تنظيف وتحليل بيانات الرواتب (Data Cleaning & EDA) واكتشاف الرؤى باستخدام Python
تفاصيل العمل
بذة عن المشروع:
تنفيذ عملية معالجة وتحليل استكشافي (EDA) شاملة لمجموعة بيانات ضخمة ومعقدة خاصة برواتب الموظفين (Salaries Dataset). الهدف الأساسي من العمل كان تحويل البيانات الخام إلى بيانات نظيفة ومهيكلة، واستخراج رؤى (Insights) دقيقة تدعم الإجابة على أسئلة الأعمال وتساعد في فهم هيكل الأجور.
خطوات التنفيذ وأبرز ميزات العمل:
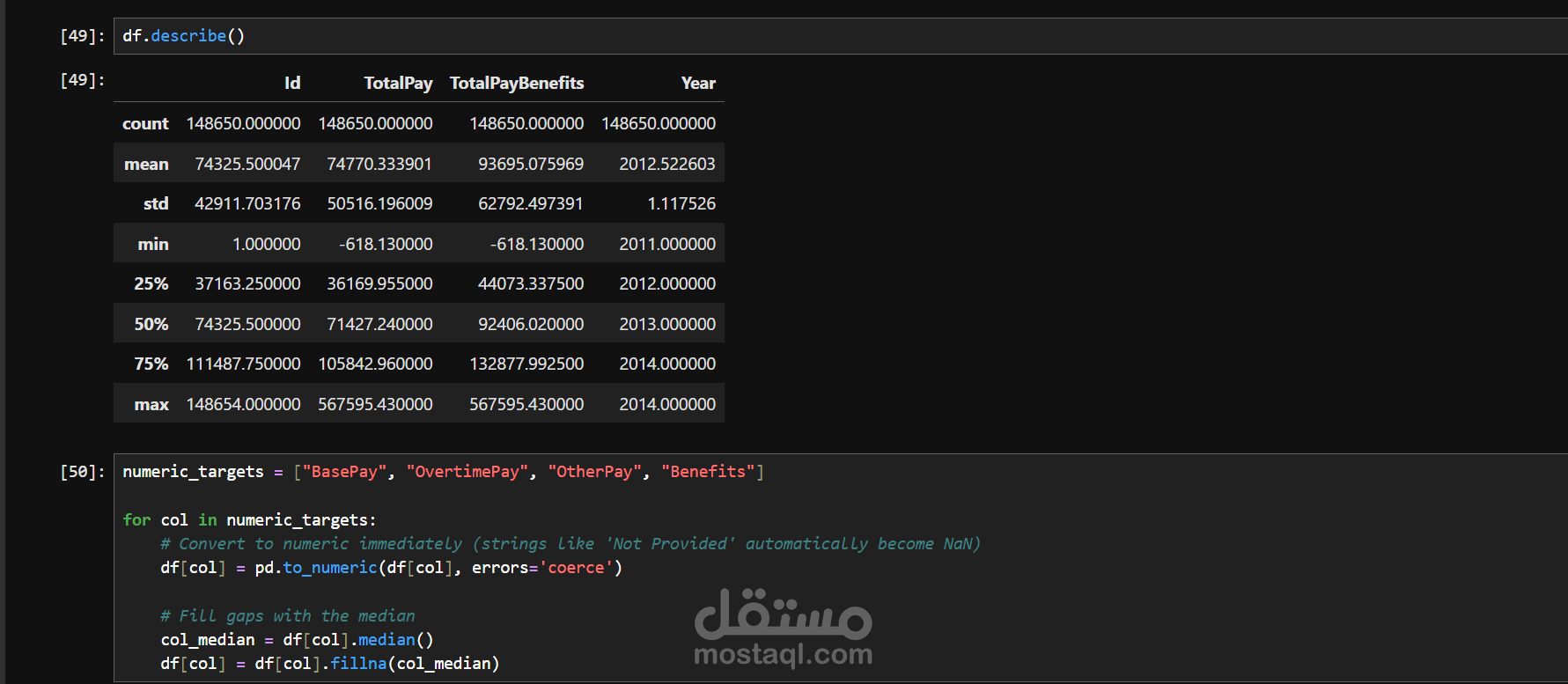
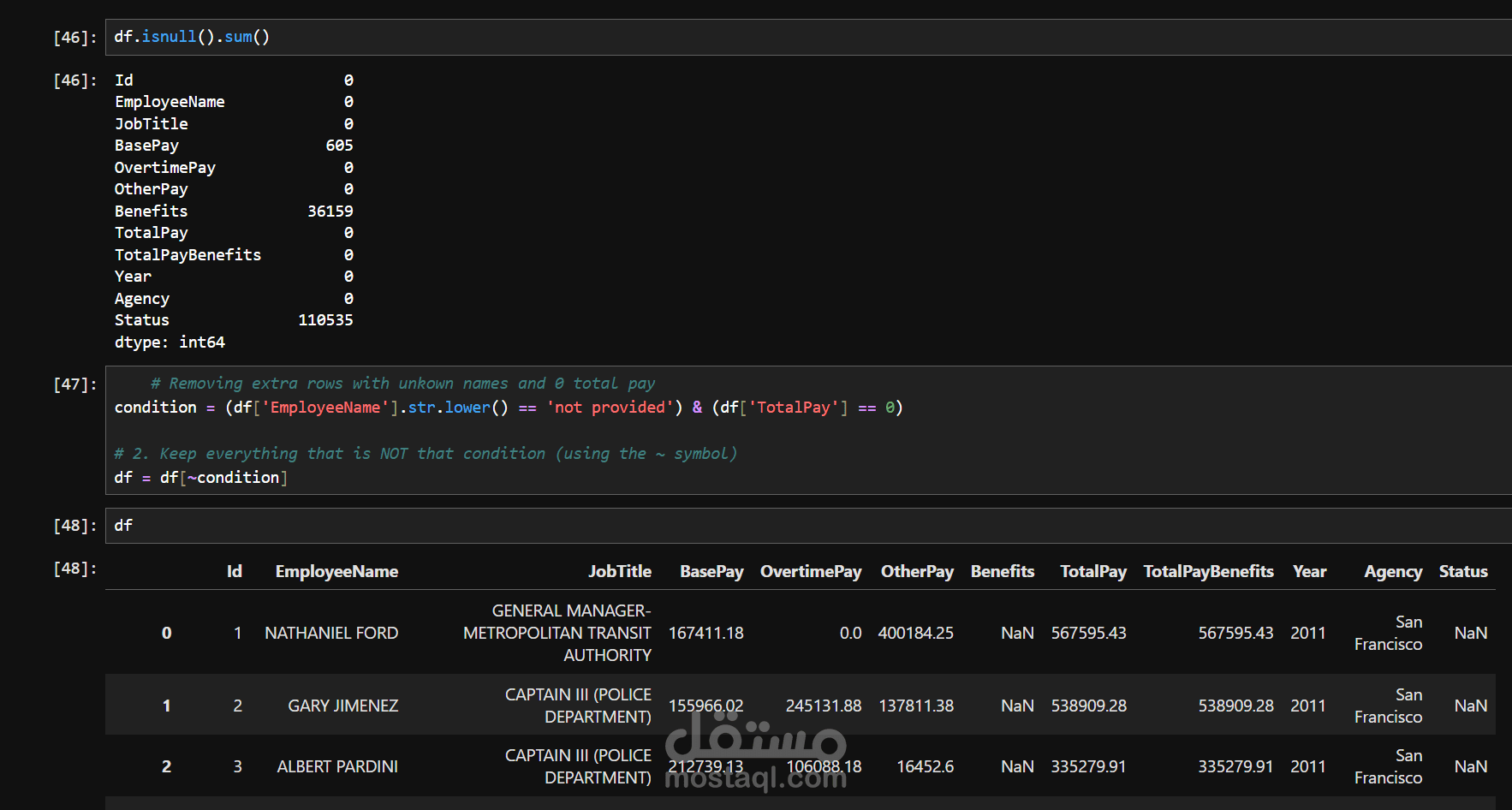
المعالجة المسبقة للبيانات (Data Preprocessing): * التعامل مع القيم المفقودة (Missing Values) باحترافية، حيث تم استبدال الفراغات في الأعمدة الرقمية (مثل الراتب الأساسي والفوائد) بالوسيط الحسابي (Median) لضمان دقة الإحصائيات وعدم تأثرها بالقيم المتطرفة.
معالجة القيم المفقودة في الأعمدة التصنيفية باستخدام المنوال (Mode).
تصحيح أنواع البيانات (Data Types) لتجنب الأخطاء البرمجية وتسهيل التحليل.
تنظيف البيانات (Data Cleaning):
فلترة البيانات واستبعاد السجلات غير المنطقية أو المبهمة (مثل السجلات التي لا تحتوي على اسم موظف وبإجمالي راتب 0).
