نظام تصنيف نصوص عربي قائم على MLOps
تفاصيل العمل

تطوير نظام متكامل لتصنيف النصوص العربية باستخدام تقنيات التعلم العميق، مع بناء Pipeline متكامل وفق منهجية MLOps جاهز للاستخدام في بيئات الإنتاج (Production).
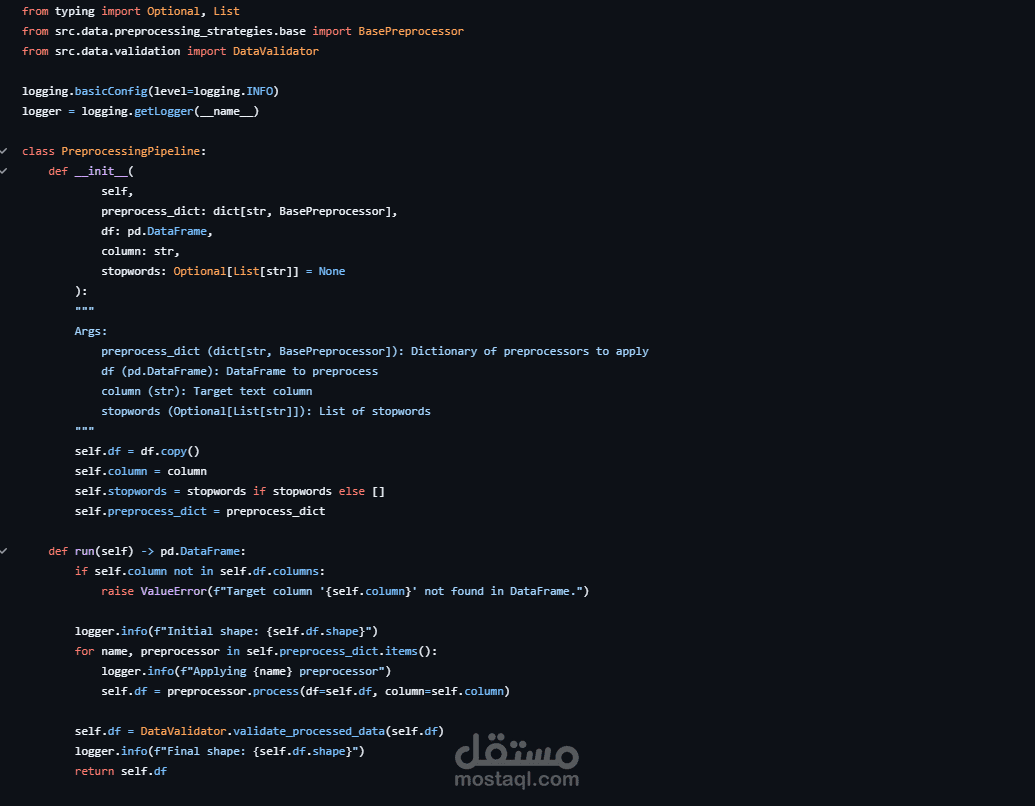
