هندسة ومعالجة البيانات الضخمة لسوق Steam: نظام ETL متكامل باستخدام Spark و Hadoop
تفاصيل العمل
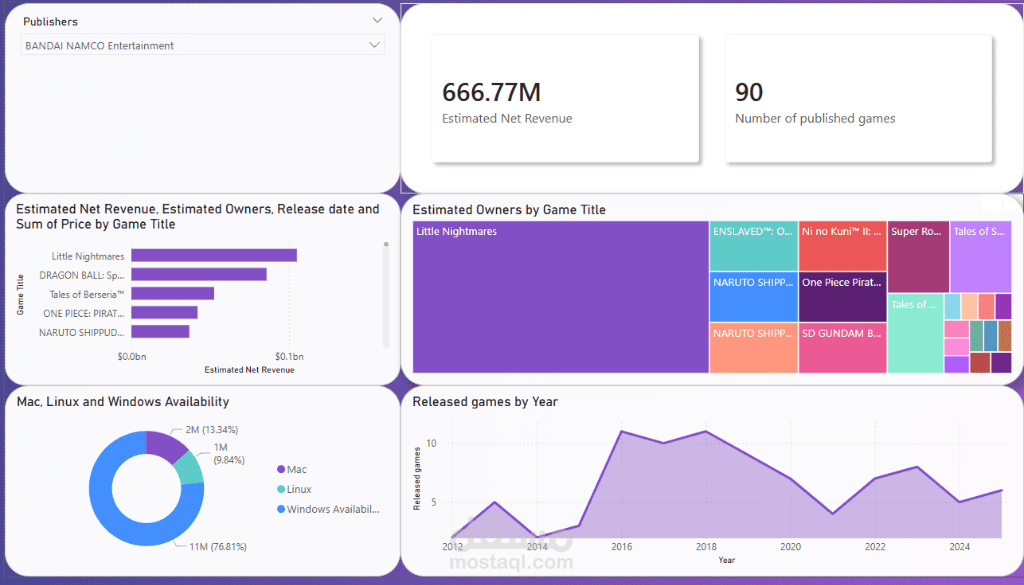
يتناول هذا المشروع التحدي التقني المتمثل في التعامل مع بيانات سوق "Steam" التي تمتاز بالسرعة والضخامة. قمت ببناء بيئة عمل متكاملة تعتمد على تقنيات Big Data لتحويل ملايين السجلات الخام إلى معلومات منظمة وقابلة للتحليل الاستراتيجي.
أبرز ملامح العمل التقني:
المعالجة الموزعة عبر Spark: بدلاً من الاعتماد على المعالجة التقليدية، استخدمت قوة Apache Spark لتوزيع عمليات التنظيف والتحليل على عدة وحدات معالجة، مما يقلل وقت التنفيذ من ساعات إلى دقائق معدودة.
بنية تحتية مرنة باستخدام Docker: قمت بتنفيذ النظام بالكامل داخل حاويات Docker، بما في ذلك عُقد (Nodes) الـ Hadoop والـ Spark، مما يضمن استقرار النظام وسهولة نقله أو توسيعه مستقبلاً ليشمل خوادم متعددة.
إدارة التخزين عبر HDFS: تم استخدام نظام ملفات Hadoop (HDFS) كطبقة تخزين وسيطة للبيانات غير المنظمة، مما يوفر قدرة عالية على استرجاع البيانات وتحمل الأخطاء البرمجية (Fault Tolerance).
الأتمتة من المصدر إلى التحليل: يبدأ النظام باستخراج بيانات السوق، مروراً بمراحل التصفية والهيكلة المعقدة، وانتهاءً بتخزينها في قاعدة بيانات PostgreSQL بشكل مهيأ تماماً لعمليات الاستعلام المتقدمة ولوحات المعلومات (Dashboards).
يعد هذا المشروع برهاناً عملياً على القدرة على تصميم وإدارة أنظمة البيانات المعقدة التي تتطلب فهماً عميقاً لهيكلة الأنظمة (System Architecture) وكيفية التعامل مع تدفقات البيانات الضخمة التي تفشل الأنظمة التقليدية في معالجتها.