منصة Agentic Scraper: أتمتة شاملة لجلب وتحليل الوظائف باستخدام Llama 3 و FastAPI
تفاصيل العمل
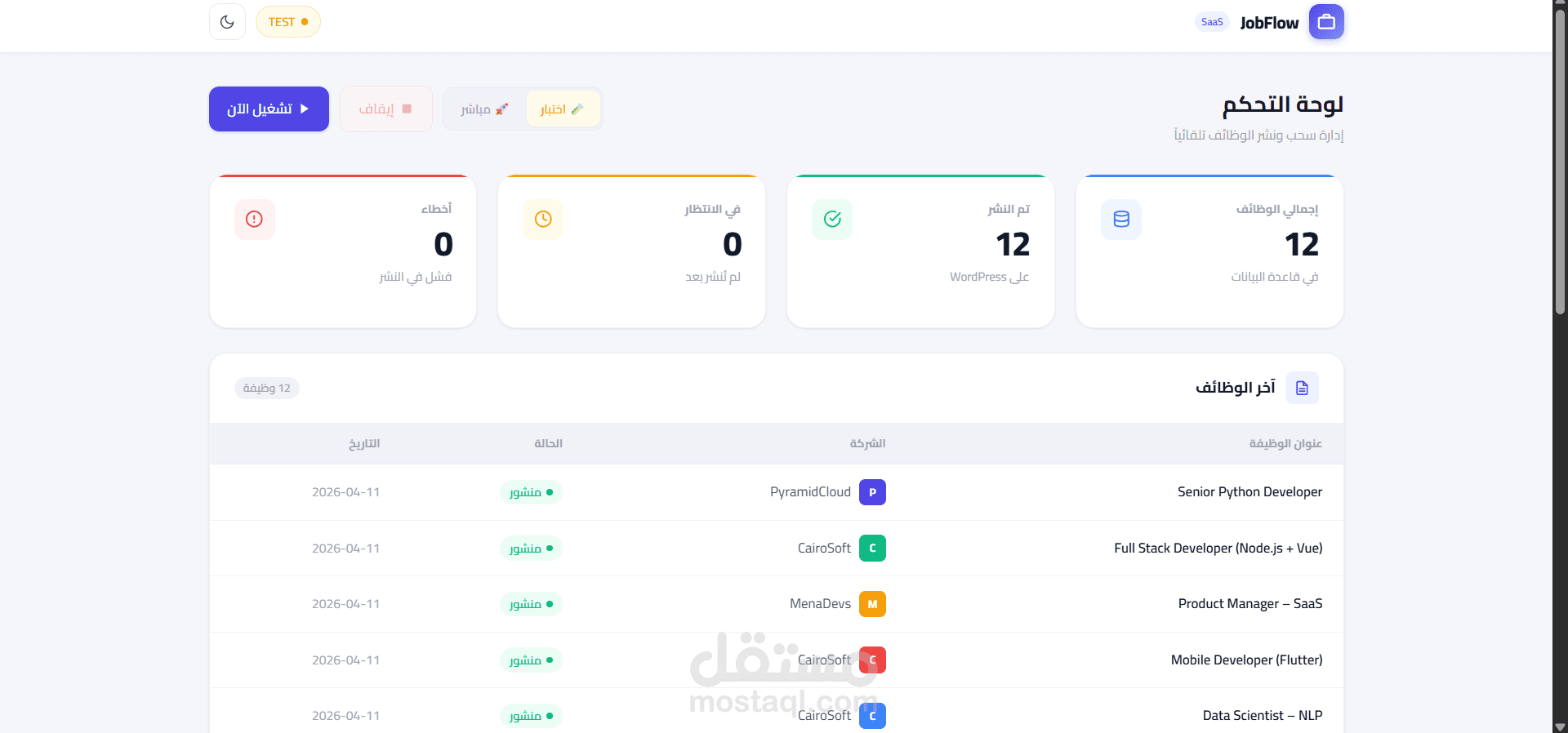
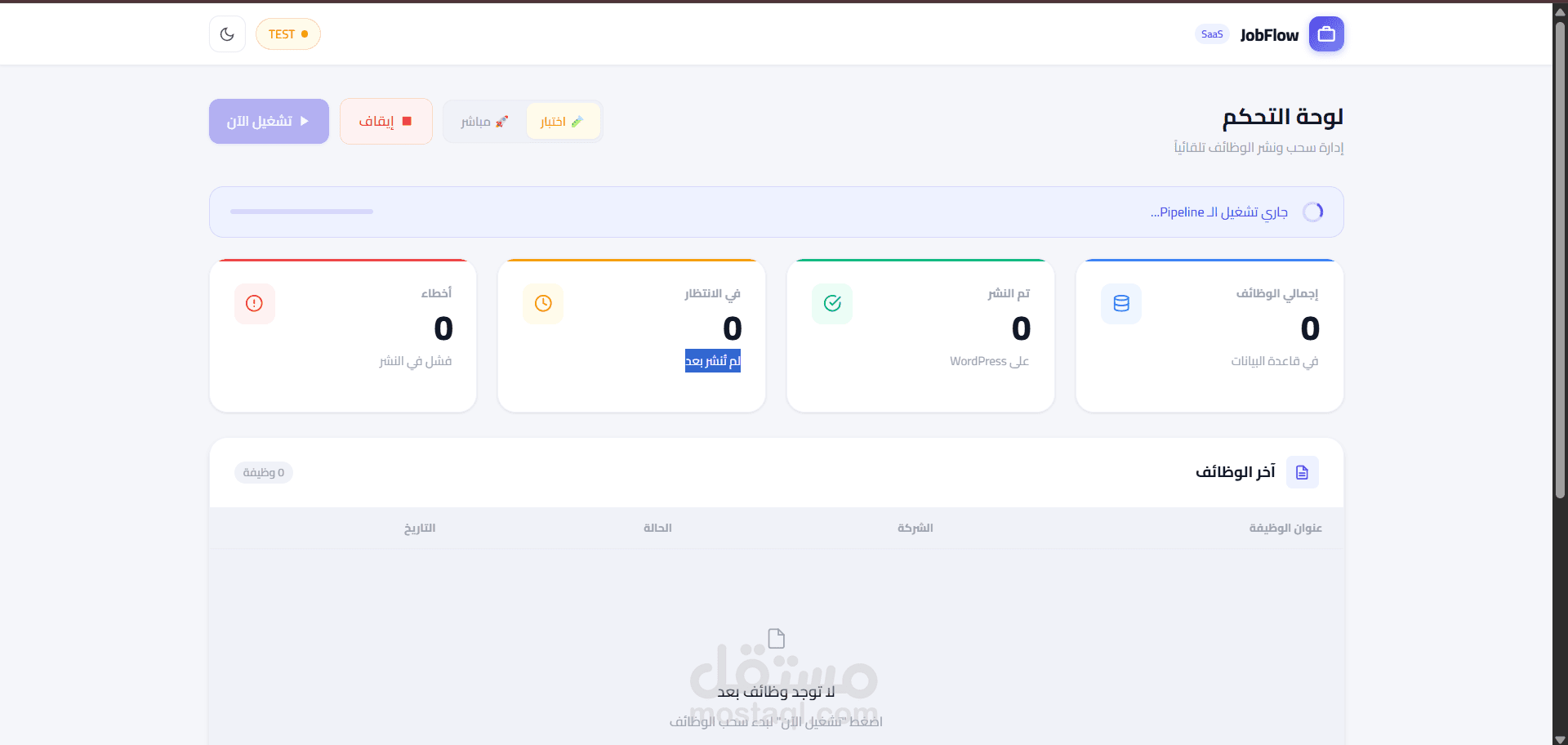
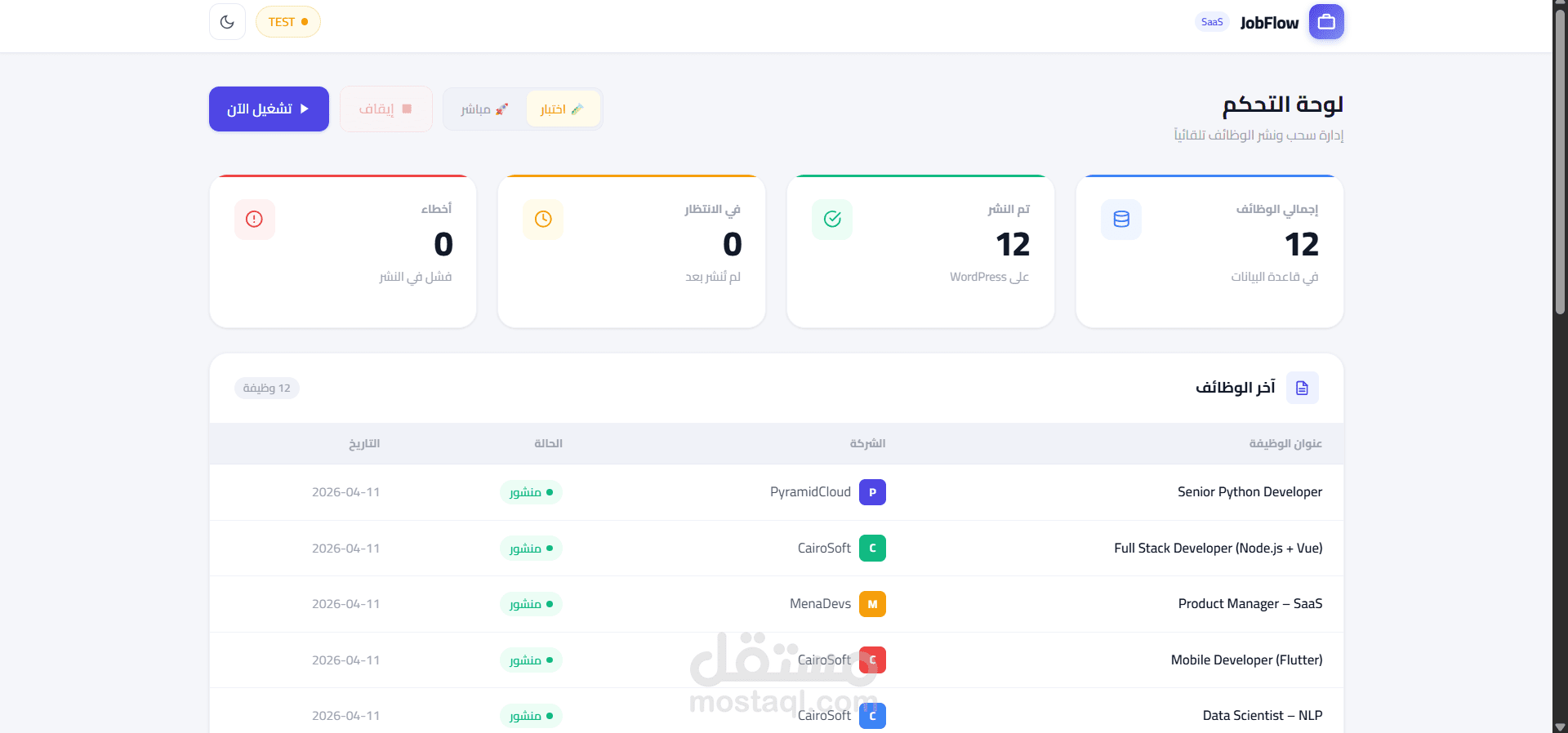
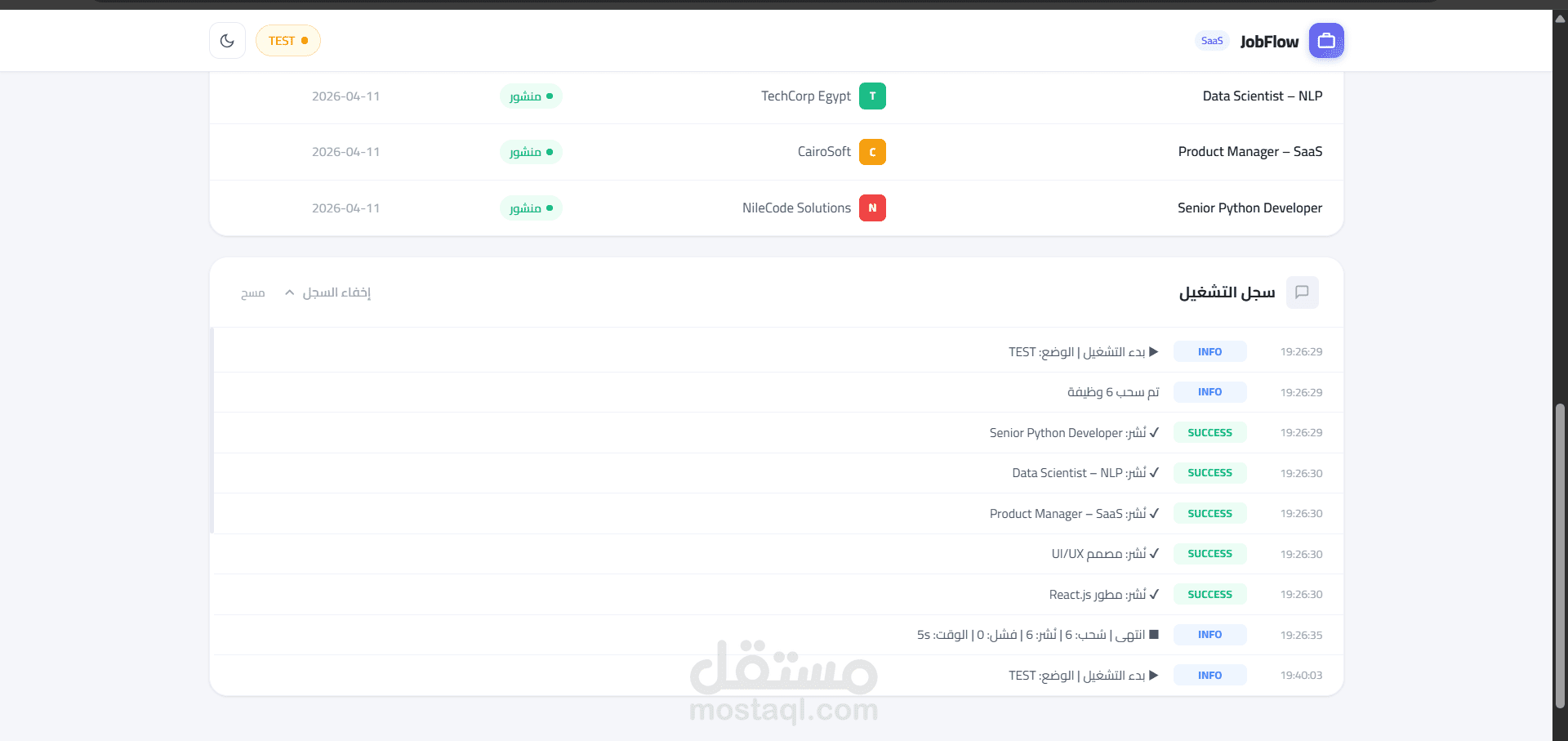
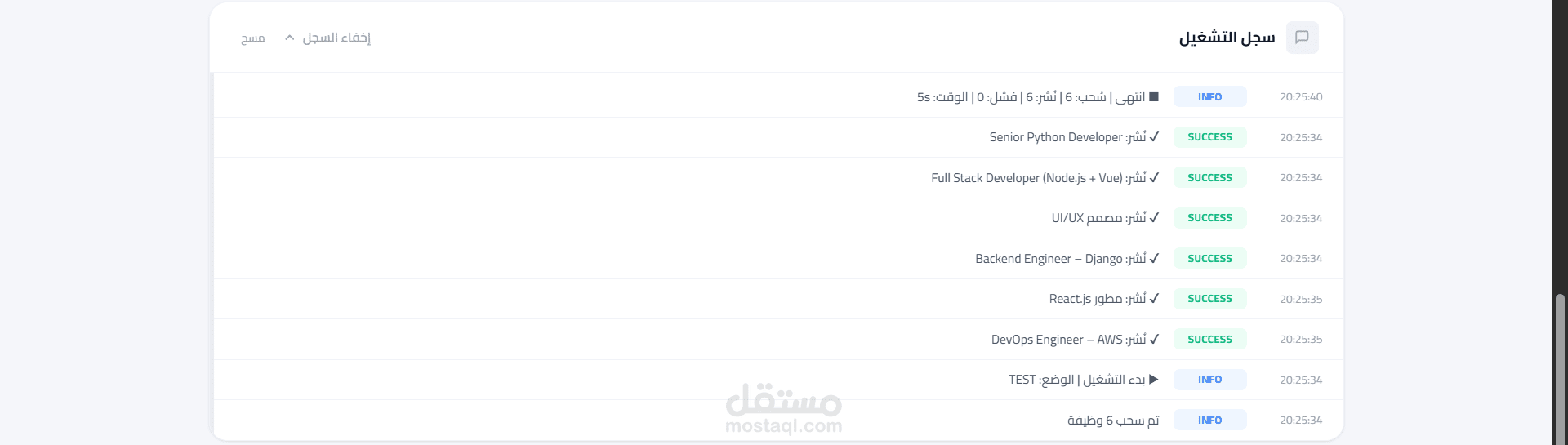