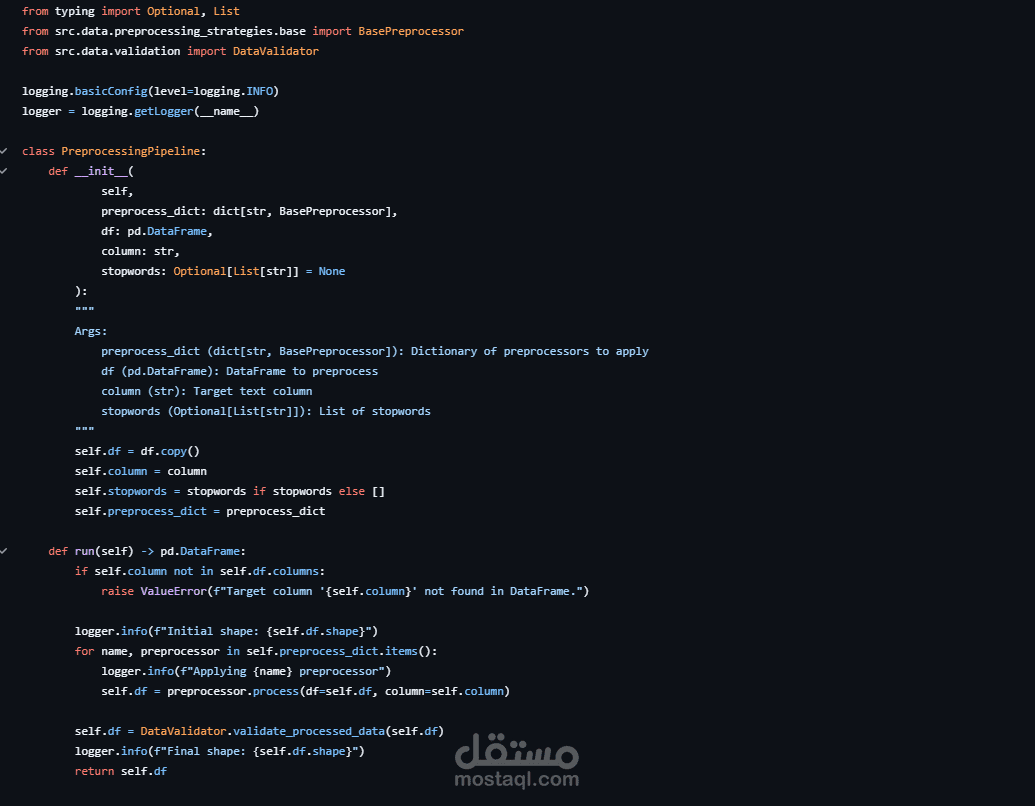
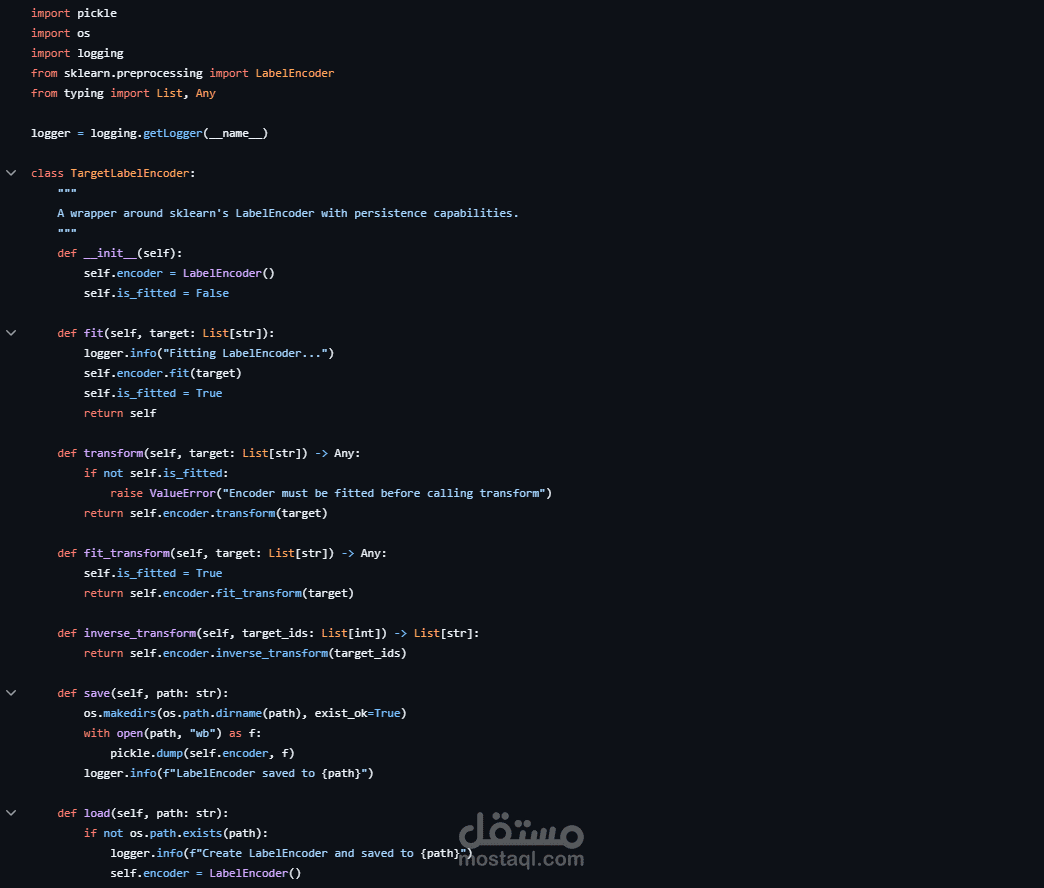
تم تصميم النظام بهيكلية Modular وDecoupled Architecture تفصل بين طبقات البيانات، النماذج، وخطوط المعالجة، مما يضمن قابلية التوسع وسهولة الصيانة والتطوير.
