netfilx recommentaion system
تفاصيل العمل
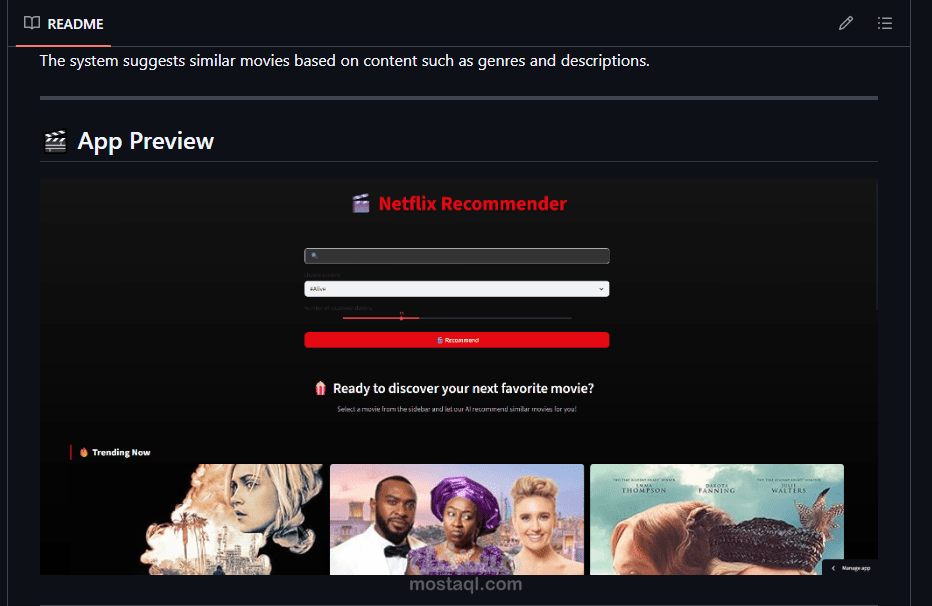
This project focuses on building a movie clustering and recommendation system using machine learning techniques.
We started by cleaning and preprocessing text data, including movie descriptions and genres, to prepare it for analysis.
Then, we converted the text into numerical features using TF-IDF, allowing us to represent each movie as a vector.
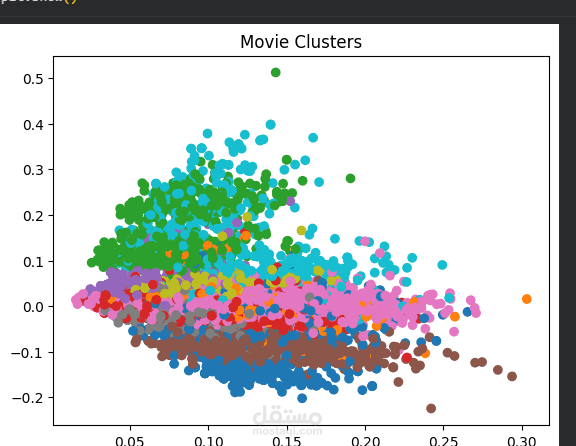
To improve performance and reduce noise, we applied dimensionality reduction using Truncated SVD, which helped us capture the most important information in fewer features.
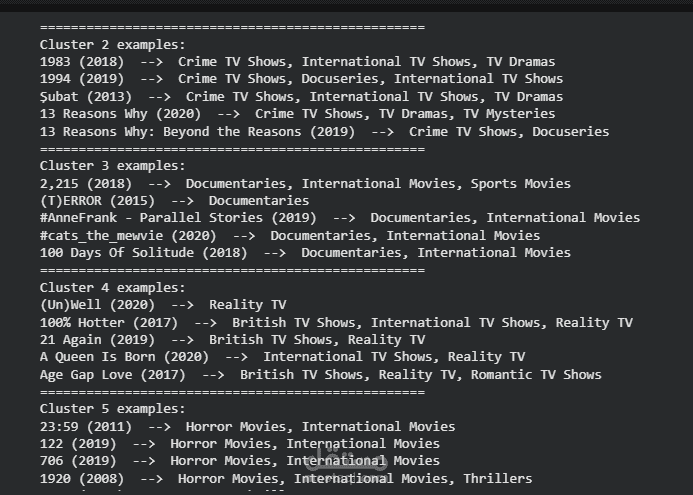
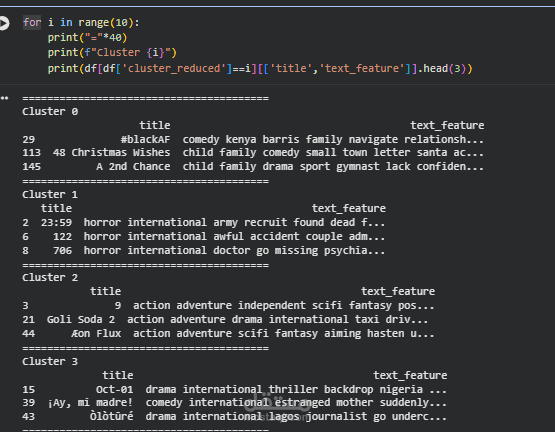
Next, we used K-Means clustering to group similar movies together based on their content.
We determined the optimal number of clusters using the Elbow Method and evaluated the results using the Silhouette Score.
Finally, we built a recommendation system that suggests similar movies based on their cluster and similarity between feature vectors.