أتمتة تنظيف ومعالجة البيانات (Data Preparation) باستخدام Python و Pandas
تفاصيل العمل

"البيانات غير النظيفة تؤدي حتماً لقرارات خاطئة... وهنا يبدأ الحل البرمجي."
نبذة عن المشروع:
هذا المشروع هو عبارة عن "دراسة حالة تطبيقية" (Case Study) تم تنفيذها على مجموعة بيانات اختبارية معقدة وواسعة النطاق، بهدف استعراض المنهجية الهندسية في أتمتة تنظيف البيانات وتحويلها من حالة الفوضى إلى بيانات نقية جاهزة لاستخراج مؤشرات الأداء.
التحدي والمشكلة:
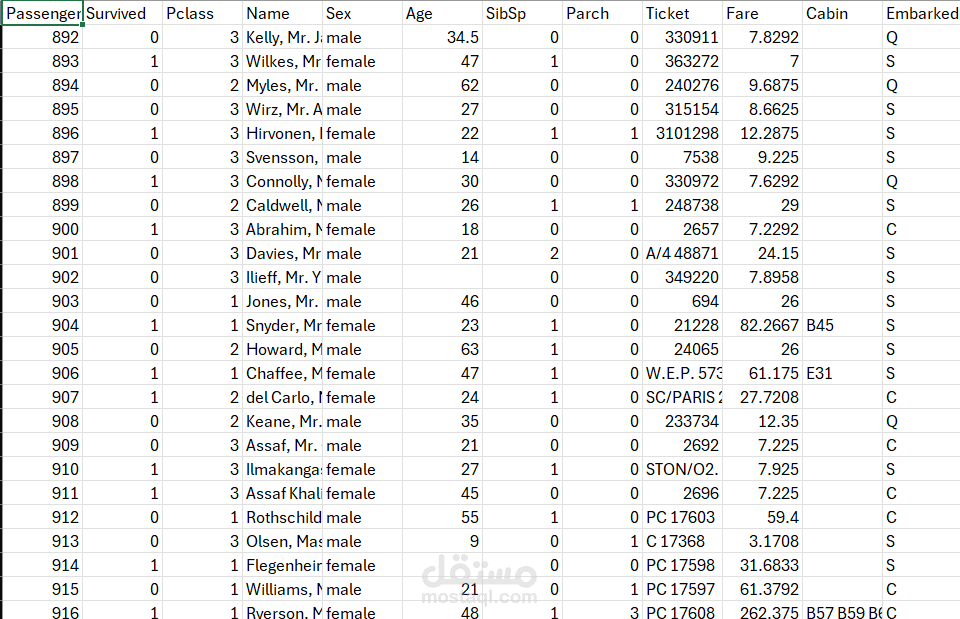
البيانات الخام كانت تعاني من مشاكل متعددة تحاكي تحديات بيئات العمل الحقيقية:
