Parkinson_MachineModel
تفاصيل العمل
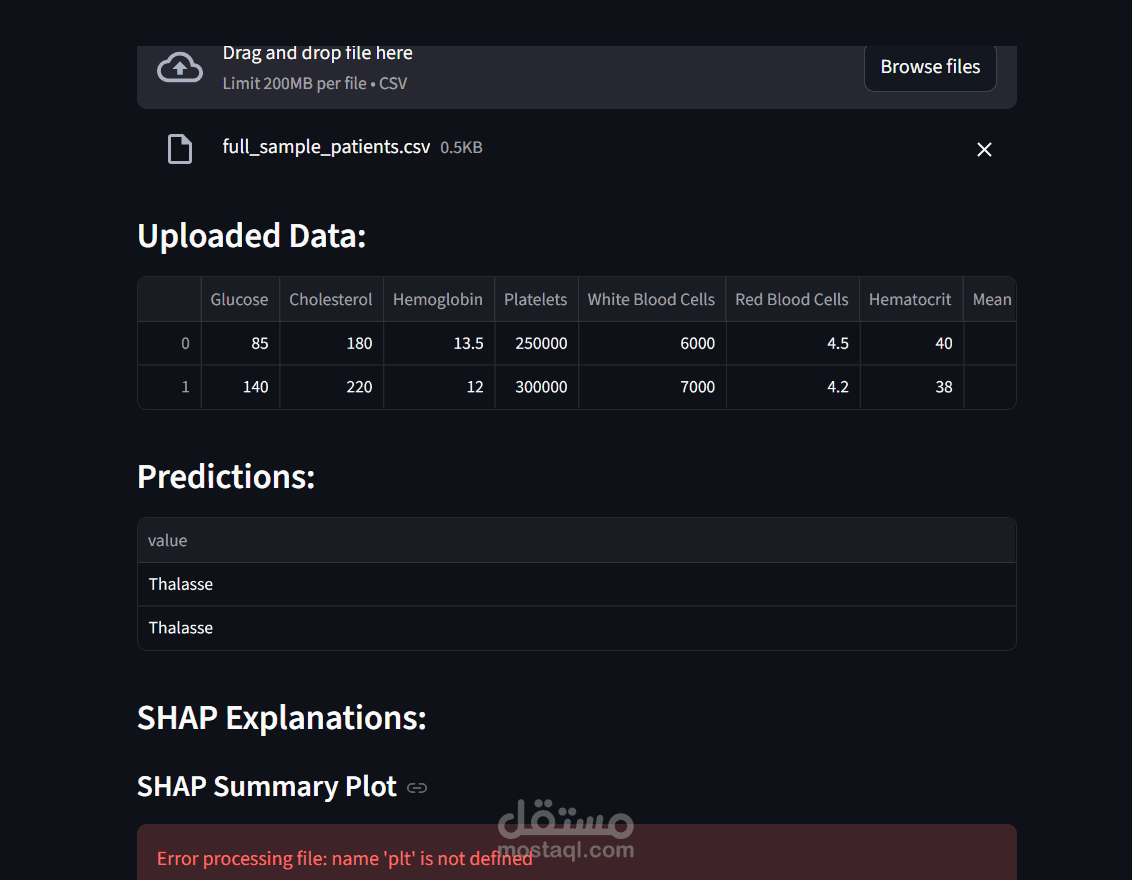
Project Overview
This project builds a machine learning model to classify Parkinson’s Disease (PD) vs Healthy samples using biomedical features. It demonstrates the full workflow from data preprocessing, feature scaling, model training, evaluation, and interactive sample testing.
The goal is to provide a reproducible, end-to-end pipeline for medical data classification and exploratory analysis.
Dataset The dataset contains patient data with numerical features extracted from biomedical tests or speech signals. Key columns: status: Target variable, 0 = Healthy, 1 = Parkinson’s. Other columns: Numerical features relevant to Parkinson’s diagnosis. Missing values are handled by filling with median values per feature. Non-feature columns like name are removed during preprocessing. Project Features Data Preprocessing Handling missing values. Dropping irrelevant columns (name, etc.). Sampling Extract healthy and Parkinson’s samples for testing. Random sample prediction in an interactive loop. Model Random Forest Classifier for robust classification. Train/test split with stratification. Feature scaling using StandardScaler. Evaluation Confusion matrix for performance assessment. Classification report (Precision, Recall, F1-score, Accuracy). Interactive Prediction Test individual samples interactively. Loop predictions until user stops. Getting Started Requirements Python 3.8+
Libraries:
pip install pandas numpy scikit-learn Usage
Load the dataset:
df = pd.read_csv("your_parkinson_dataset.csv") Preprocess, scale, and split the dataset.
Train the model:
model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train_scaled, y_train)
Evaluate:
y_pred = model.predict(X_test_scaled) print(classification_report(y_test, y_pred))
Test samples interactively:
while True: sample = X.sample(1) pred = model.predict(scaler.transform(sample)) print("Prediction:", "Healthy" if pred[0]==0 else "Parkinson") if input("Stop? (y/n)")=='y': break Project Structure parkinsons-classification/ │ ├─ dataset/ # Contains the raw dataset CSV ├─ scripts/ # Python scripts for training, testing ├─ README.md # Project documentation └─ requirements.txt # Python dependencies Key Insights Random Forest achieves robust classification even with moderate-sized datasets. Feature scaling is critical for numeric stability. Interactive sampling allows testing new patients individually without retraining. Future Improvements Test additional classifiers (SVM, XGBoost, Neural Networks) for performance comparison. Feature importance analysis to identify most predictive biomedical features. Deploy as a web app for real-time Parkinson’s prediction.