نظام ذكاء اصطناعي (OCR) لاستخراج بيانات ملصقات الأدوية (المركز الثالث في هاكاثون)
تفاصيل العمل

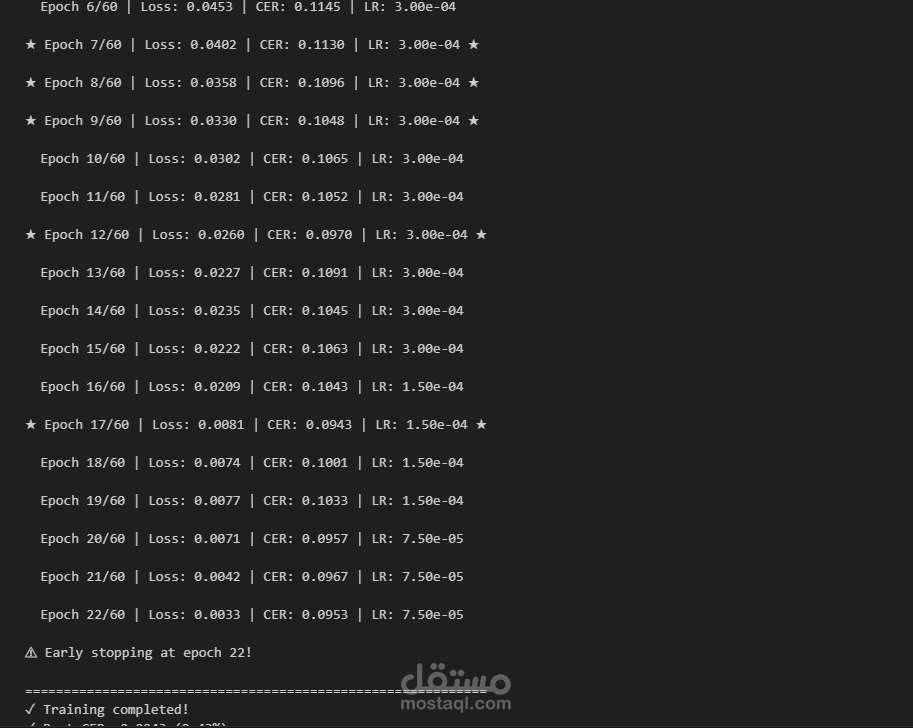


تطوير نظام ذكاء اصطناعي متكامل يعتمد على تقنيات الرؤية الحاسوبية والتعرف البصري على الحروف (OCR) لاستخراج البيانات الحساسة من ملصقات الأدوية (مثل: رقم التشغيلة Lot، تاريخ الإنتاج FAB، وتاريخ الانتهاء EXP). حصد هذا الحل المركز الثالث في مسابقة تنافسية (Vignette OCR) تهدف إلى أتمتة الصيدليات وتقليل الأخطاء البشرية.
المشكلة التي يحلها المشروع:
إدخال بيانات الأدوية يدوياً في أنظمة نقاط البيع (POS) يستهلك وقتاً طويلاً ويكون عرضة للأخطاء البشرية الكارثية. الملصقات غالباً ما تكون صغيرة، مطبوعة بجودة رديئة، أو مقلوبة، مما يجعل قراءتها برمجياً أمراً معقداً.
تفاصيل الحل التقني (Pipeline):
تم بناء النظام على مرحلتين لضمان أعلى دقة ممكنة:
مرحلة تصنيف وتعديل الاتجاه (Orientation Classifier): تم تدريب نموذج (ResNet18) مخصص لاكتشاف ما إذا كانت الصورة مقلوبة (180 درجة) وتصحيحها تلقائياً قبل المعالجة، وحقق دقة تجاوزت 99%.
مرحلة استخراج النصوص (SVTR OCR Model): تم بناء نموذج متقدم يدمج بين (ResNet34) و(Transformers) لقراءة النصوص متغيرة الطول.
أبرز الإنجازات والتقنيات المستخدمة:
تدريب النماذج على بيانات حقيقية بالإضافة إلى توليد 30,000 صورة اصطناعية (Synthetic Data) لرفع كفاءة النموذج.
استخدام تقنيات تحسين الصور (Data Augmentation) للتعامل مع الإضاءة المنخفضة والضوضاء.
تحقيق معدل خطأ في الحروف (CER) أقل من 0.10، مما يضمن دقة استخراج عالية جداً.
تحسين الكود ليعمل بسرعة وكفاءة عالية ليتناسب مع أنظمة نقاط البيع في الوقت الفعلي.
هذا المشروع يثبت القدرة على تحويل البيانات الخام إلى حلول برمجية جاهزة للعمل في بيئات الإنتاج الحقيقية، وتقليل التكاليف التشغيلية للشركات.