نظام ذكاء اصطناعي متقدم لاكتشاف أخطاء التلاوة والتجويد (Audio AI & ASR)
تفاصيل العمل
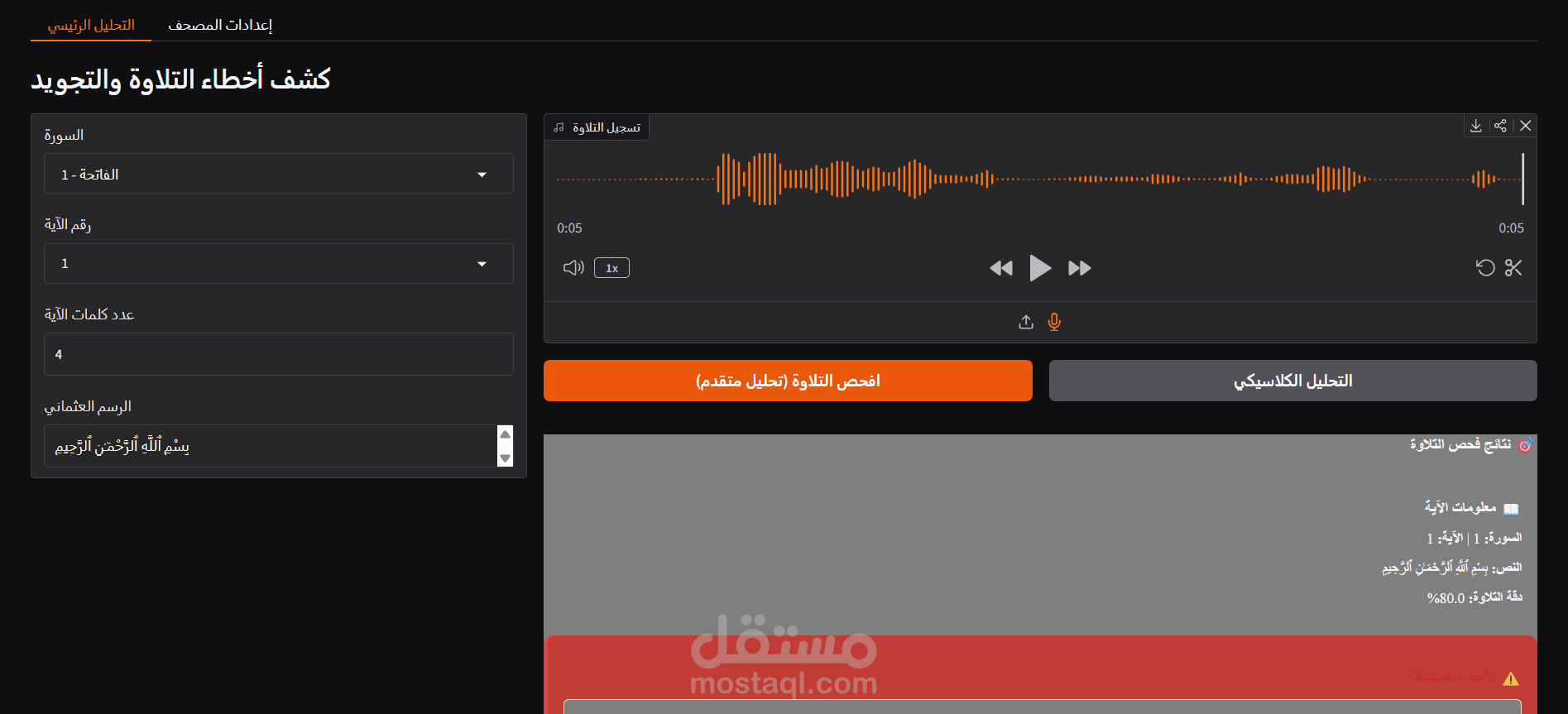
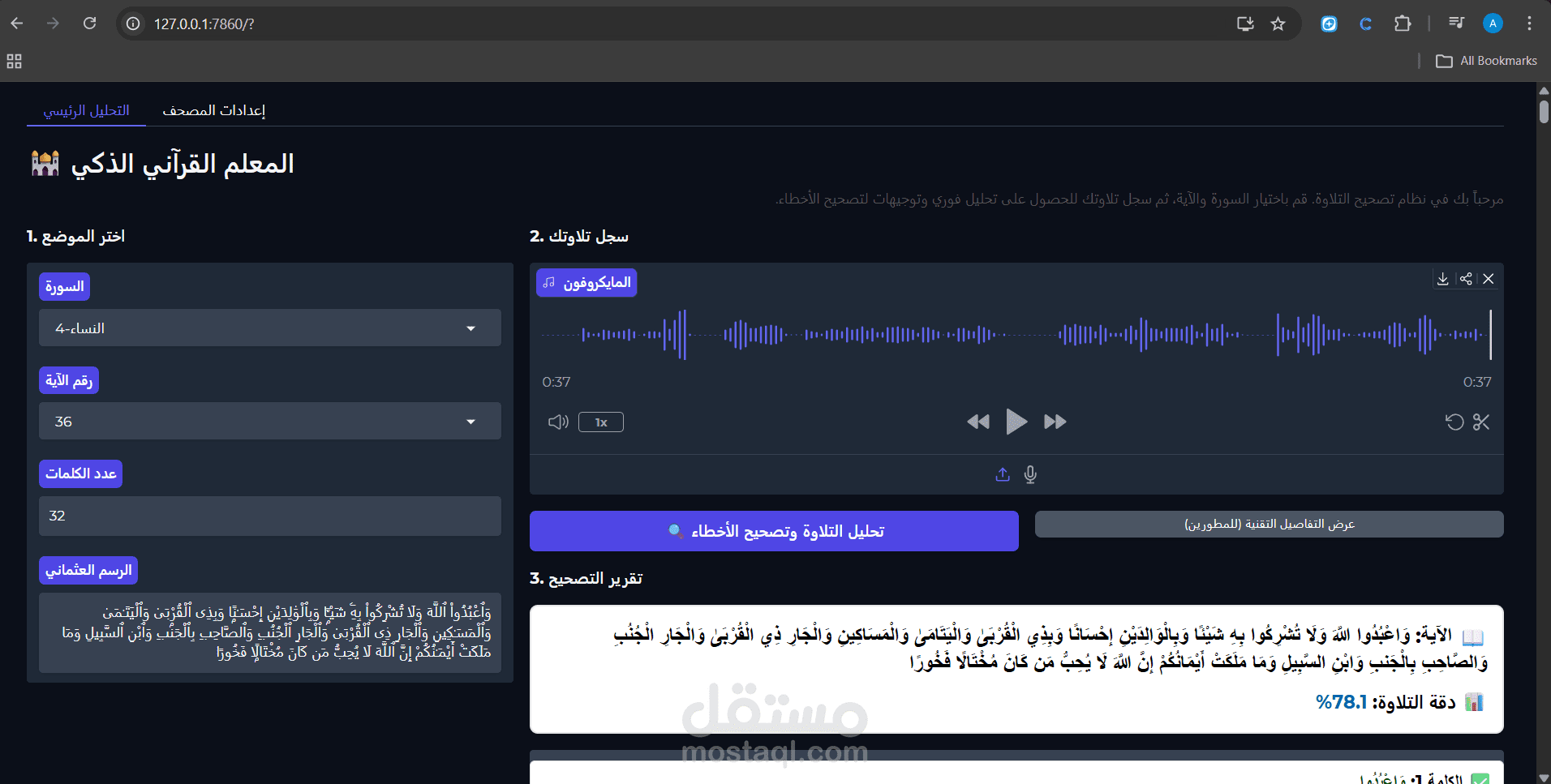
بناء وتطوير محرك ذكاء اصطناعي خلفي (AI Backend) متخصص في معالجة الصوتيات وتحليل تلاوة القرآن الكريم. يهدف النظام إلى استخراج وتحليل المقاطع الصوتية بدقة متناهية لاكتشاف وتعيين أخطاء النطق وأحكام التجويد آلياً، ليكون النواة الأساسية لتطبيقات التعليم الإلكتروني الذكية.
الميزات التقنية وطريقة التنفيذ:
معالجة الصوتيات المتقدمة: هندسة النظام باستخدام PyTorch و Librosa لمعالجة الملفات الصوتية، تنقيتها، واستخراج الميزات الصوتية (Audio Features) المعقدة منها بكفاءة عالية.
