Question Classification System Using Naïve Bayes (NLP Project)
تفاصيل العمل
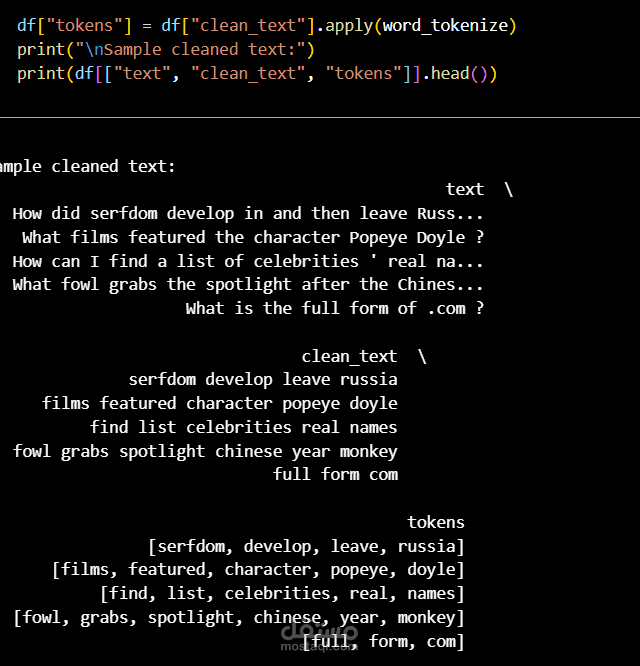
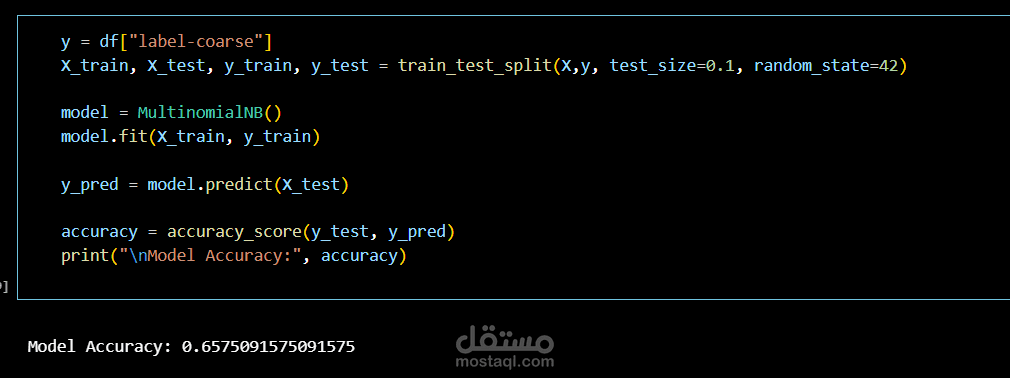
This project focuses on building a Natural Language Processing (NLP) model to automatically classify questions into predefined categories using Machine Learning techniques.
The model was trained on the TREC Question Classification Dataset, which includes multiple question types such as:
Human
Location
Number
Description
Entity
Abbreviation
The workflow of the project includes:
Loading and exploring the dataset using pandas
Performing text preprocessing techniques:
converting text to lowercase
removing punctuation
removing stopwords
tokenization
Converting text into numerical features using TF-IDF / Bag of Words
Training a Naïve Bayes classification model
Evaluating model performance and prediction accuracy
This project demonstrates practical implementation of NLP pipelines for automatic question classification systems used in:
Chatbots
Question Answering Systems
Search Engines
Virtual Assistants
Customer Support Automation
Technologies used:
Python
pandas
scikit-learn
NLP preprocessing techniques
TF-IDF / Bag of Words