تحليل البياناتIncome Classification Model باستخدام Machine Learning وتحليل البيانات
تفاصيل العمل

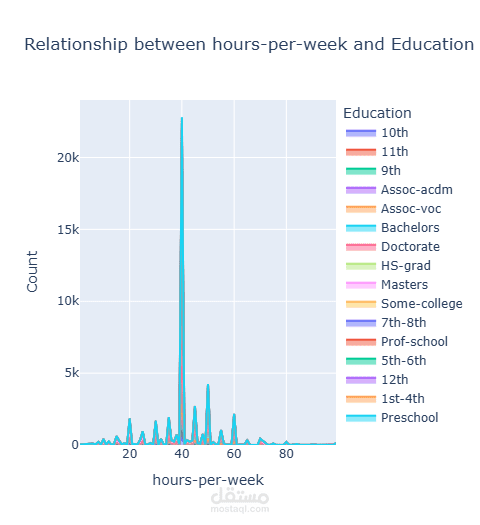
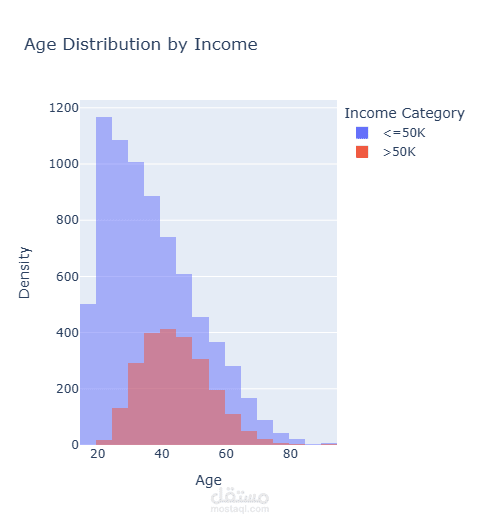
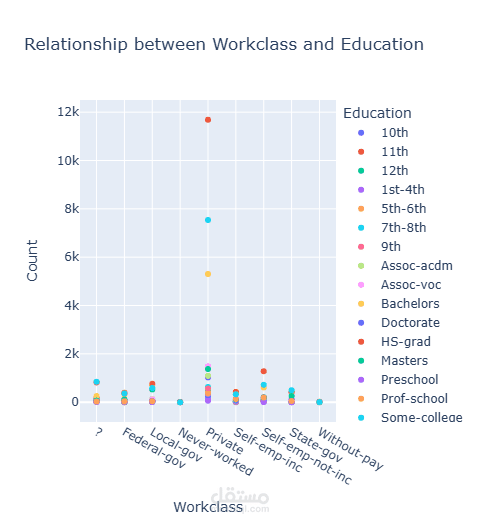
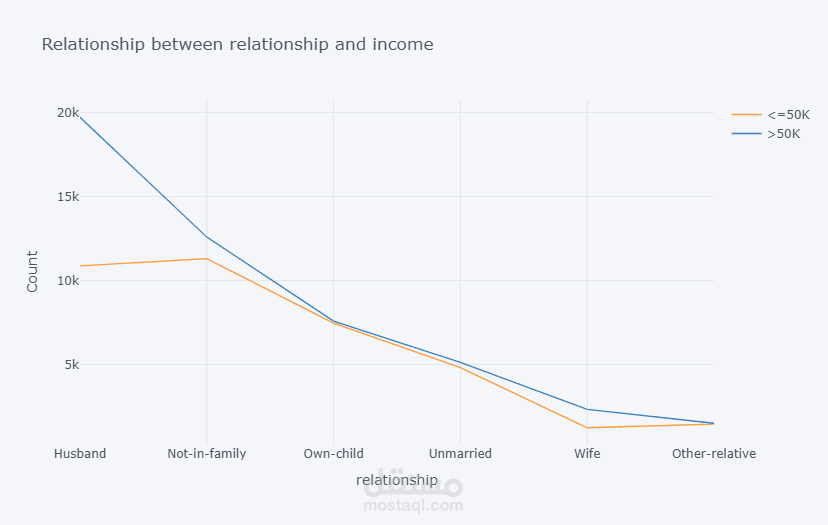
