Hierarchical MDP: Treasure Hunt
تفاصيل العمل
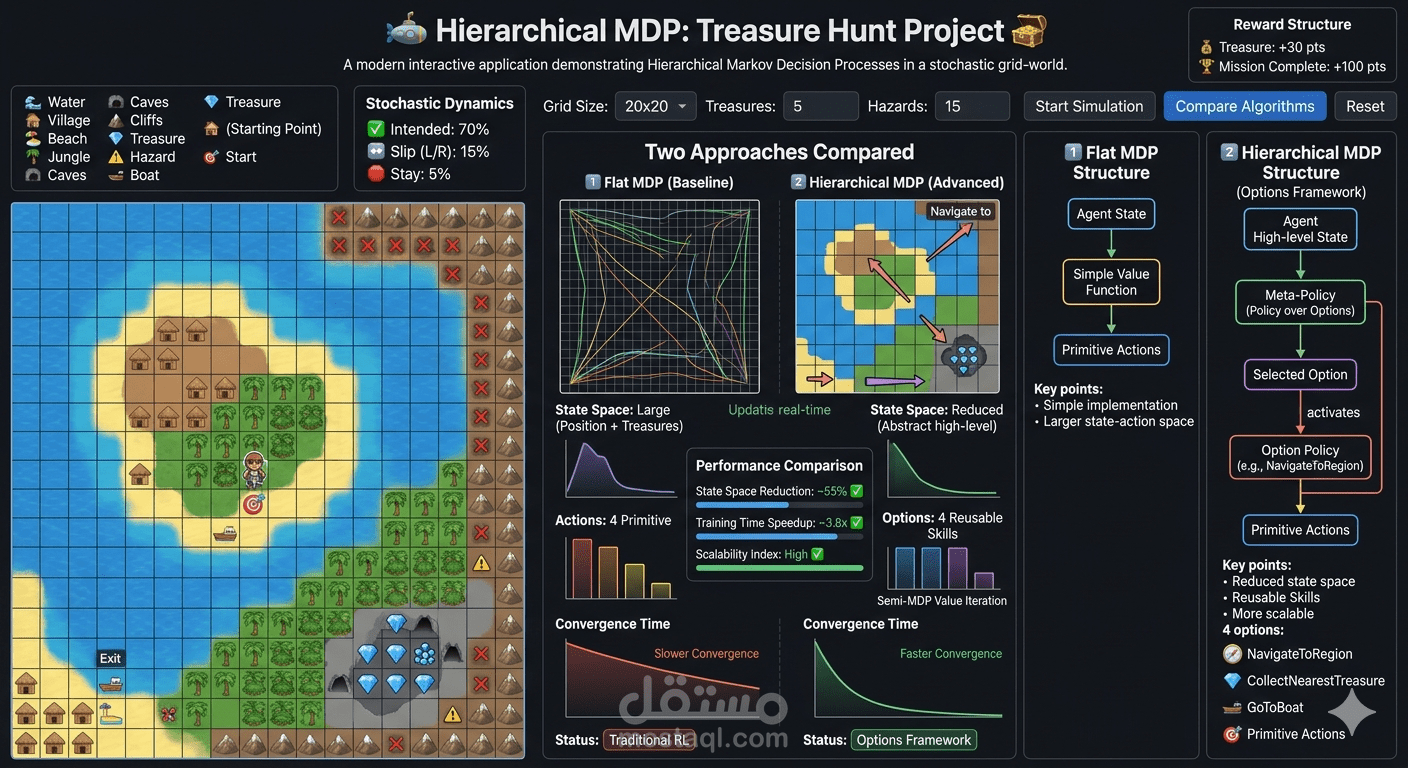
A modern interactive application demonstrating Hierarchical Markov Decision Processes through an engaging treasure hunt scenario in a stochastic grid-world environment.
Grid World
Size: Configurable (default 20×20 cells)
Regions: 6 distinct terrain types
? Water - Surrounding ocean
?️ Village - Starting point
?️ Beach - Boat exit location
? Jungle - Dense vegetation
?️ Caves - Treasure locations
?️ Cliffs - Dangerous terrain
Game Elements
? Treasures: 3-8 collectible items (clustered in caves)
⚠️ Hazards: Traps, cliffs, quicksand (~15 obstacles)
? Boat: Exit point at beach (reachable only with all treasures)
? Start: Agent begins in village area
Stochastic Dynamics
Actions are uncertain due to environmental factors:
✅ Intended direction: 70% probability
↔️ Slip perpendicular: 15% left, 15% right
? Stay in place: 5% probability (blocked/stuck)
Reward Structure
? Treasure collected: +30 points
? Mission complete (boat with all treasures): +100 points
?️ Architecture
Two Approaches Compared
1️⃣ Flat MDP (Baseline)
Traditional reinforcement learning approach:
State Space: Position + collected treasures
Actions: 4 primitive movements (North, South, East, West)
Algorithm: Standard value iteration
Characteristics:
Simple implementation
Larger state-action space
Slower convergence
2️⃣ Hierarchical MDP (Advanced)
Temporal abstraction using the Options framework:
State Space: Abstract high-level states
Options: 4 reusable skills/behaviors
? NavigateToRegion: Move to caves or beach
? CollectNearestTreasure: Gather nearby treasures
? GoToBoat: Navigate to exit
? Primitive Actions: Fallback low-level controls
Algorithm: Semi-MDP value iteration
Characteristics:
Reduced state space
Faster convergence
More scalable
Key Advantages of Hierarchical Approach
✅ State Space Reduction: ~40-60% fewer states
✅ Training Time Speedup: 2-5x faster convergence
✅ Better Scalability: Handles larger environments efficiently
✅ Reusable Skills: Options can transfer to similar tasks