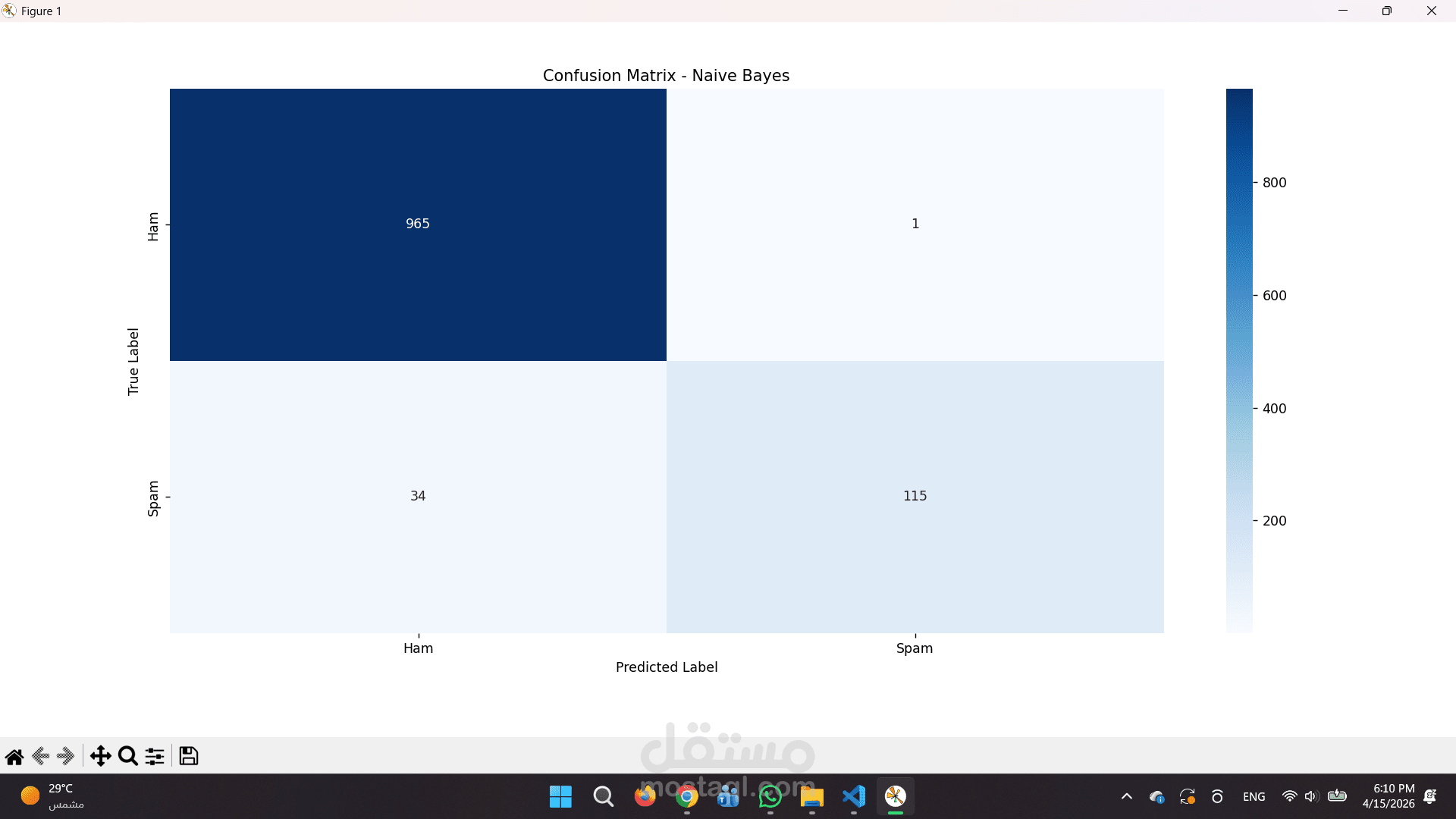
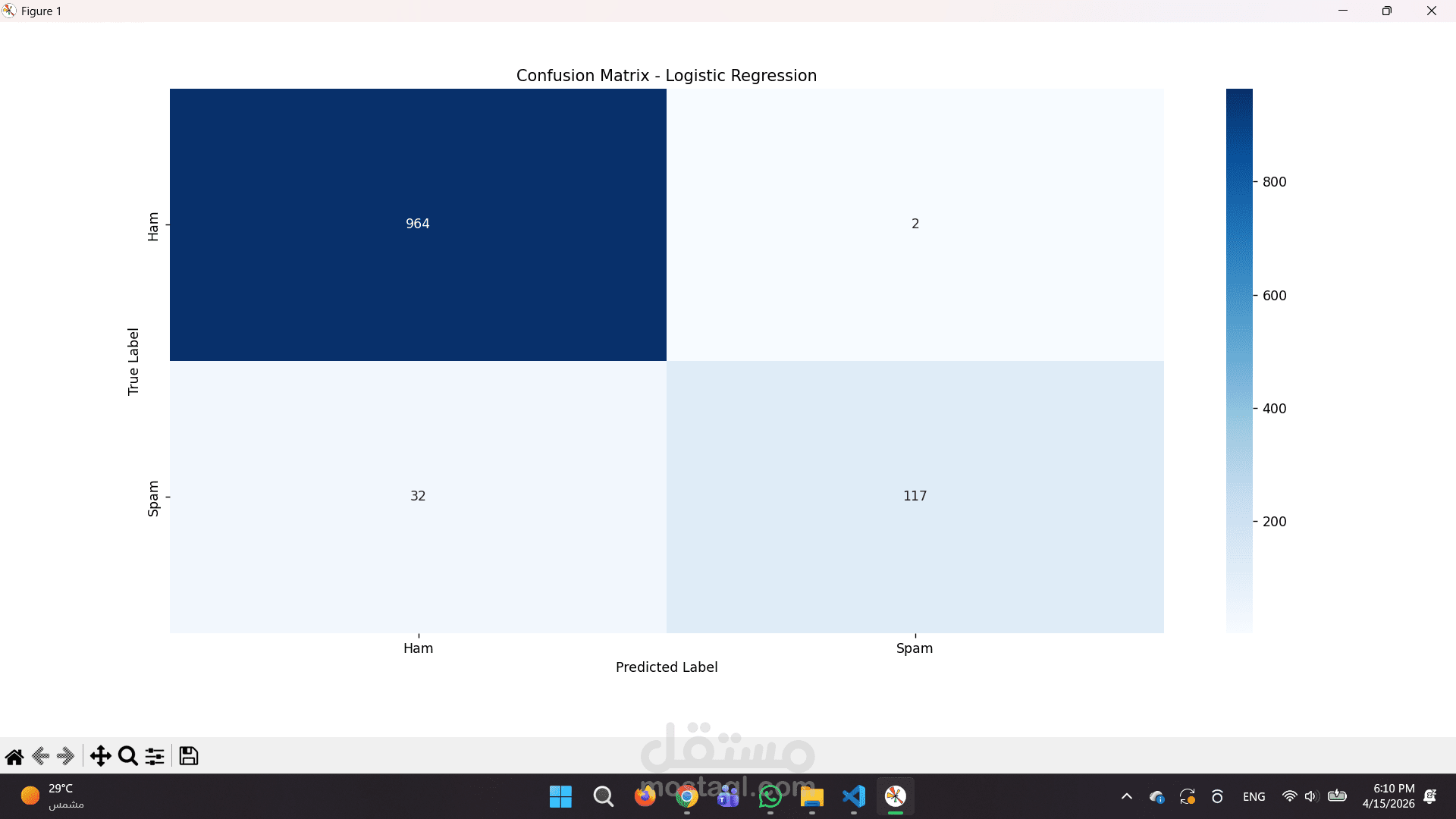
المقارنة بين النماذج: تم تدريب واختبار 4 خوارزميات مختلفة (Logistic Regression, Naive Bayes, SVM, Random Forest) والمقارنة بينهم لاختيار النموذج صاحب الدقة الأعلى (Accuracy).
