نموذج تصنيف الفطر الصالح للأكل والسام باستخدام تعلم الآلة
تفاصيل العمل
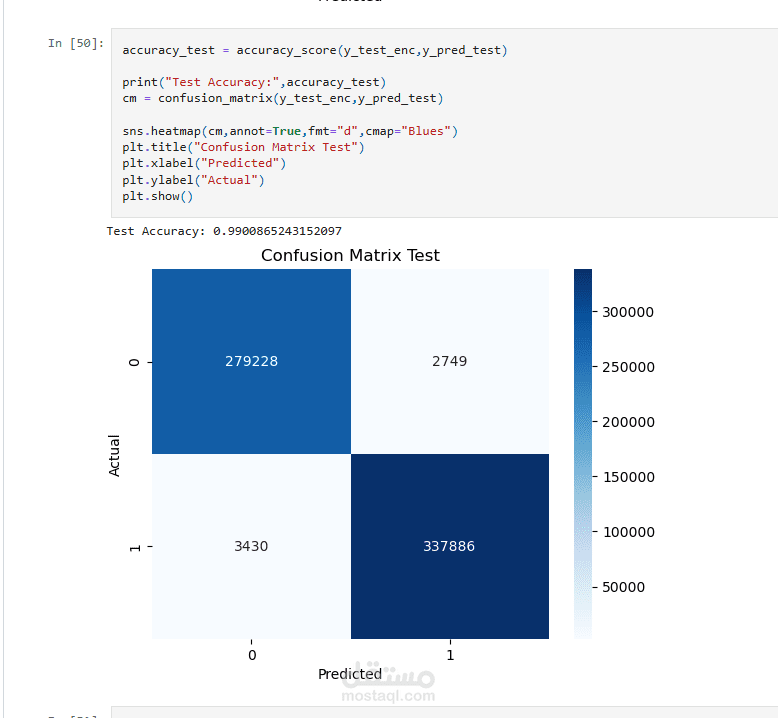
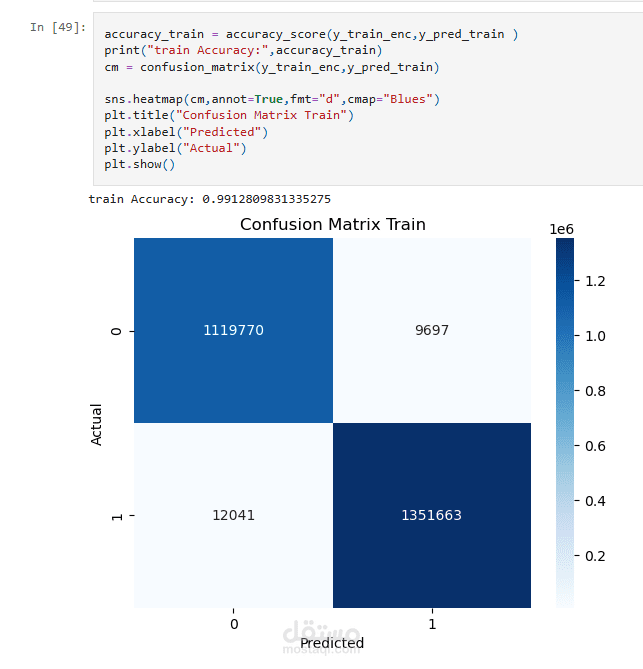
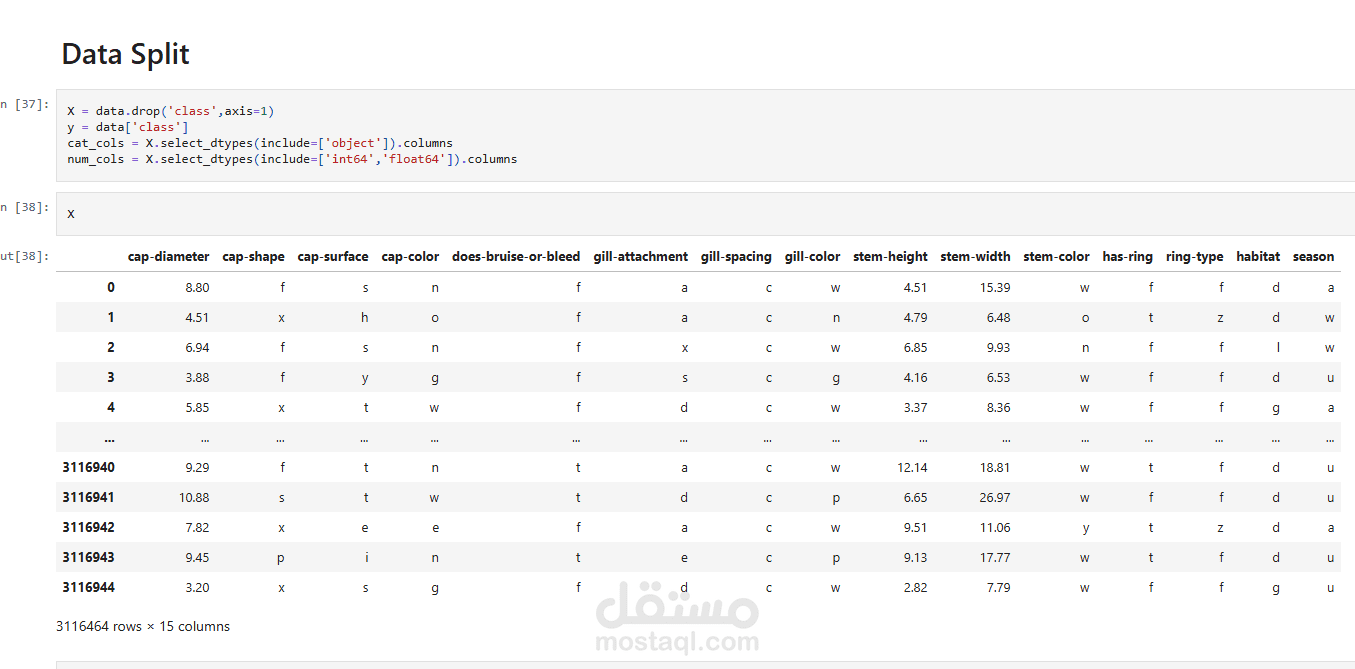

تم تطوير نموذج تعلم آلي للتنبؤ بما إذا كان الفطر صالحًا للأكل أو سامًا اعتمادًا على خصائصه الفيزيائية.
شملت خطوات العمل ما يلي:
معالجة البيانات المفقودة باستخدام أساليب مناسبة مثل تعويض القيم الفارغة وإضافة فئة "غير معروف".
تنظيف البيانات وإزالة الأعمدة ذات القيم المفقودة المرتفعة لتحسين جودة البيانات.
تطبيق تقنيات ترميز البيانات (Encoding) لتحويل المتغيرات الفئوية إلى قيم عددية قابلة للاستخدام.
إجراء التحليل الاستكشافي للبيانات (EDA) لفهم العلاقات بين الخصائص المختلفة.
بناء وتدريب عدة نماذج تعلم آلي مثل Decision Tree و Random Forest.
تقييم النماذج واختيار الأفضل من حيث الأداء والدقة.
حقق المشروع نتائج جيدة في تصنيف العينات بدقة عالية، مما يعكس كفاءة النموذج في التمييز بين الفطر الصالح والسام.