وجود عدد كبير من القيم المفقودة (Missing Values).
تكرار في السجلات (Duplicates) يؤدي لإحصائيات مضللة.
عدم توحيد تنسيقات النصوص والأرقام.
الحل الهندسي (ما قمت بتنفيذه):
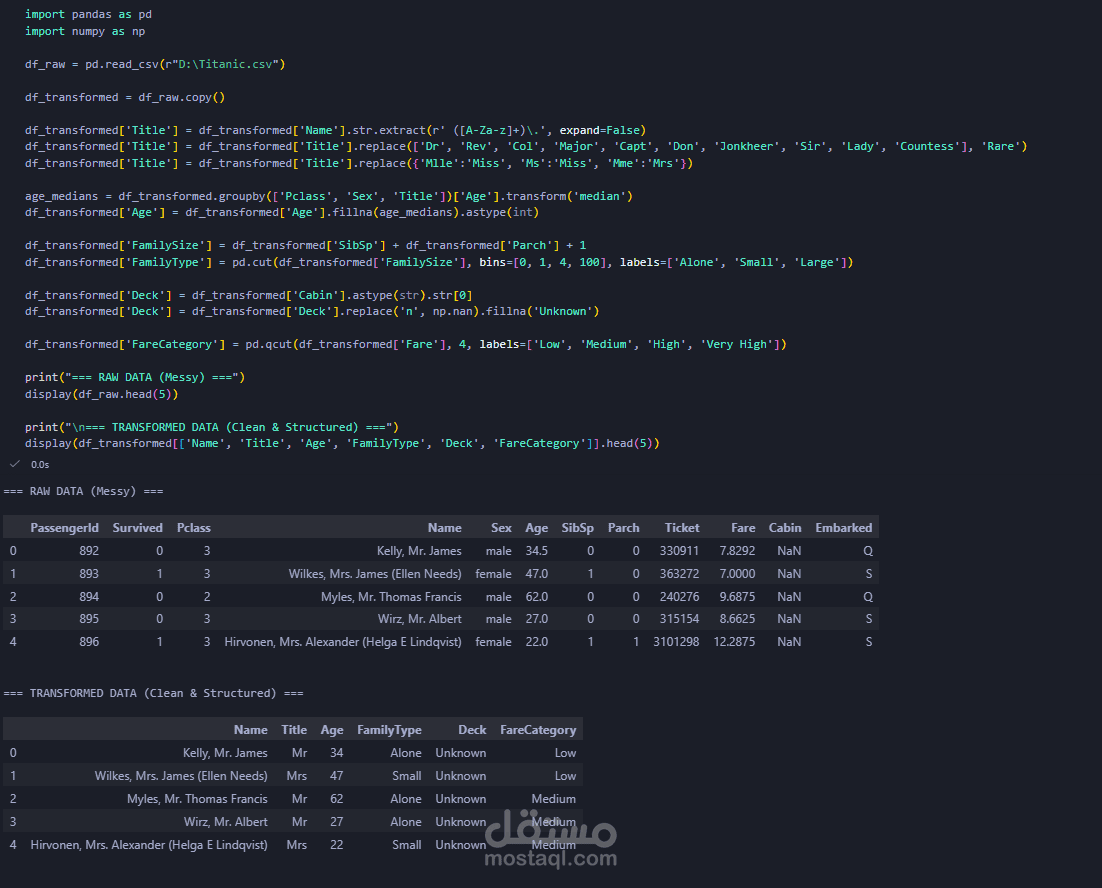
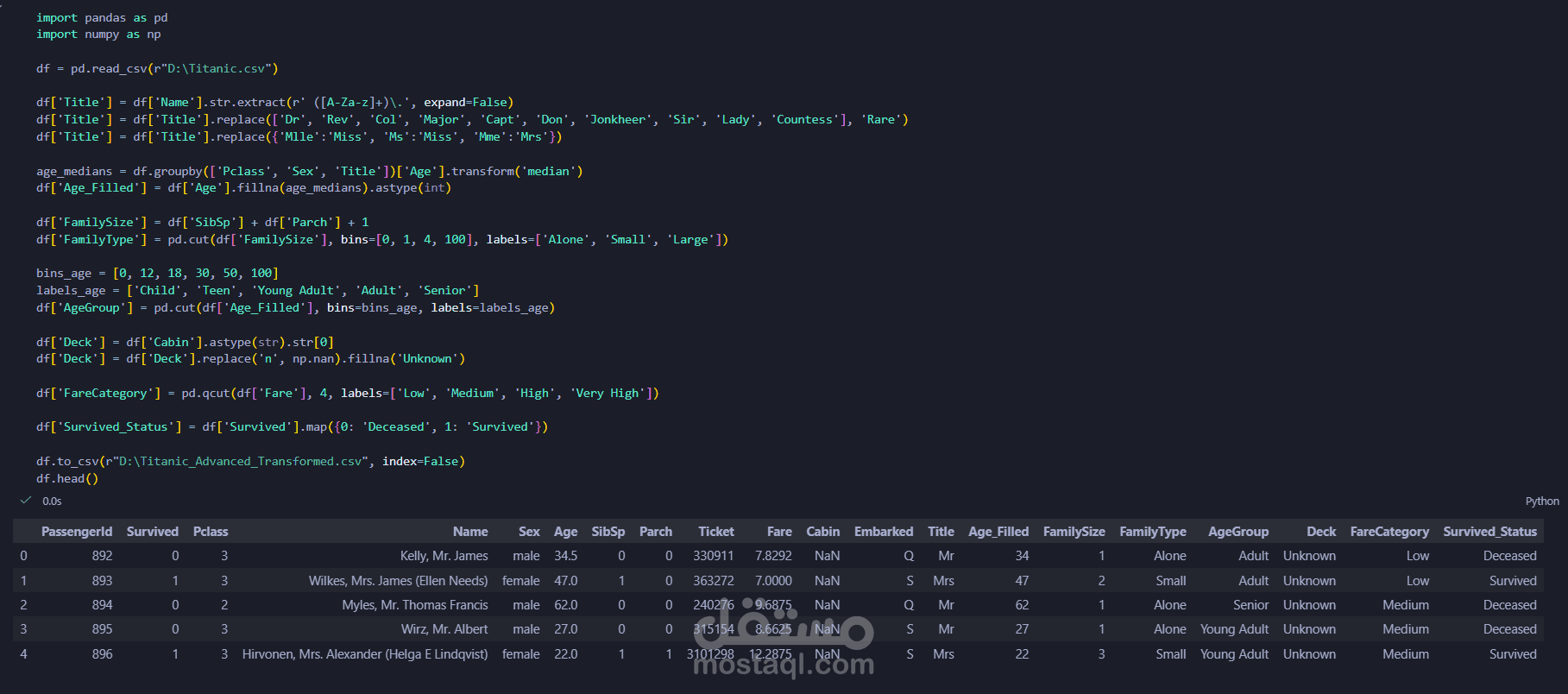