يشمل العمل:
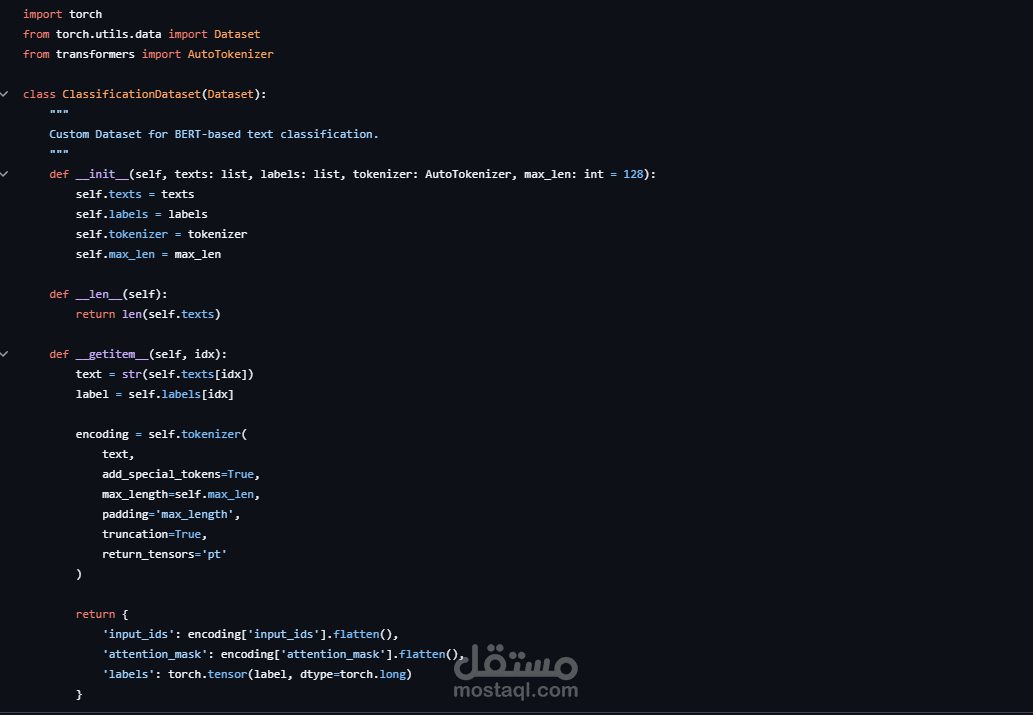
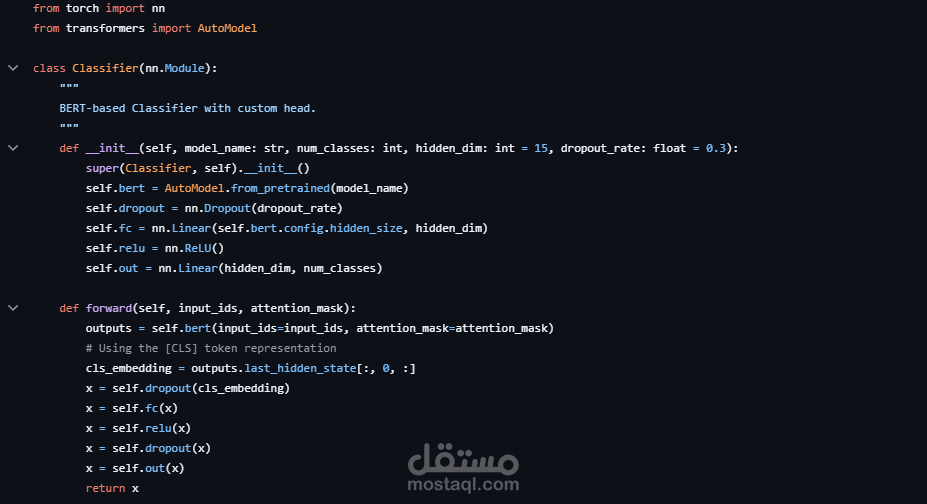
بناء نموذج تصنيف نصوص عربي باستخدام BERT بعد Fine-tuning لتحقيق دقة عالية في فهم السياق اللغوي.
