Web Scraping
تفاصيل العمل
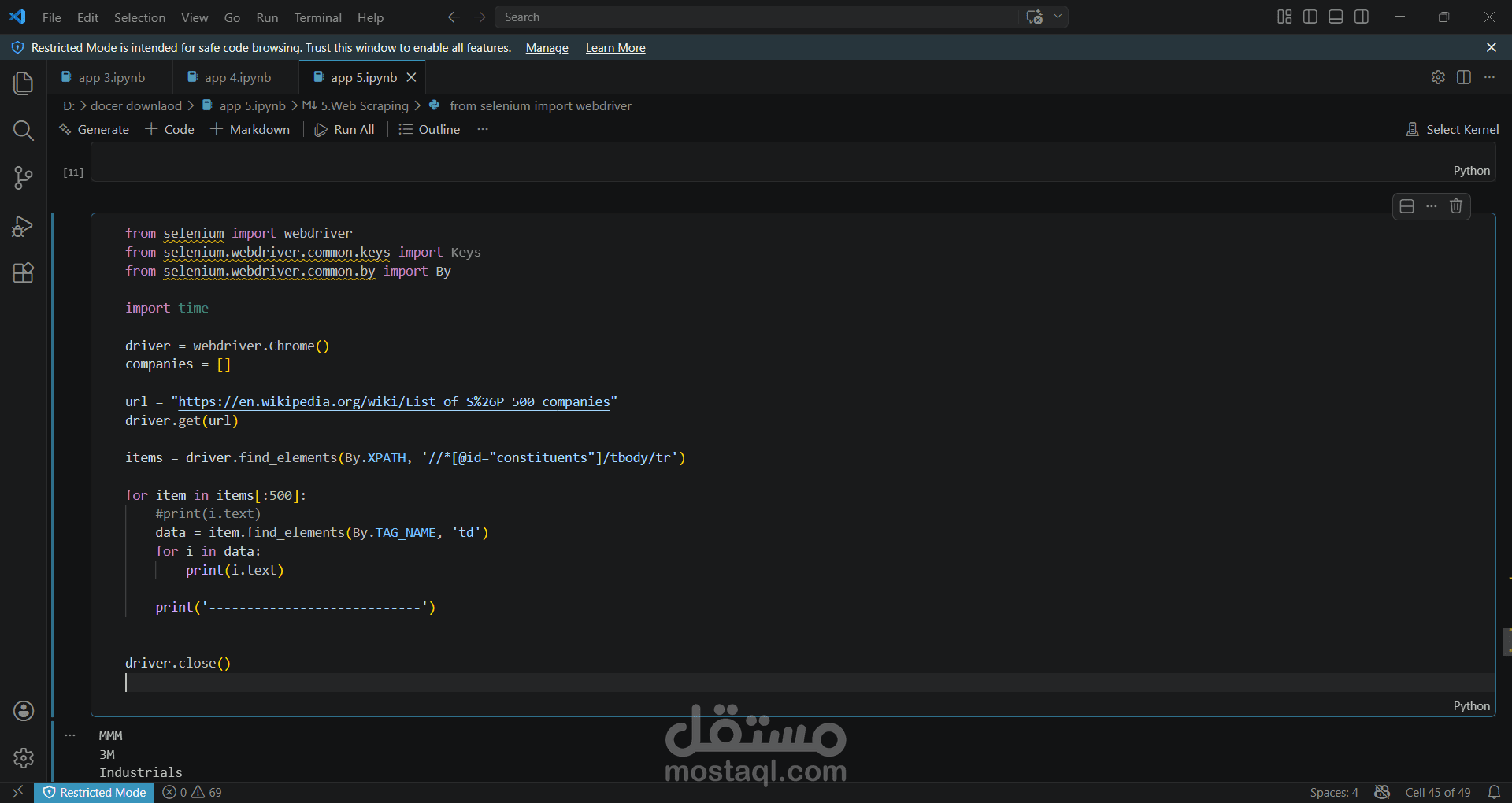
قمت بتطوير سكربت باستخدام لغة Python ومكتبة Selenium لاستخراج بيانات شركات مؤشر S&P 500 من موقع ويكيبيديا بشكل آلي (Web Scraping).
يعتمد السكربت على تحديد جدول الشركات داخل الصفحة باستخدام XPath، ثم استخراج البيانات من كل صف داخل الجدول مثل اسم الشركة، الرمز (Ticker)، القطاع، والمقر الرئيسي.
يتم بعد ذلك قراءة كل خلية داخل الصف (Table Data) ومعالجة البيانات بشكل منظم.
المشروع يوضح القدرة على التعامل مع الجداول المعقدة في صفحات الويب واستخراج البيانات منها بدقة