قمت ببناء مسار بيانات (Data Pipeline) مصغر باستخدام Python:
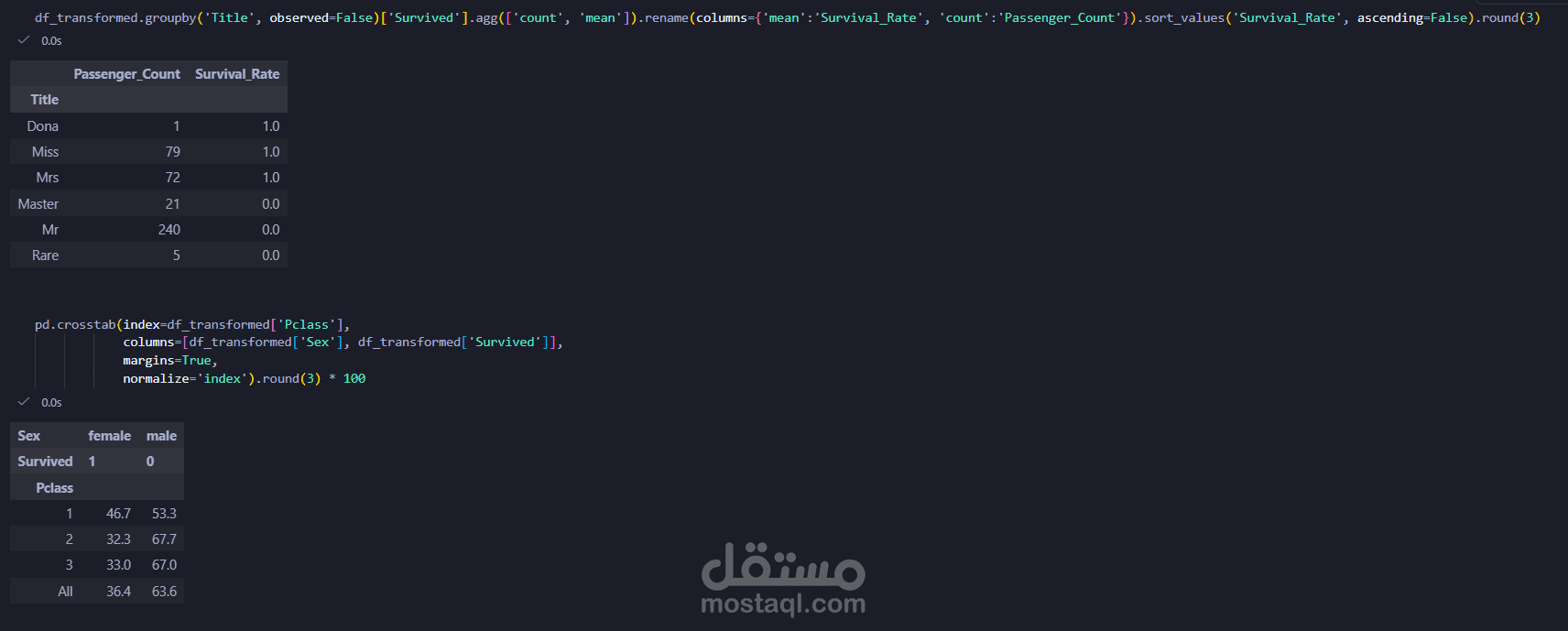
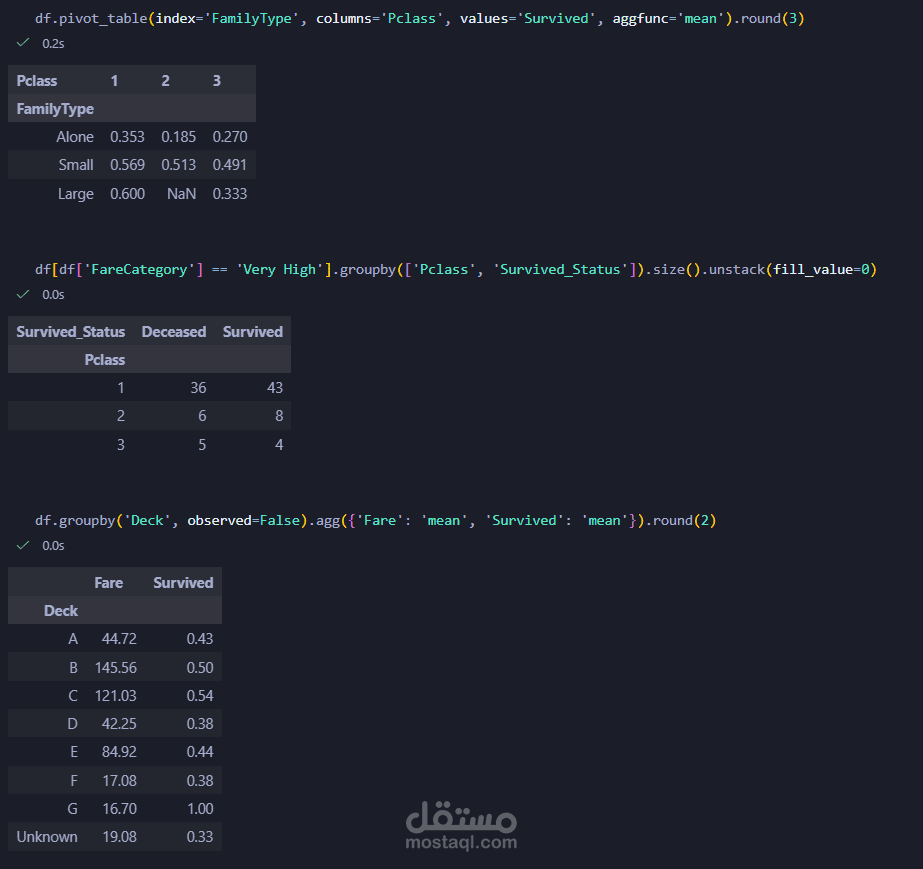
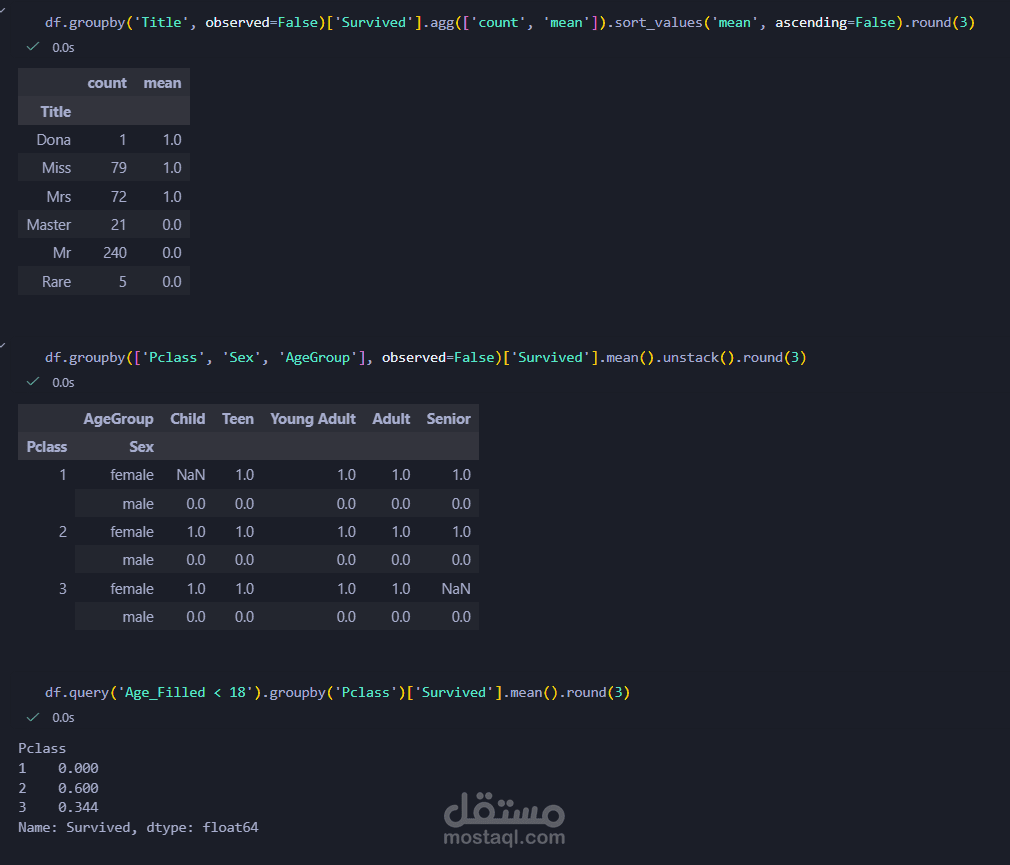
استكشاف البيانات (EDA): فحص البيانات برمجياً لتحديد حجم الأخطاء والتوزيع الإحصائي.