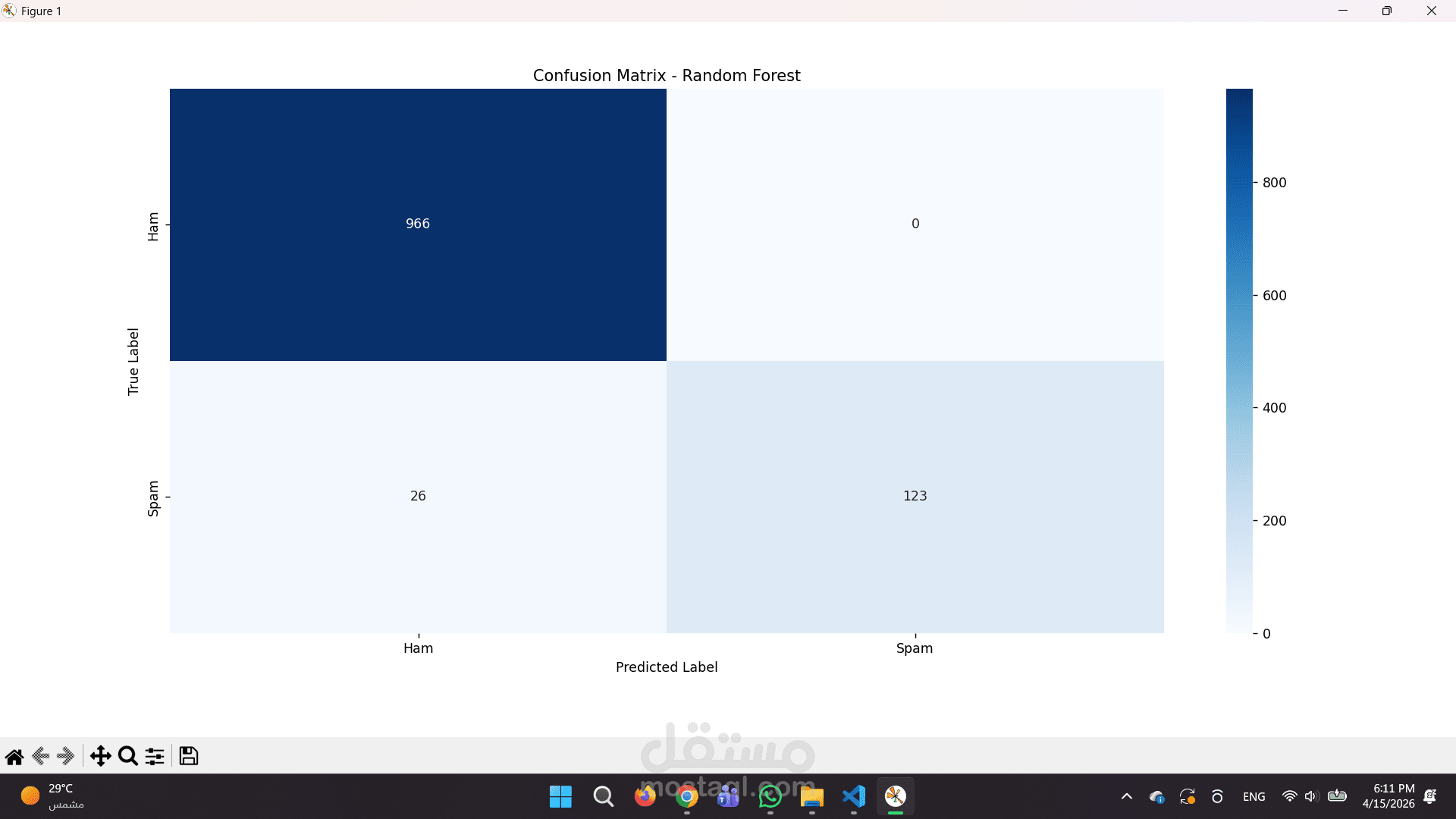
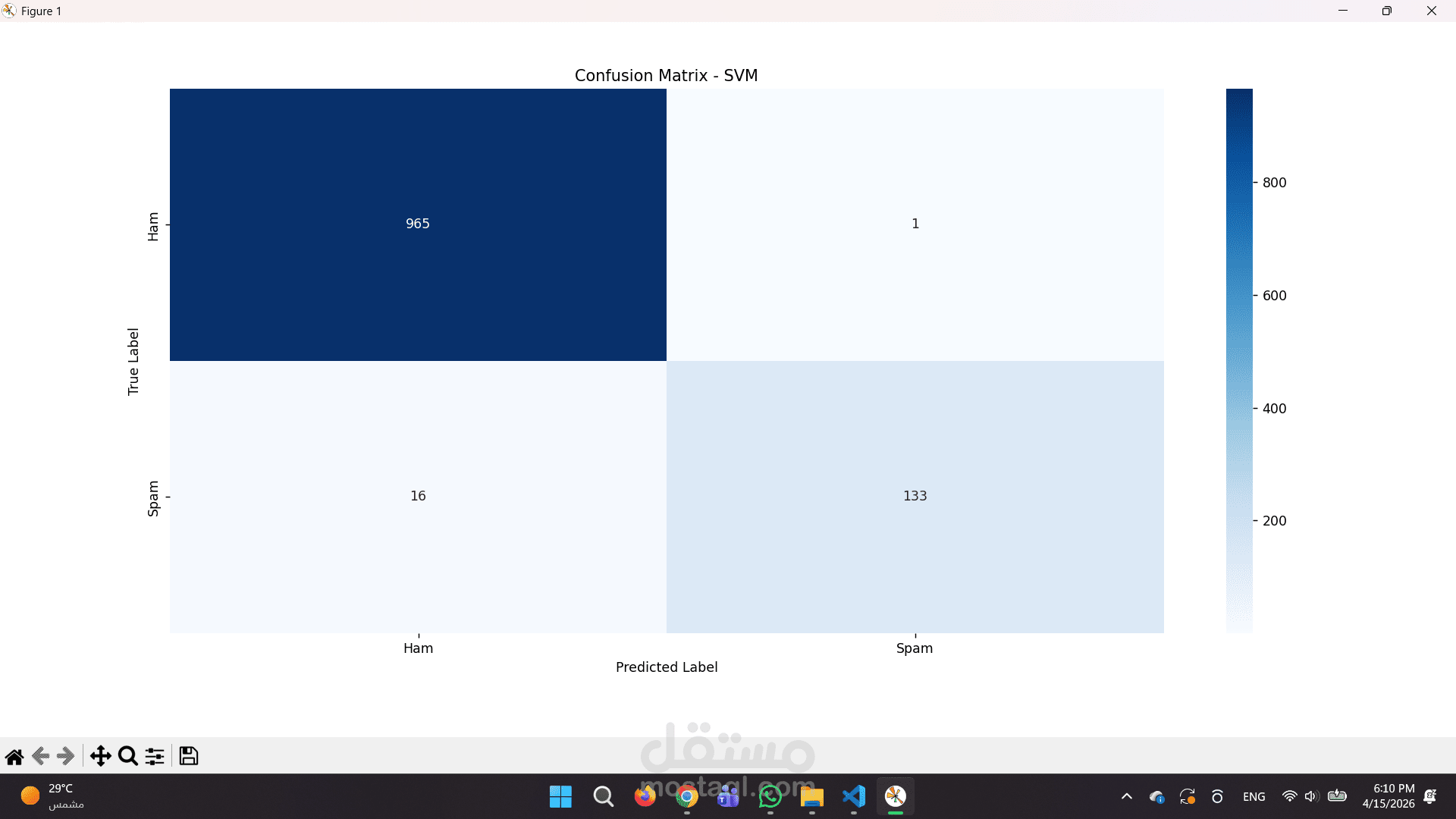
تقارير بصرية دقيقة: استخراج تقارير تقييم الأداء ورسم مصفوفة الارتباك (Confusion Matrix) لتوضيح كفاءة النموذج بالأرقام.