تحليل ونمذجة لبيانات أداء الطلاب الأكاديمي "نظام إنذار مبكر للمؤسسات التعليمية"
تفاصيل العمل
في هذا المشروع، قمتُ كعالمة بيانات (Data Scientist) بتحليل وفحص مجموعة بيانات ضخمة (10,000 سجل) تهدف للتنبؤ بالأداء الأكاديمي للطلاب. التحدي الحقيقي في هذا العمل لم يكن بناء النموذج البرمجي فحسب، بل في اختبار مدى واقعية وصلاحية البيانات لاتخاذ قرارات تنبؤية دقيقة.
لم يكن الهدف مجرد معالجة الأرقام، بل بناء إطار عمل تحليلي كامل يتضمن:
هندسة البيانات الاستقصائية: قمت بفحص 10,000 سجل اصطناعي، مع التركيز على كشف الروابط الخفية بين متغيرات معقدة مثل (ساعات الدراسة، مستويات التوتر، وأنماط التعلم)
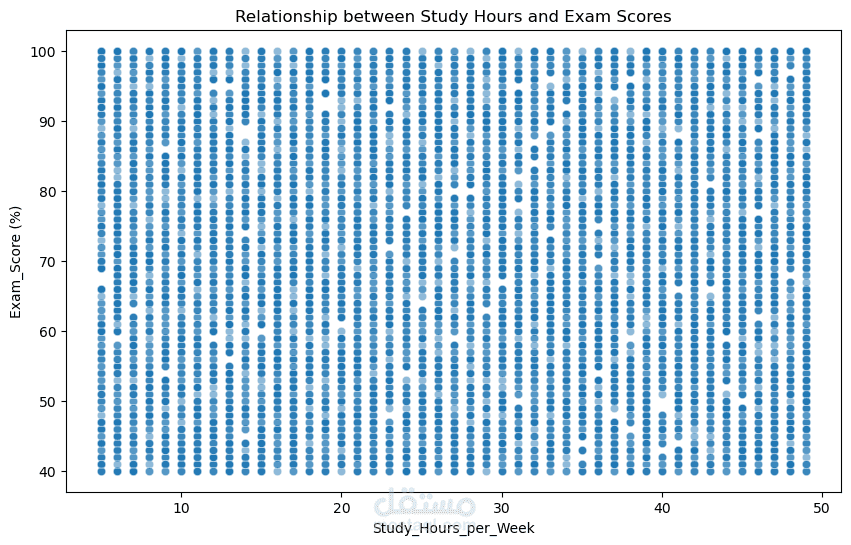
التشخيص البصري المتقدم: استخدمت أدوات التحليل البياني (Boxplots & Heatmaps) ليس فقط لوصف البيانات، بل لاستنتاج الفرضيات الأولية حول مسببات النجاح الأكاديمي.
بناء النماذج التنبؤية (Proof of Concept): قمت بتطوير نموذج يعتمد على خوارزمية Random Forest للتأكيد علي استنتاج استخرجته من هذه البيانات وهي انها (Simulated Dataset) ليست لطلاب حقيقين
الاستنتاج (تأكيد الفرضيات):
مع كل سطر كود وتحليل بياني بتأكد اكتر ان مفيش ارتباطات حقيقة (Correlation) بين عوامل هذه البيانات من توزيع درجات الامتحان والعمر والنتيجة النهائية مرورا بعدم وجود علاقة بين ساعات المذاكرة ودرجات الامتحان (موضح في scatter plot) واخير الخريطة الحرارية للعوامل(Heatmap) بعوامل ارتباط (Correlation Coefficients) تكاد تكون صفر
النموذج كأداة إثبات (Validation Tool): أثبتت نتائج النموذج التنبئي صحة الاستنتاجات التي توصلتُ إليها خلال مرحلة التحليل الاستكشافي (EDA)؛ حيث أكدت دقة النموذج المتواضعة أن الأداء الأكاديمي في هذه البيانات "المصطنعة" لا يعتمد على علاقات خطية بين العوامل انما مجرد اعتماد علي عامل واحد (exam score with final grade) وهو ما يظهر بوضوح في الخريطة الحرارية للعوامل (heatmap)
تأكيد الفشل المنطقي: النتيجة التي حققها النموذج (الدقة المنخفضة 0.24) لم تكن فشلاً برمجياً، بل كانت النجاح الحقيقي في إثبات أن البيانات تفتقر للارتباطات الواقعية (Correlations) المطلوبة للتنبؤ.
الخلاصة المهنية: القيمة الحقيقية لعالم البيانات تكمن في القدرة على قول "هذه الداتا لا تصلح" بناءً على أدلة بصرية وبرمجية قاطعة. هذا المشروع هو تطبيق عملي لمبدأ (Garbage In, Garbage Out)، حيث أثبتُّ بالدليل القاطع أن جودة القرار من جودة المصدر.
هذا المشروع لا يقدم مجرد أرقام، بل يقدم منهجية علمية قادرة على التكيف مع البيانات الحقيقية فور توفرها، مع فهم كامل للثغرات التي تحتاج إلى معالجة لتحقيق دقة أعلى.
الأدوات المستخدمة:
Python (Pandas, NumPy) لمعالجة البيانات.
Matplotlib & Seaborn للتحليل البصري المتقدم.
Scikit-learn لبناء واختبار النماذج التنبؤية.