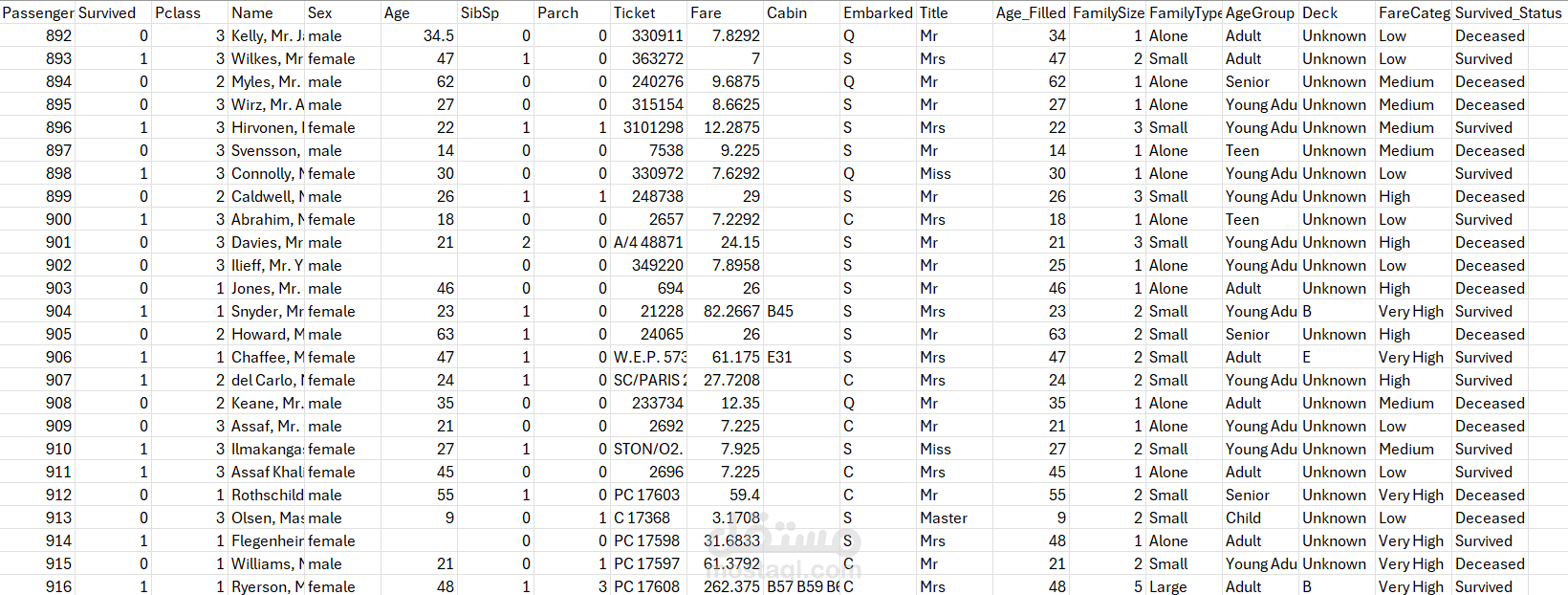
المعالجة الآلية بـ Pandas: كتابة نصوص برمجية (Scripts) لمعالجة القيم المفقودة وحذف التكرارات بدقة.
هندسة البيانات (Feature Engineering): دمج واستخراج ميزات جديدة (Features) لزيادة القيمة التحليلية للملف.
التوحيد والتصدير: توحيد التنسيقات وتصدير الملف النهائي بصيغة CSV نظيفة.
النتائج والأثر (Impact)
تقليص وقت معالجة البيانات من ساعات (لو تمت يدوياً) إلى دقائق معدودة برمجياً بفضل الأتمتة.
الوصول لدقة عالية وتقليل الأخطاء البشرية بشكل كامل في تجهيز البيانات.
تم تنفيذ مسار البيانات بطريقة قابلة للتوسع (Scalable) للتعامل مع أحجام بيانات أكبر مستقبلاً بنفس الكفاءة وبدون تدخل يدوي.