التخلص من الأعمدة غير المؤثرة لتقليل حجم البيانات وتسريع الأداء.
التمثيل البصري واستخراج الرؤى (Data Visualization):
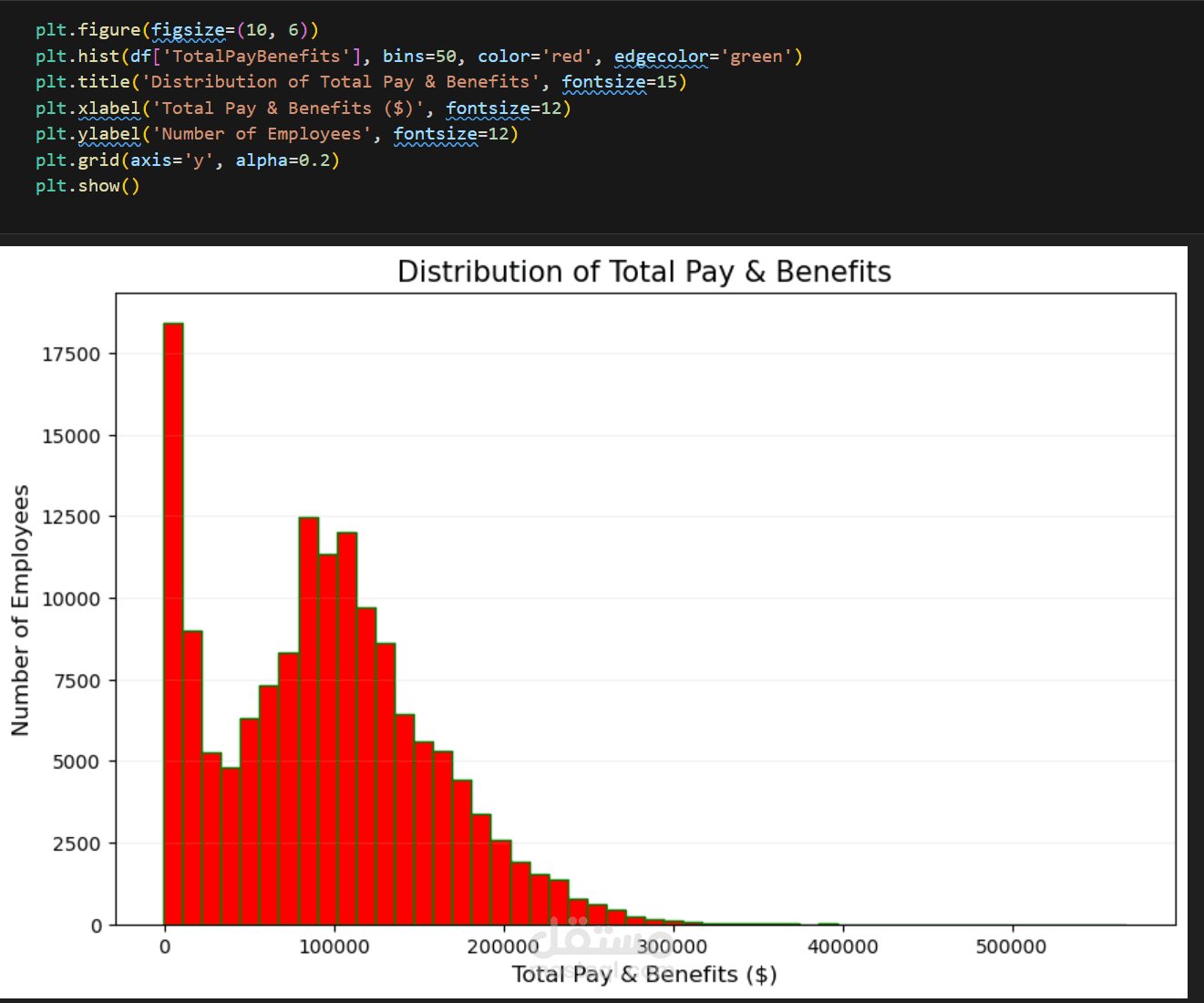
رسم مدرج تكراري (Histogram) لتحليل التوزيع الإحصائي لإجمالي الرواتب والفوائد.