نظام Enterprise لأتمتة جلب البيانات الذكي والمعالجة اللغوية (Codex Pipeline)
هذا المشروع عبارة عن نظام متكامل (End-to-End Pipeline) مصمم لأتمتة عمليات جلب البيانات (Web Scraping) ومعالجتها باستخدام الذكاء الاصطناعي، وهو حل مثالي لمنصات المحتوى وشركات التوظيف التي تسعى للاعتماد الكامل على الأتمتة.
القدرات التقنية للنظام:
جلب البيانات الذكي: محرك سحب هجين يدمج بين Playwright و BeautifulSoup لتخطي حماية المواقع وجلب البيانات لحظياً من عدة مصادر متزامنة.
المعالجة بالذكاء الاصطناعي (LLMs): ربط كامل مع نماذج Llama 3 و GPT-4 لإعادة صياغة البيانات، ترجمتها، وتحويلها إلى محتوى HTML احترافي متوافق مع معايير الـ SEO.
إدارة وقواعد البيانات: نظام تخزين ذكي باستخدام SQLite يضمن عدم تكرار البيانات وسهولة استرجاعها.
لوحة تحكم (Dashboard): واجهة مستخدم متطورة مبنية بـ FastAPI لمراقبة النظام لحظياً عبر Live Logs والتحكم في أوضاع التشغيل (Live/Test).
لماذا يعتبر هذا النظام حلاً استراتيجياً؟
توفير الوقت: يقوم النظام في ثوانٍ بما يحتاج فريق كامل من مدخلي البيانات لأيام.
الدقة العالية: تقليل الخطأ البشري إلى الصفر بفضل المعالجة الآلية.
القابلية للتوسع: يمكن تطبيقه على أي مصدر بيانات أو ربطه بأي منصة نشر (مثل WordPress) بسهولة.