Products Data Pipeline
تفاصيل العمل
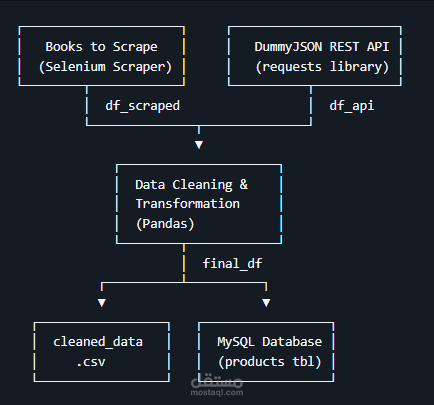
This project implements a fully automated data pipeline that:
Scrapes book titles and prices from Books to Scrape using Selenium
Ingests product data from the DummyJSON REST API
Cleans & merges both datasets using Pandas (deduplication, type casting, null handling)
Exports the final dataset to a CSV file
Loads the cleaned data into a MySQL database