K-Means Clustering Model for Data Segmentation
تفاصيل العمل
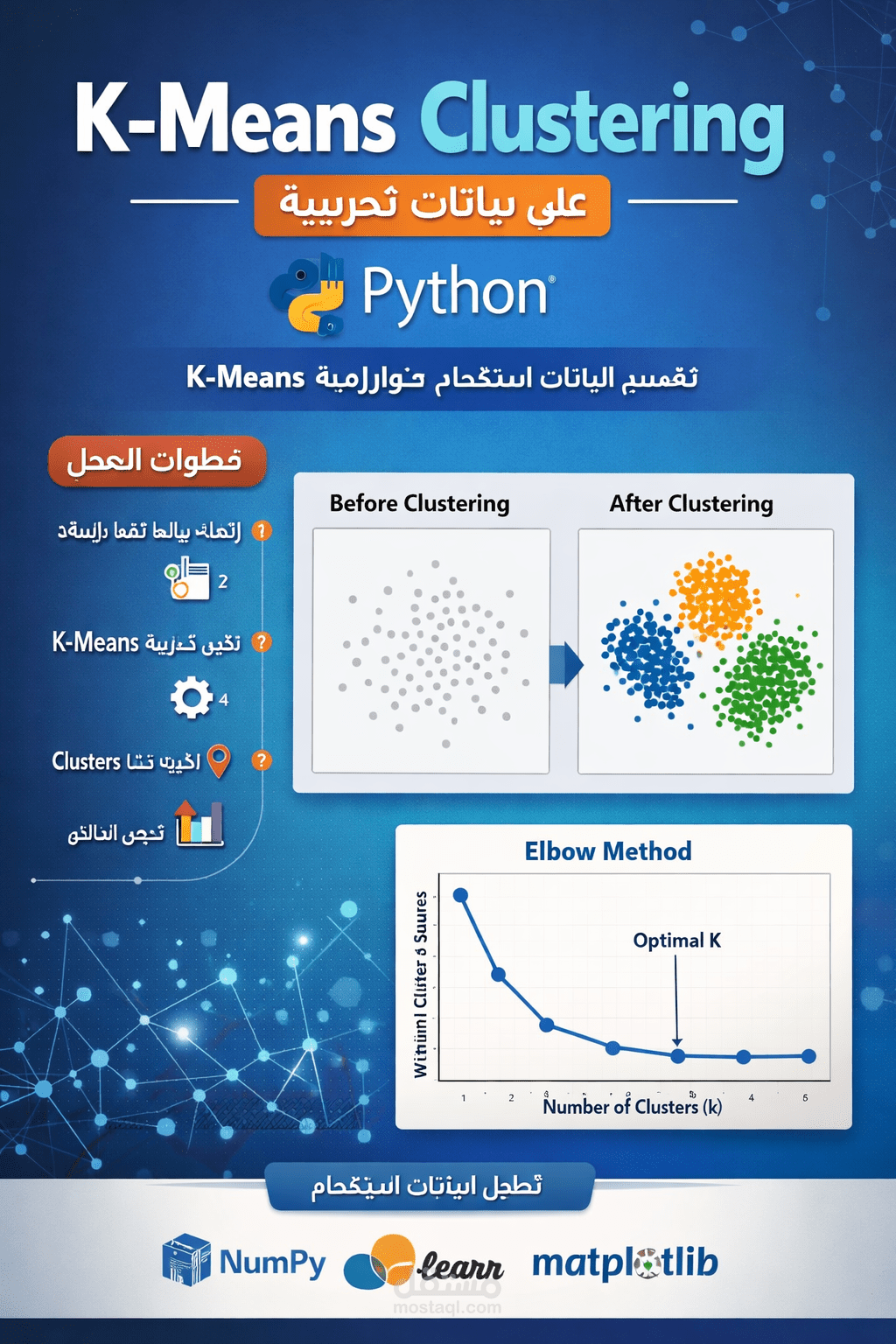
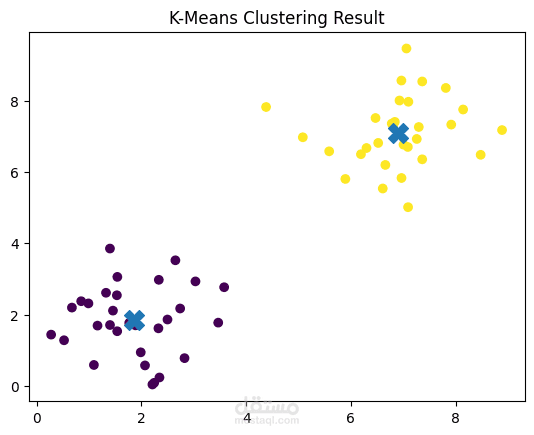
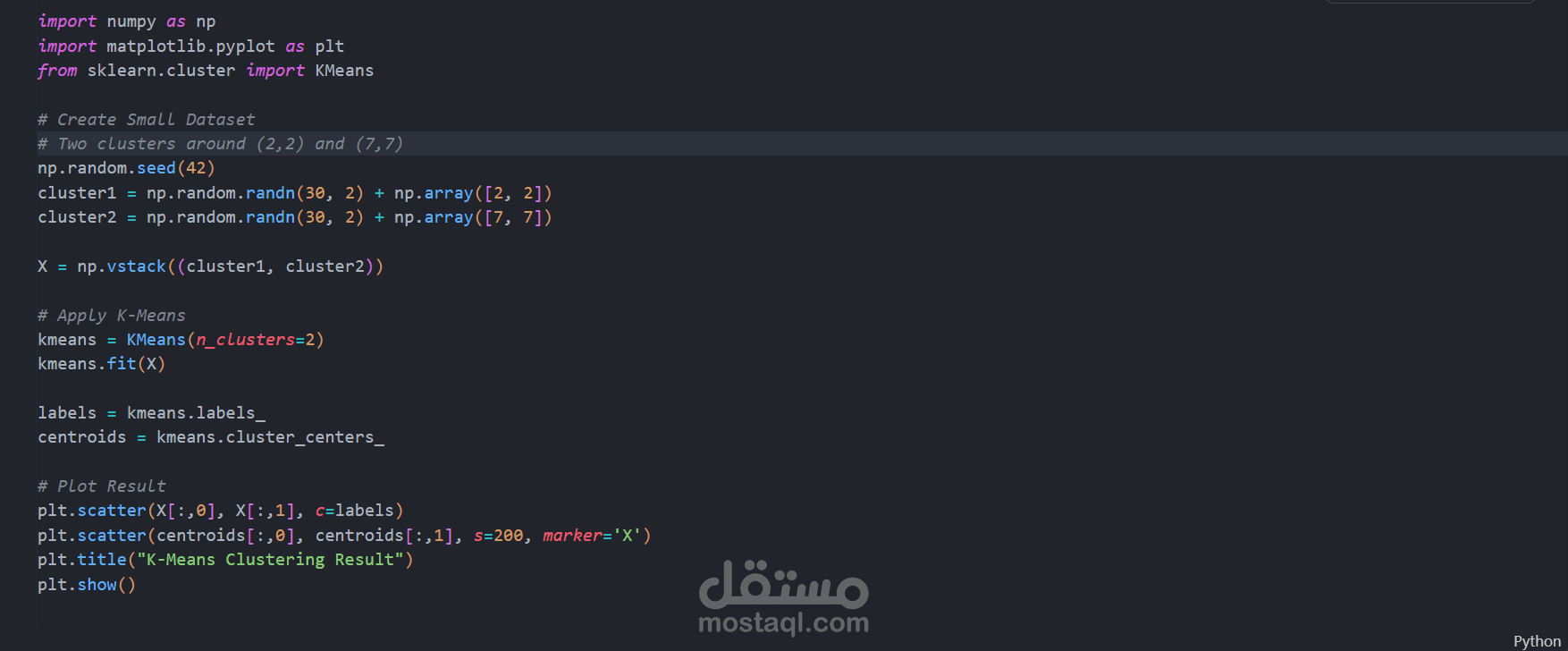
قمت بتنفيذ نموذج K-Means Clustering على بيانات تجريبية (Synthetic Data) تم إنشاؤها باستخدام قيم عشوائية لمحاكاة سيناريوهات حقيقية.
شمل العمل:
إنشاء بيانات ثنائية الأبعاد (X, Y) باستخدام القيم العشوائية
تطبيق خوارزمية K-Means لتجميع البيانات
تحديد عدد الـ Clusters المناسب
عرض النتائج باستخدام الرسوم البيانية (Data Visualization)
الهدف من المشروع هو فهم وتطبيق تقنيات Unsupervised Learning وتحليل كيفية تقسيم البيانات إلى مجموعات بناءً على التشابه بينها.
تم تنفيذ المشروع باستخدام Python ومكتبات مثل:
Pandas - NumPy - Scikit-learn - Matplotlib
يمكن استخدام نفس الفكرة في تطبيقات مثل تقسيم العملاء (Customer Segmentation) وتحليل البيانات.