AI-Text-to-Image-Generator-with-Diffusers
تفاصيل العمل
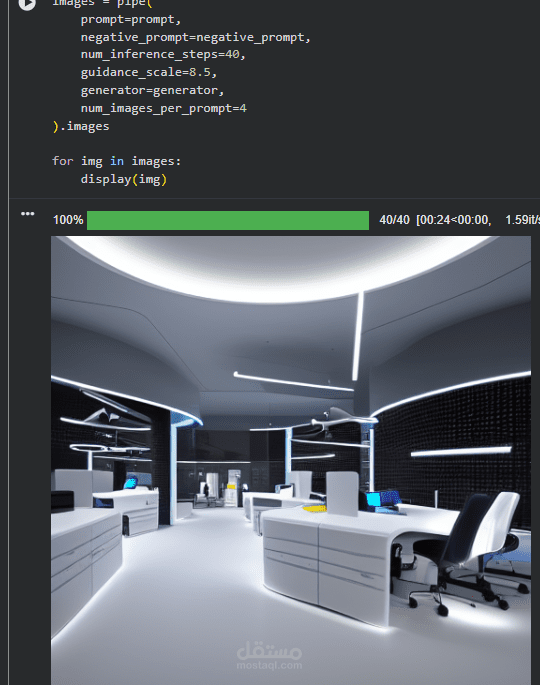
This project implements a Text-to-Image generation system using diffusion models, specifically Stable Diffusion, leveraging the Hugging Face Diffusers library. The system takes a textual description as input and generates high-quality, visually coherent images that align with the given prompt.
The project focuses on enhancing image realism, clarity, and reproducibility through advanced techniques:
Prompt engineering: carefully crafted positive and negative prompts to maximize detail and avoid distortions.
Scheduler optimization: using the DPMSolverMultistepScheduler to improve sharpness and reduce artifacts.
Face enhancement: integration of GFPGAN for clearer, natural-looking human faces.
Reproducibility: controlled random seed ensures consistent results.
Post-processing: automatic watermarking with the author’s name to indicate ownership and branding.
User interface: interactive Gradio web app allowing users to input prompts, adjust guidance scale and inference steps, and instantly visualize generated images.
The project demonstrates the practical application of modern diffusion models for creative AI tasks, providing both a research-oriented perspective and a user-friendly product demo. Generated images can be used for art, concept design, and educational purposes while preserving the user’s branding.
Key Contributions:
Integration of text-to-image diffusion models with advanced face restoration.
Dynamic prompt-based image generation with adjustable quality controls.
Interactive UI for real-time experimentation and image generation.
Automatic watermarking to ensure intellectual property protection.
This project serves as a comprehensive guide for beginners and enthusiasts looking to explore AI-driven creative applications using diffusion-based models.