تصميم Preprocessing Framework مرن قائم على Strategy Pattern لدعم تعدد طرق المعالجة بسهولة.
تطوير Training Engine قابل لإعادة الاستخدام لتجربة وتدريب النماذج بكفاءة.
دمج MLflow لتتبع التجارب (Experiment Tracking) وإدارة الإصدارات.
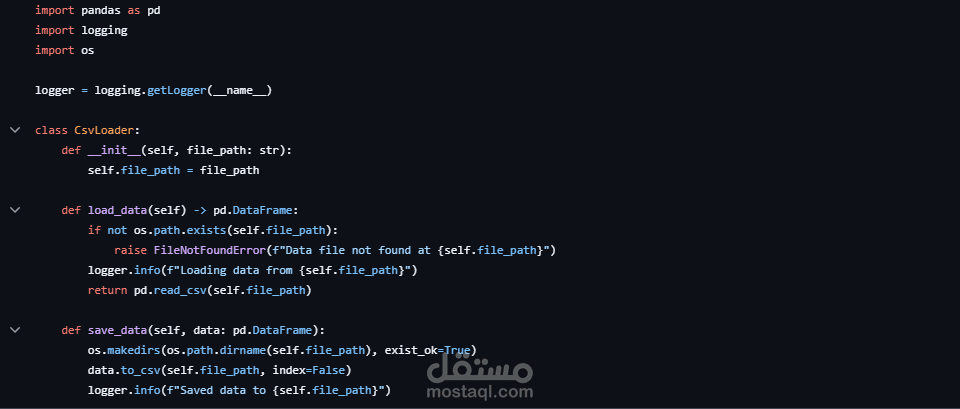
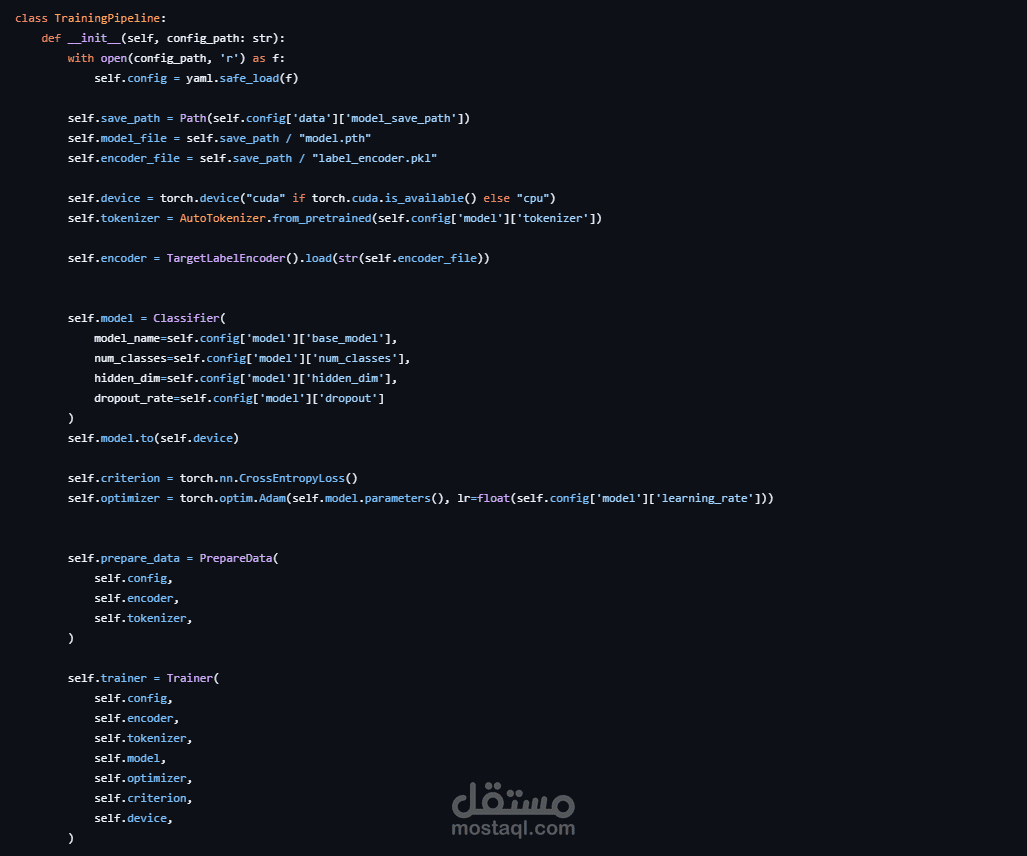
تنفيذ Pipeline آلي بالكامل يشمل مراحل التحميل، المعالجة، التدريب، والتقييم.