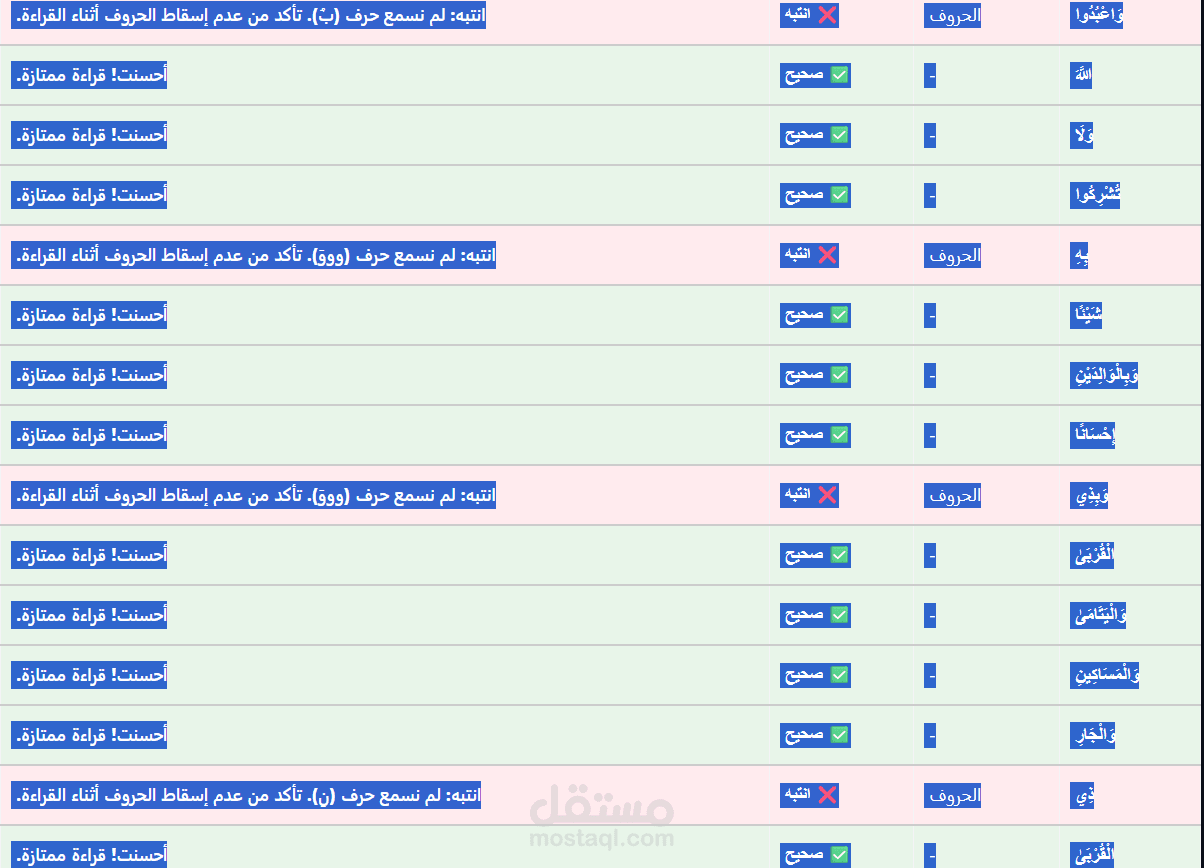
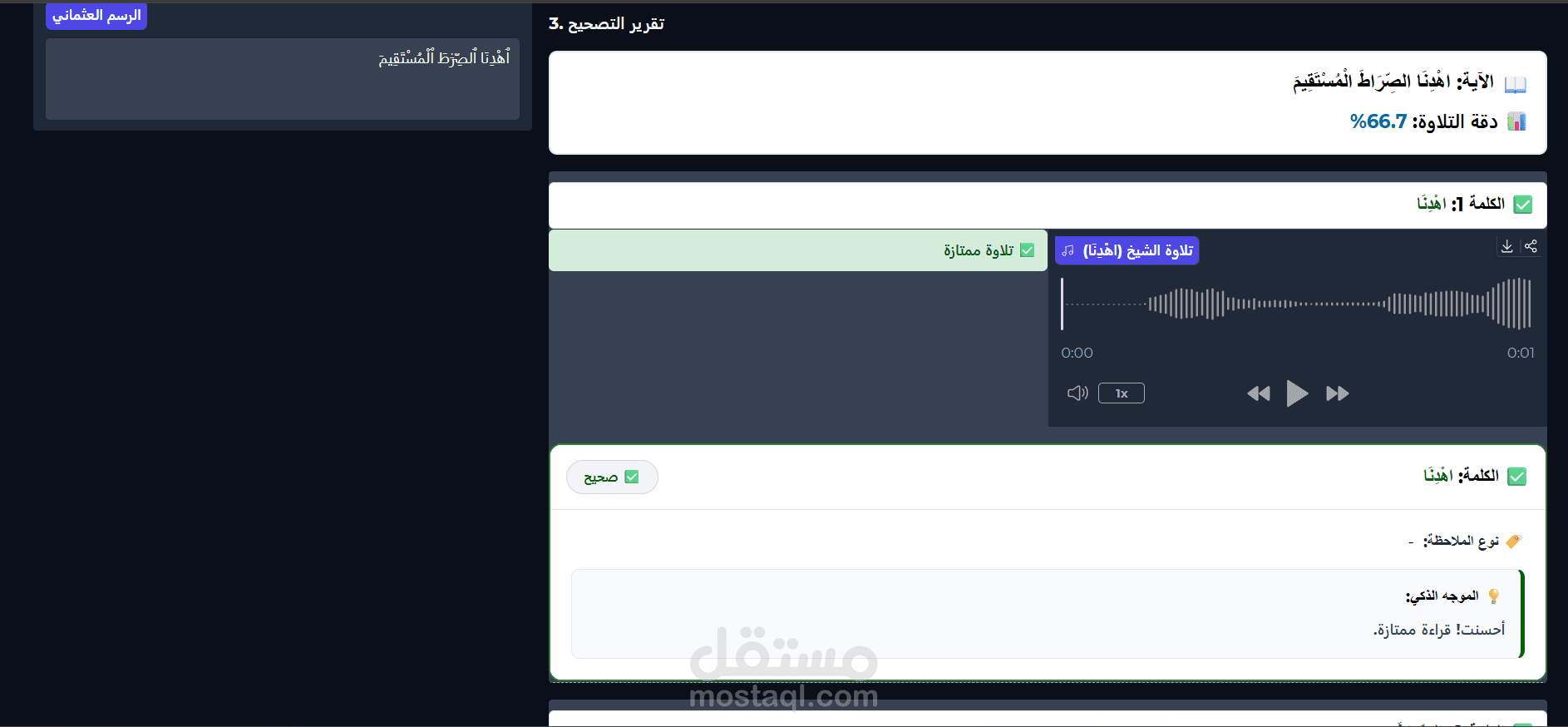
التحليل الدقيق على مستوى الحرف (Phoneme-level Detection): بدلاً من التحليل السطحي، قمت بتنفيذ تقنيات "التوافق القسري" (Forced Alignment) وأنظمة "التعرف التلقائي على الكلام" (ASR) لاكتشاف وتحديد أخطاء التلاوة بدقة على مستوى المقطع الصوتي الدقيق (مثل أخطاء الغنة، المدود، ومخارج الحروف).
واجهة برمجية فائقة السرعة: تطوير البنية التحتية الخلفية باستخدام FastAPI لضمان استقبال الملفات الصوتية، معالجتها عبر نماذج الذكاء الاصطناعي، وإرجاع تقارير الأخطاء للمستخدم في الوقت الفعلي (Real-time processing).
واجهات اختبار تفاعلية: تصميم واجهات باستخدام Gradio لاختبار وتصحيح استنتاجات النموذج (Model Inference) والمنطق الخاص بتجزئة الصوتيات (Segmented Alignment Logic).
الأثر وقيمة المشروع:
تحويل التقنيات المعقدة لمعالجة الصوت (Audio Processing) إلى واجهة برمجية سهلة الاستخدام (API).
تقديم حل تقني مبتكر وموثوق يمكن دمجه بسهولة في تطبيقات المنصات التعليمية لتقليل الجهد البشري في التقييم المبدئي للتلاوات.