نظام ذكاء اصطناعي لتحليل مشاعر النصوص باللهجة الجزائرية السوفية (دقة 95%)
تفاصيل العمل




تطوير نموذج ذكاء اصطناعي يعتمد على التعلم العميق (Deep Learning) ومعالجة اللغات الطبيعية (NLP) لتحليل مشاعر النصوص المكتوبة باللهجة الجزائرية (السوفية) وتصنيفها إلى (إيجابي، سلبي، محايد). هذا النظام يمكن استخدامه لتحليل آراء العملاء على وسائل التواصل الاجتماعي أو تقييمات المنتجات والخدمات للشركات المحلية.
أبرز التحديات التي تم حلها:
التعامل مع اللهجات المحلية يعتبر تحدياً كبيراً لعدم وجود قواعد نحوية ثابتة. تم بناء نظام معالجة مسبقة (Preprocessing) مخصص لتنظيف النصوص العربية، وتوحيد الحروف، وإزالة التشكيل لضمان فهم النموذج للكلمات بشكل صحيح.
تفاصيل الحل التقني وهيكلة البيانات:
معالجة البيانات غير المتوازنة (Data Balancing): تم استخدام تقنية (Upsampling) لرفع عدد العينات في الفئات الأقل تمثيلاً، مما رفع إجمالي بيانات التدريب إلى 9879 عينة متوازنة تماماً لمنع انحياز النموذج (Bias).
بناء النموذج الشبكي: تم الاعتماد على معمارية الشبكات العصبية المتكررة ثنائية الاتجاه لمعالجة النصوص، حيث تساعد هذه المعمارية على فهم سياق الكلمة من الاتجاهين (قبلها وبعدها).
تقنيات التدريب المتقدمة: تم دمج تقنيات مثل (Early Stopping) لمنع الإفراط في الملاءمة (Overfitting)، و(ReduceLROnPlateau) لتعديل سرعة التعلم ديناميكياً.
النتائج:
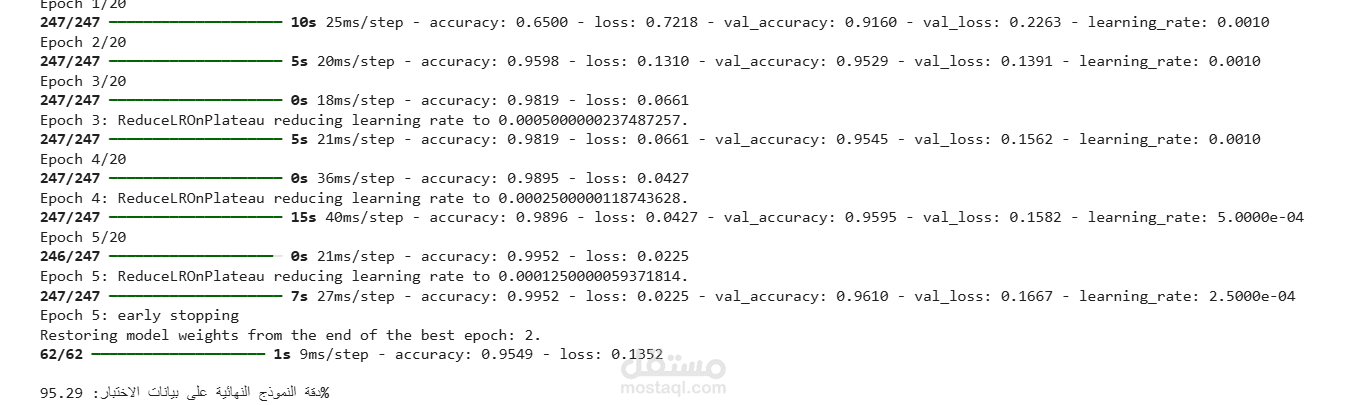
حقق النموذج دقة تدريب وصلت إلى 99%.
حقق دقة استثنائية على بيانات الاختبار النهائية (بيانات لم يرها النموذج من قبل) بلغت 95.29%، مع خسارة (Loss) منخفضة جداً (0.135).
المشروع يبرز القدرة على بناء أنظمة ذكاء اصطناعي مخصصة من الصفر، والتعامل مع البيانات النصية المعقدة بكفاءة عالية.