NLP(Spam or not)
تفاصيل العمل
مشروع متكامل في مجال معالجة اللغة الطبيعية (Natural Language Processing - NLP) يهدف إلى تحليل النصوص واستخراج المعلومات المهمة منها، بالإضافة إلى بناء نموذج تعلم آلي لفهم النصوص والتنبؤ بناءً عليها.
تفاصيل العمل:
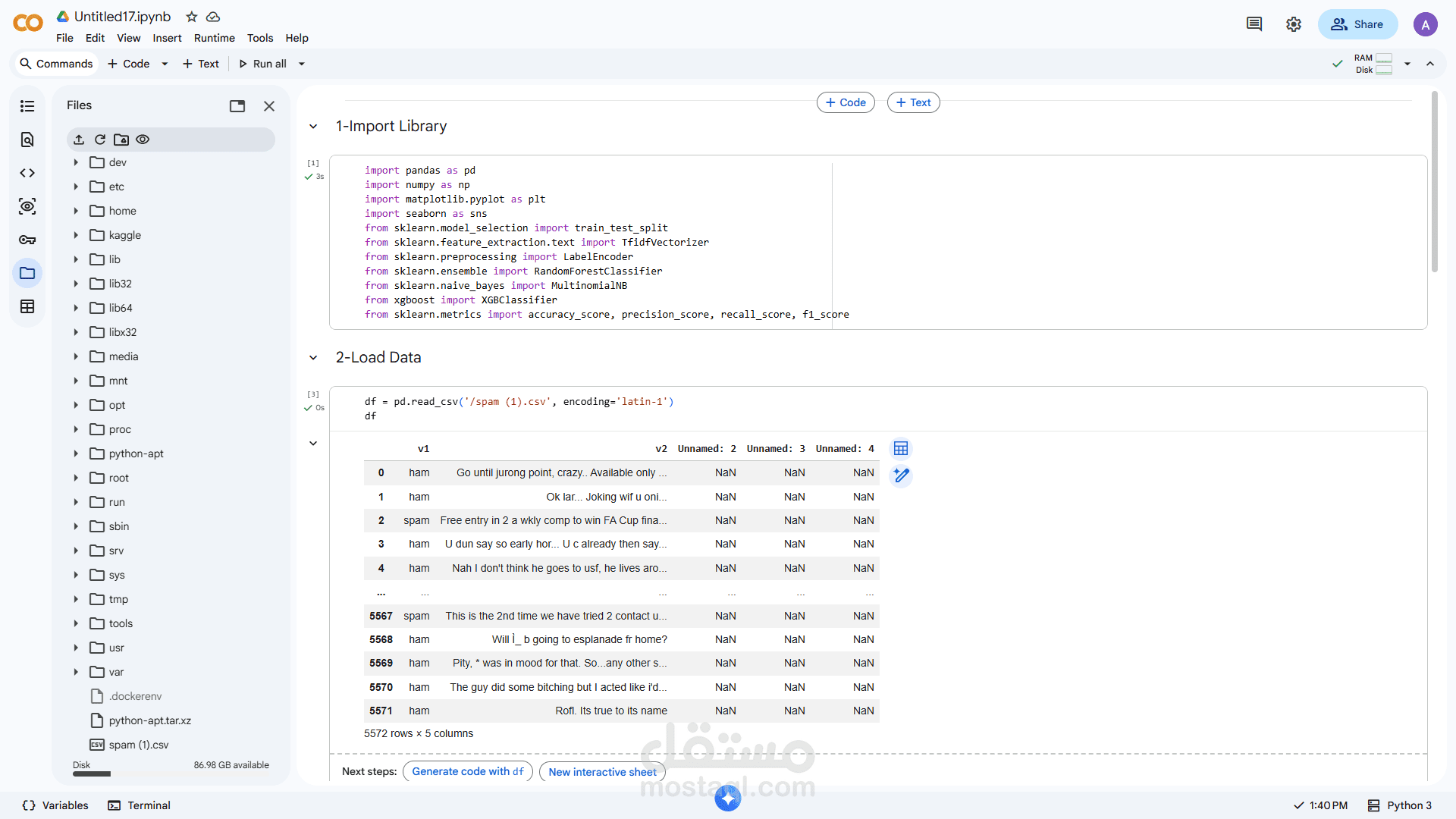
1. تجهيز ومعالجة النصوص:
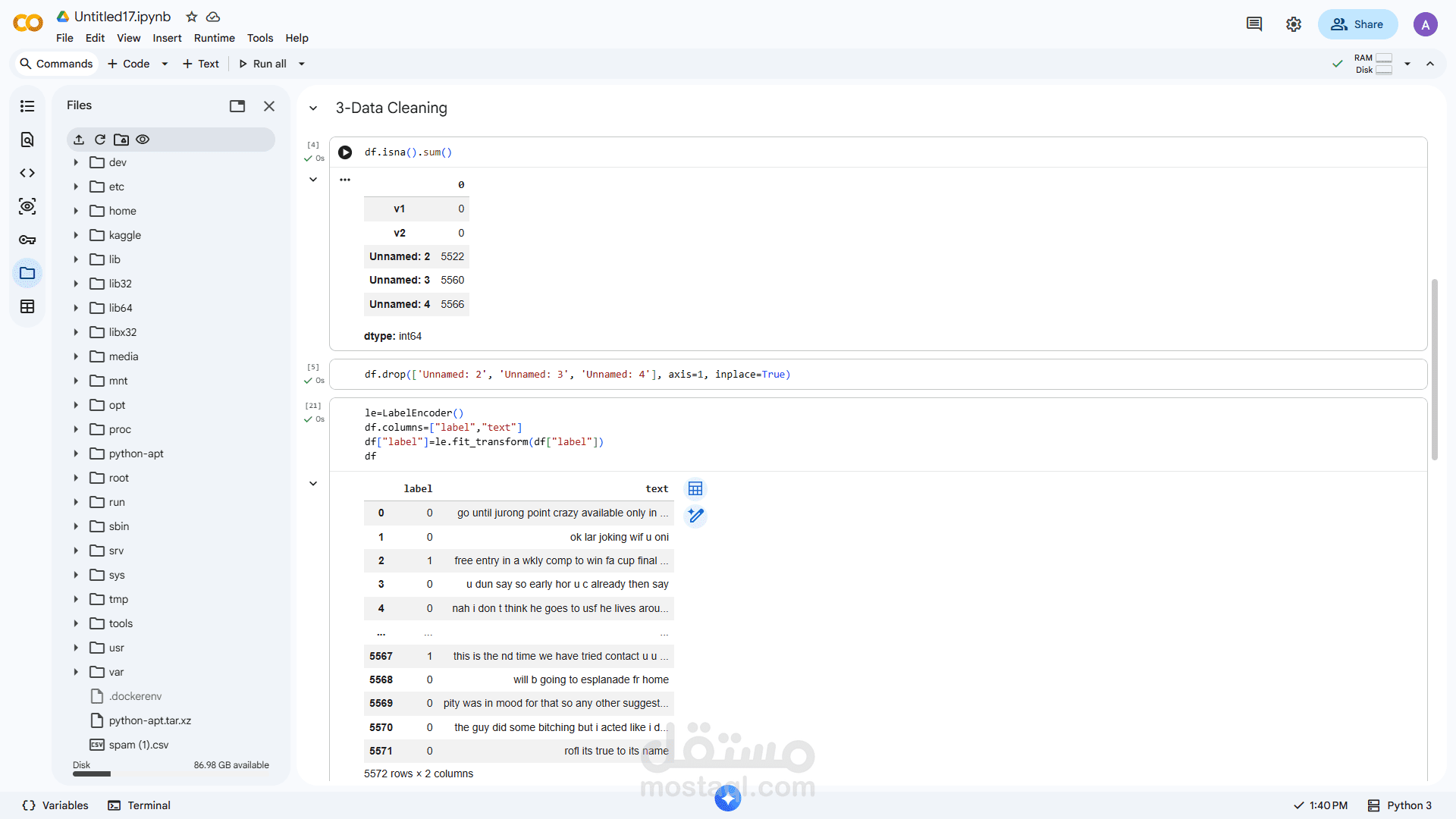
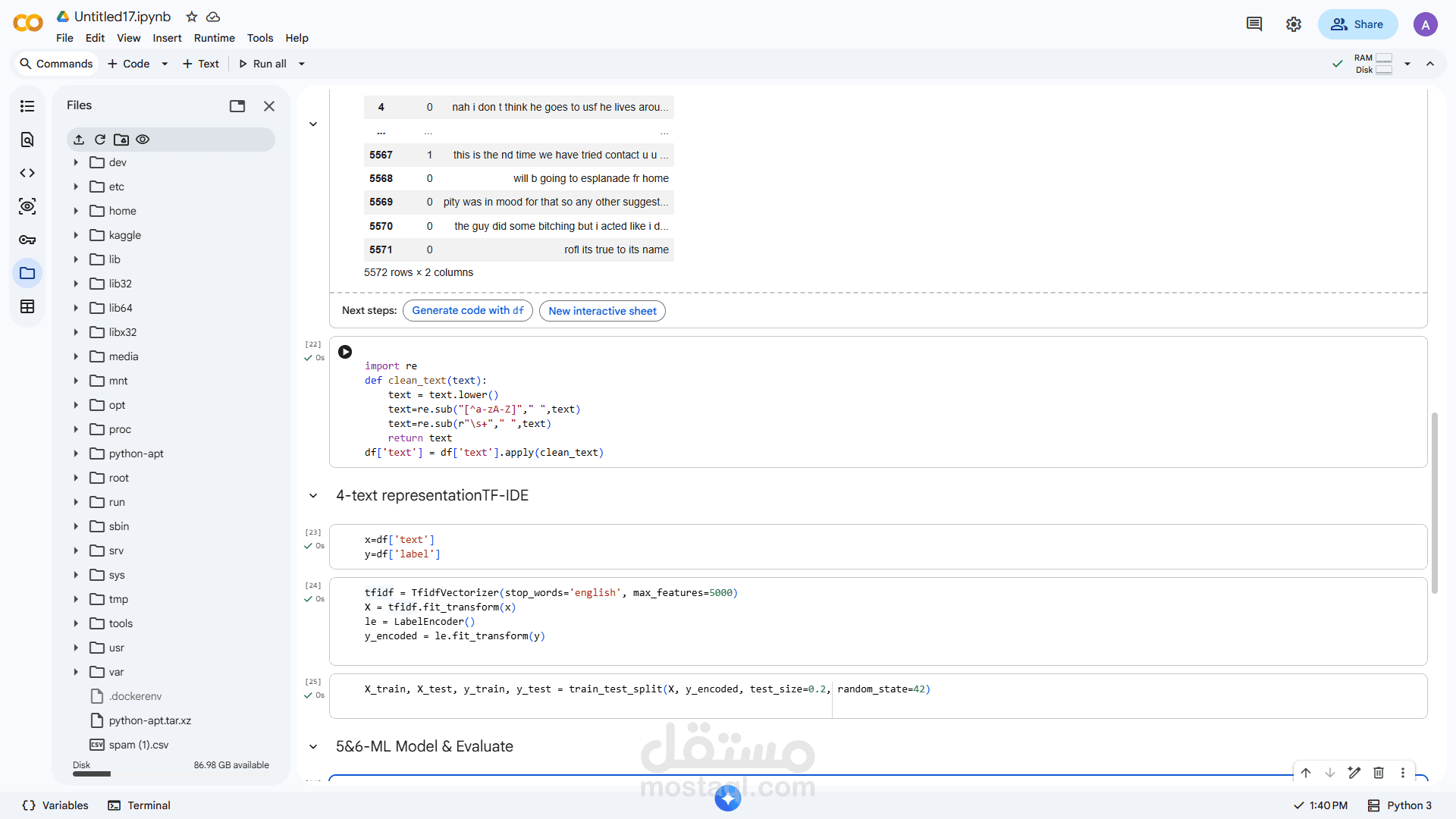