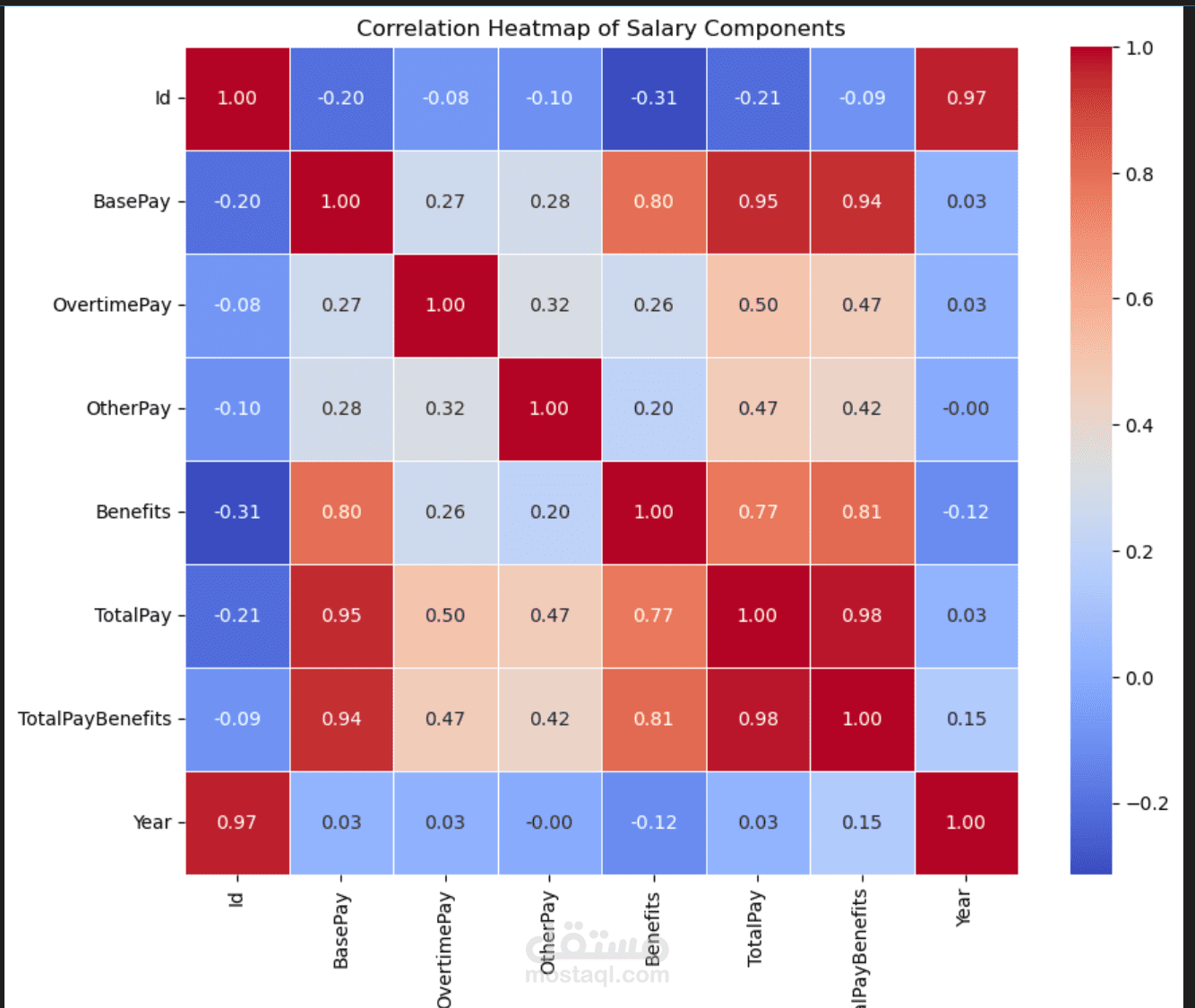
تصميم خريطة حرارية للارتباط (Correlation Heatmap) لاكتشاف وتوضيح قوة العلاقة بين المكونات المختلفة للراتب (مثل العلاقة بين الراتب الأساسي، العمل الإضافي، وإجمالي الدخل).
الأدوات والتقنيات المستخدمة:
لغة البرمجة: Python
معالجة البيانات: Pandas, NumPy
التمثيل البصري: Matplotlib, Seaborn
هذا العمل يعكس القدرة على التعامل مع البيانات الواقعية المليئة بالتحديات، وتطبيق التفكير المنطقي السليم لتحويلها إلى معلومات قيمة جاهزة للتحليل المتقدم.