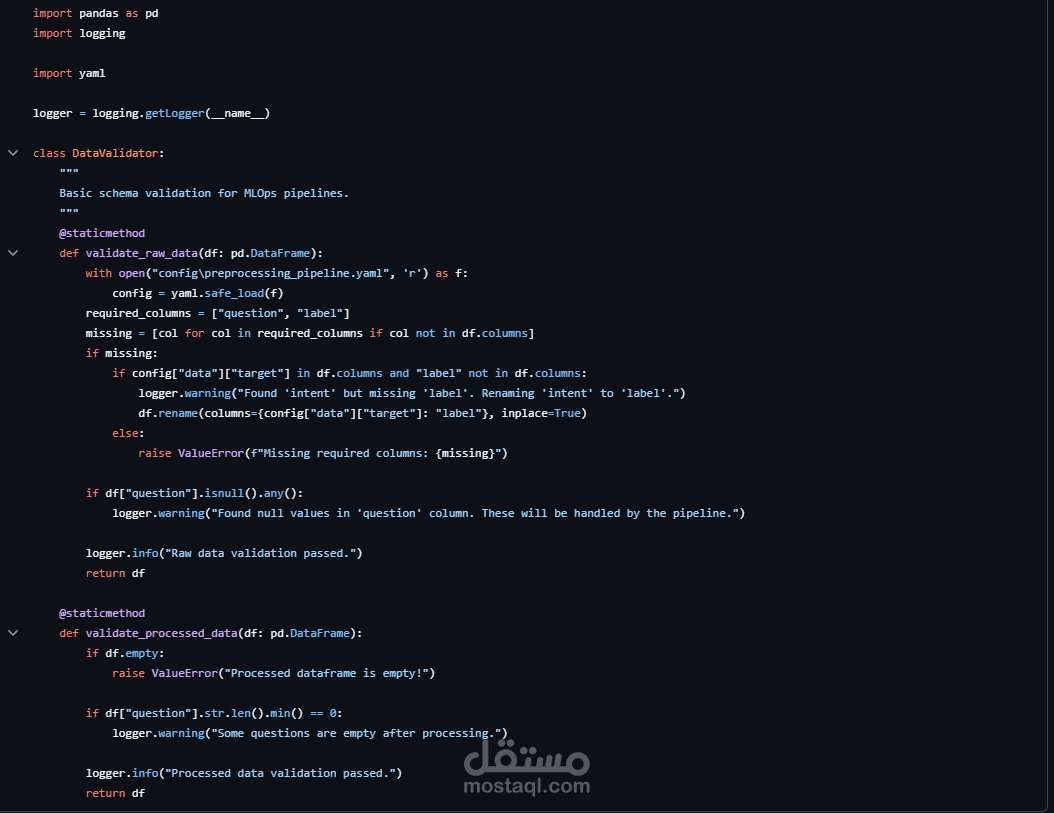
إضافة Validation Checkpoints لضمان جودة البيانات والنماذج خلال مراحل التشغيل.
استخدام YAML Configuration Management للتحكم في إعدادات النظام بشكل مرن وسهل التعديل.
النتيجة:
نظام قوي وقابل للتوسع لتصنيف النصوص العربية بدقة عالية، مع بنية إنتاجية متكاملة تتيح إعادة الاستخدام، التتبع، والتطوير المستمر بسهولة، مناسب لتطبيقات مثل تحليل المشاعر، تصنيف التعليقات، وأنظمة دعم القرار.