تنظيف البيانات النصية (إزالة الرموز، التوقفات، التكرار)
Tokenization (تقسيم النص إلى كلمات)
إزالة Stop Words
تطبيق Stemming / Lemmatization
2. تحويل النصوص إلى بيانات رقمية:
استخدام تقنيات مثل:
Bag of Words (BoW)
TF-IDF
تمثيل النصوص بشكل مناسب للنماذج
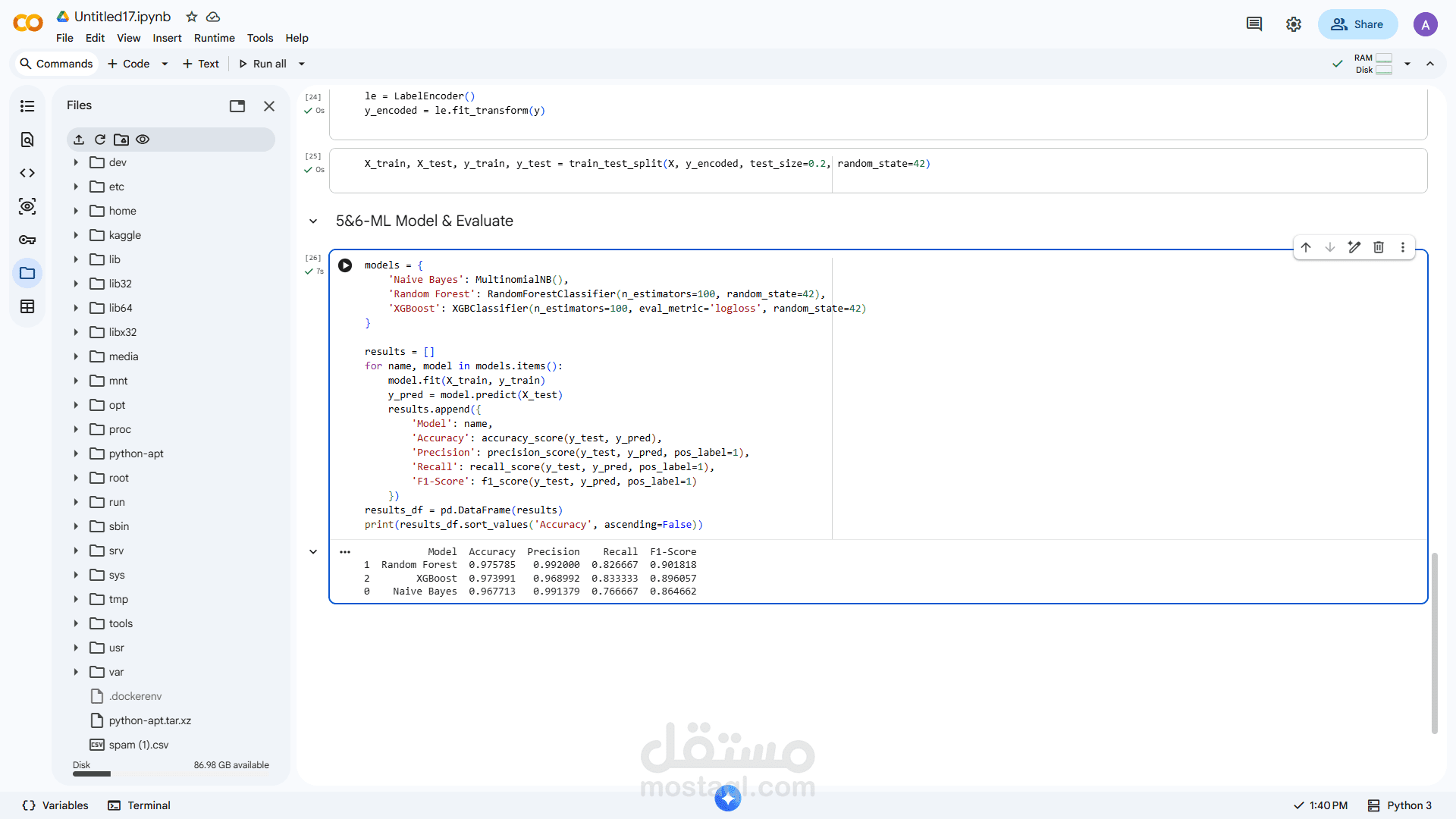
3. بناء نموذج التعلم الآلي:
تدريب نموذج لتصنيف أو تحليل النصوص
استخدام خوارزميات مثل:
Logistic Regression
Naive Bayes
أو غيرها حسب طبيعة البيانات
