web scraping
تفاصيل العمل

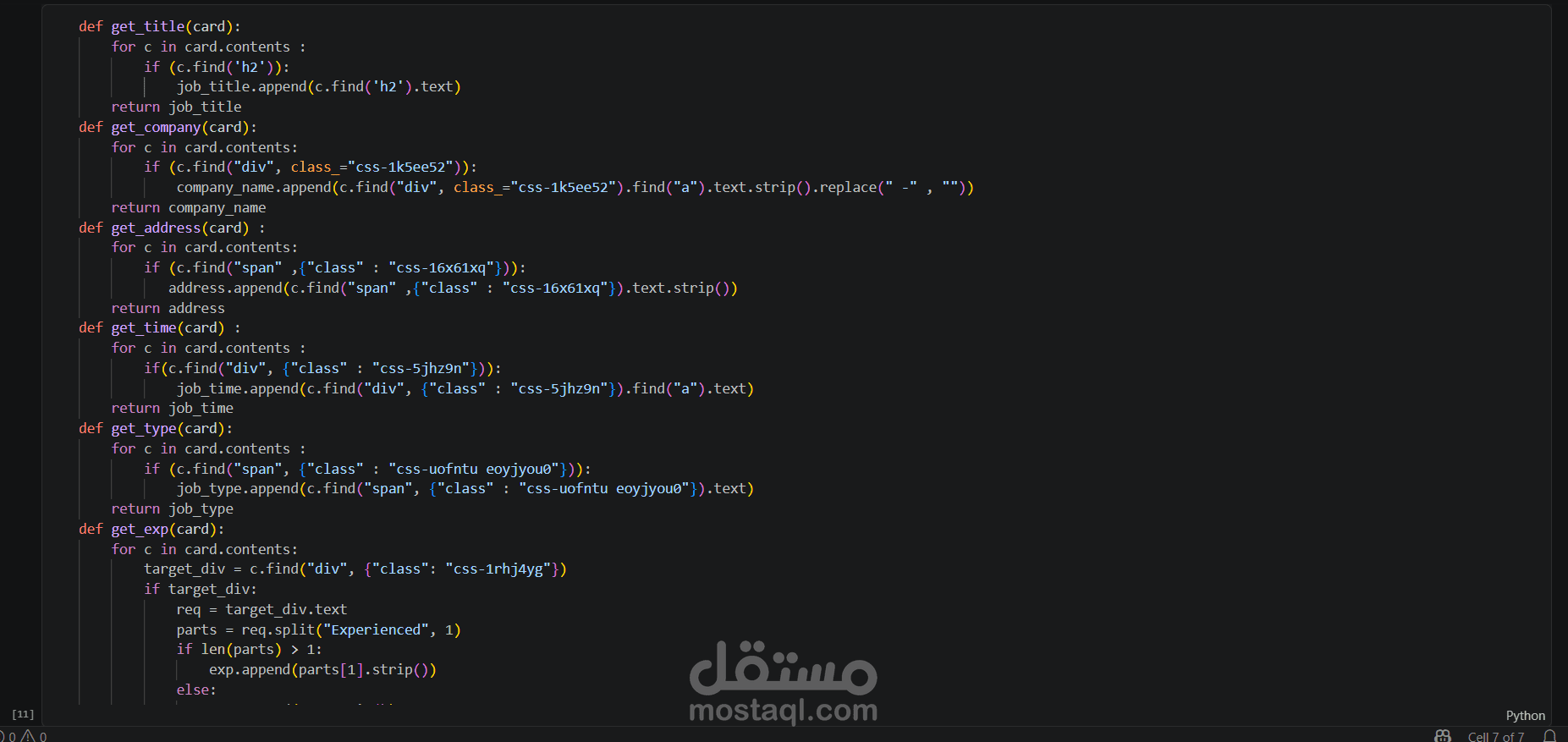
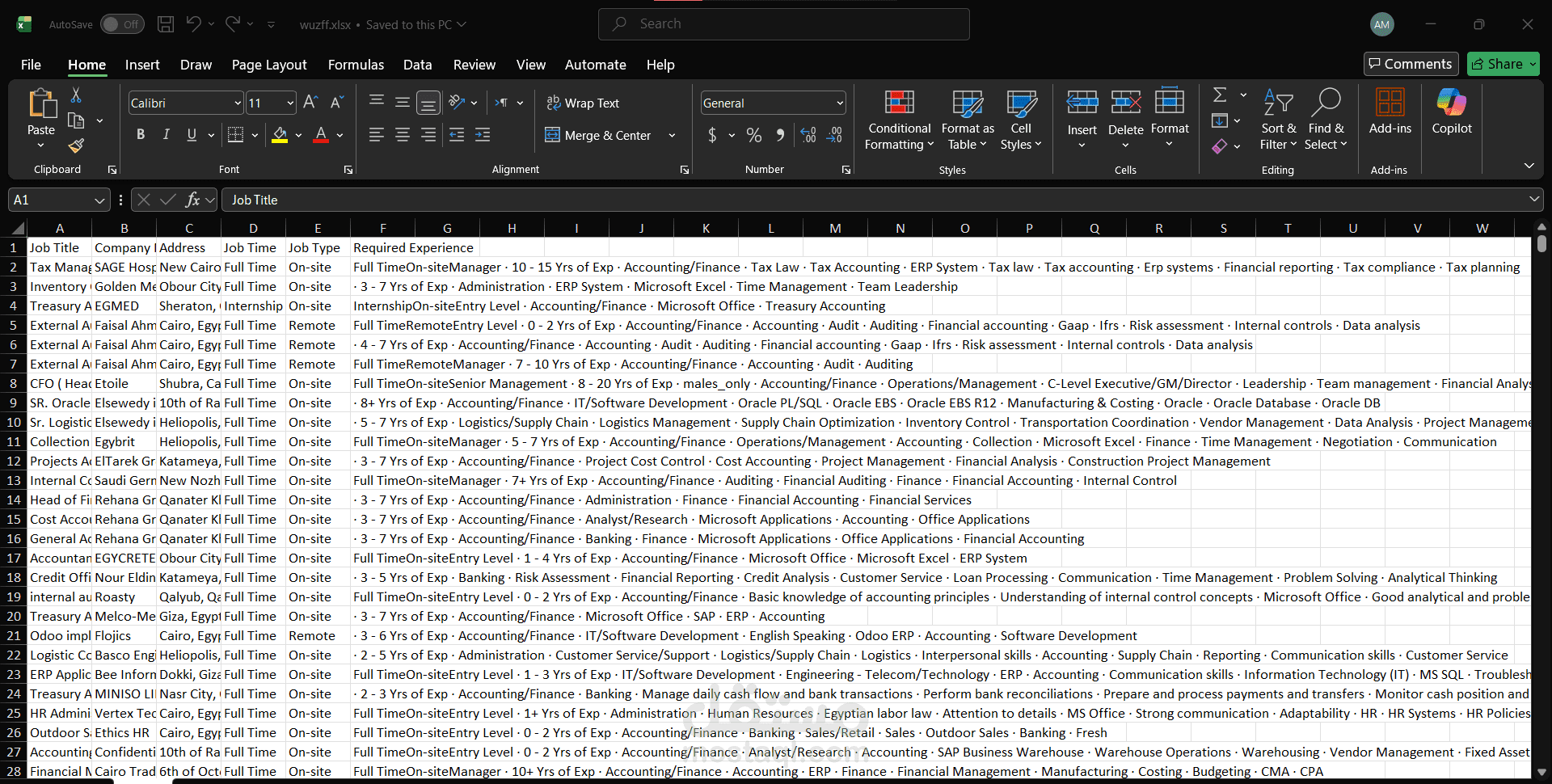
قمت بتنفيذ مشروع لاستخراج بيانات الوظائف من موقع Wuzzuf باستخدام تقنيات Web Scraping بلغة Python.
هدف المشروع
الهدف كان جمع بيانات الوظائف بشكل تلقائي بدل الإدخال اليدوي، لاستخدامها لاحقًا في:
تحليل سوق العمل
معرفة المهارات المطلوبة
بناء نماذج Data Science
الأدوات المستخدمة
Python
BeautifulSoup → لتحليل صفحات HTML
Requests → لجلب صفحات الموقع
Pandas → لتنظيم البيانات
خطوات العمل
إرسال طلب للموقع (Request)
استخدمت مكتبة Requests للحصول على محتوى الصفحة.
تحليل الصفحة (Parsing)
استخدمت BeautifulSoup لاستخراج العناصر المهمة مثل:
عنوان الوظيفة
اسم الشركة
مكان العمل
نوع الوظيفة
استخراج البيانات
حددت العناصر باستخدام class أو tags داخل HTML
خزّنت البيانات في Lists
تنظيم البيانات
استخدمت Pandas لتحويل البيانات إلى DataFrame
حفظ البيانات
حفظت النتائج في ملف CSV لاستخدامها لاحقًا
مثال على البيانات المستخرجة
Job Title: Data Analyst
Company: XYZ
Location: Cairo
Skills: Python, SQL
التحديات
تغير هيكل الموقع (HTML structure)
بعض البيانات تكون ناقصة
الحاجة للتعامل مع pagination (أكثر من صفحة)
النتيجة
تمكنت من:
استخراج عدد كبير من الوظائف تلقائيًا
إنشاء Dataset جاهزة للتحليل
استخدام البيانات لاحقًا في مشاريع Machine Learning
الخلاصة
المشروع ساعدني على:
فهم Web Scraping بشكل عملي
التعامل مع البيانات الحقيقية
الربط بين Data Collection و Data Science