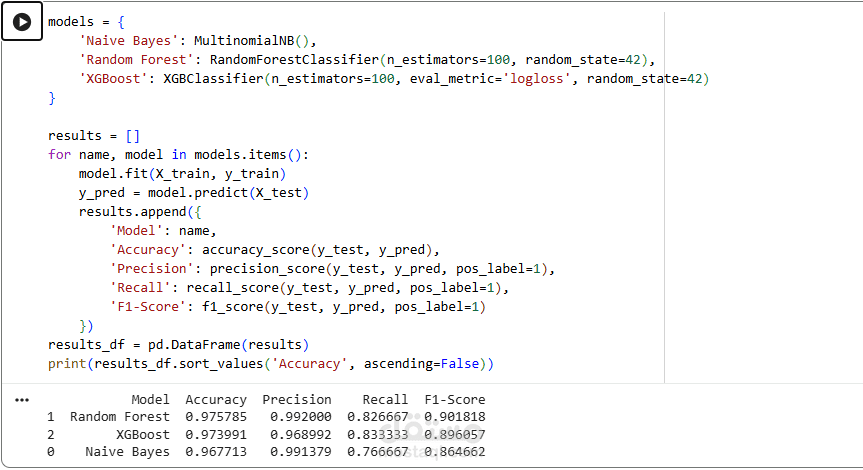
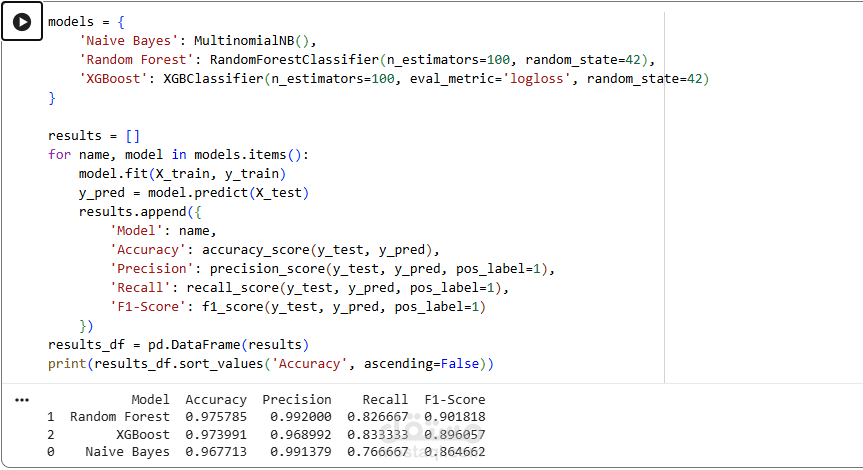
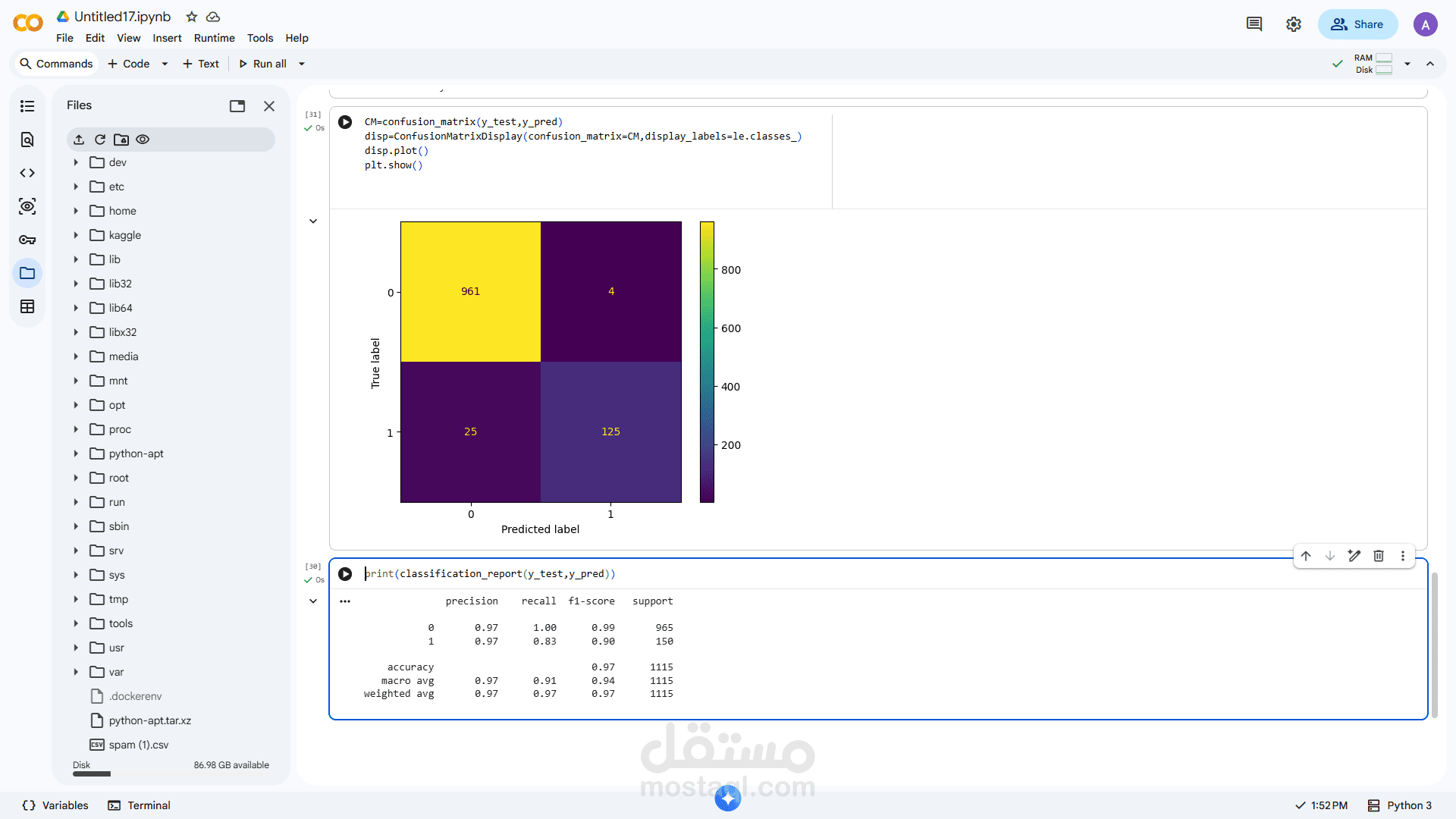
4. تقييم النموذج:
حساب Accuracy
استخدام:
Confusion Matrix
Precision / Recall / F1-score
تحسين الأداء للوصول لأفضل نتائج
الهدف من المشروع:
فهم وتحليل البيانات النصية بشكل ذكي
أتمتة تصنيف النصوص (مثل تحليل المشاعر أو تصنيف التعليقات)
دعم اتخاذ القرار بناءً على البيانات النصي