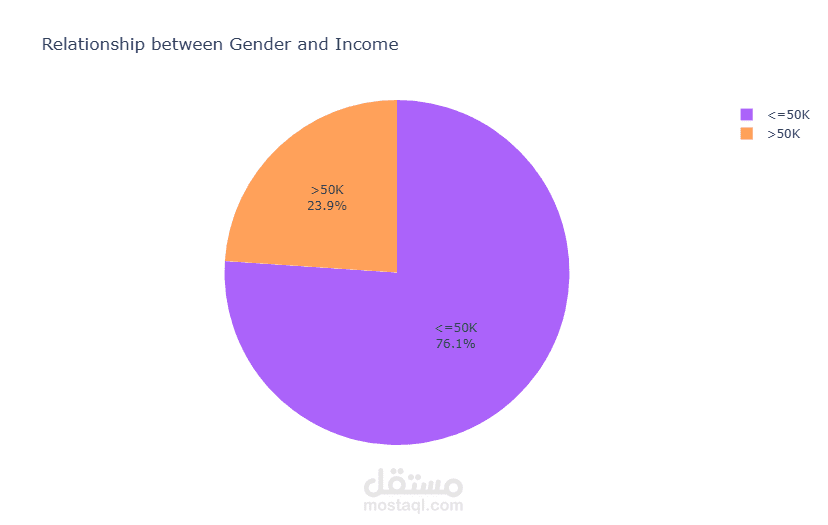
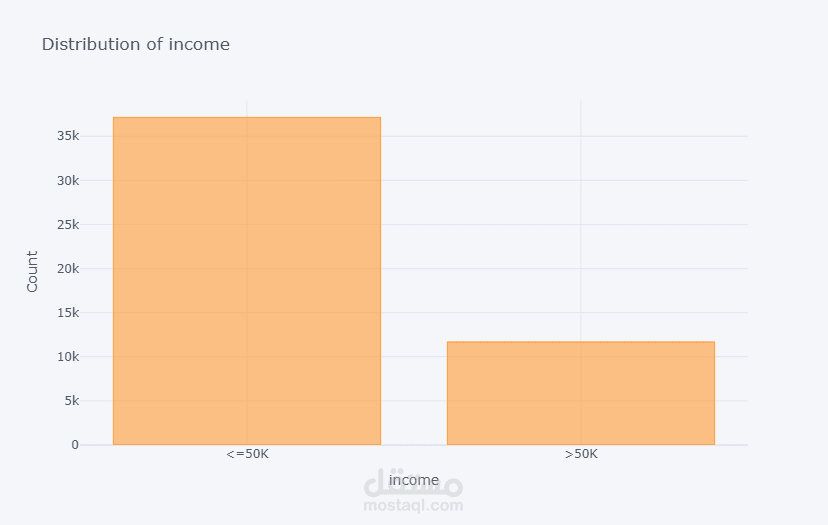
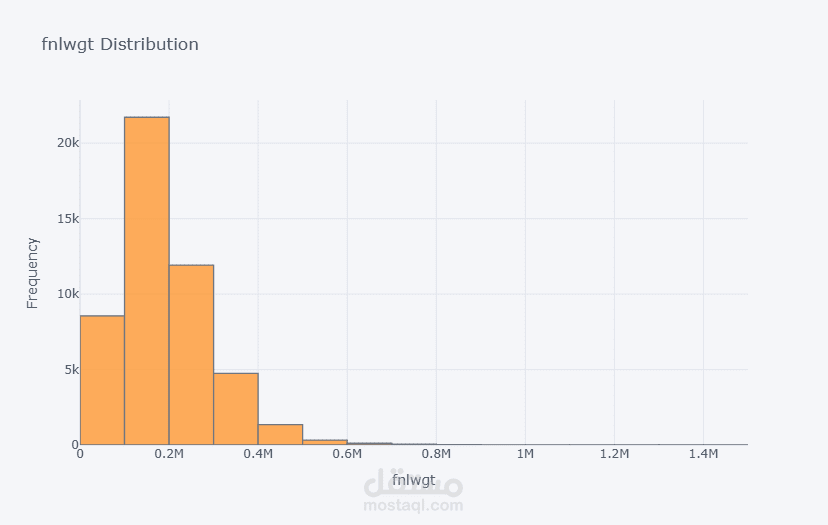
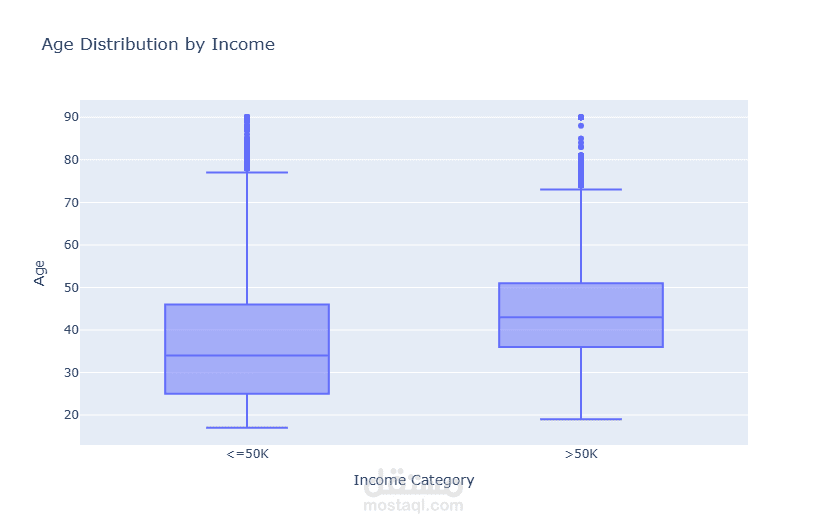
قمت بتطوير نموذج تصنيف للتنبؤ بمستوى الدخل اعتمادًا على البيانات الديموغرافية وبيانات التوظيف.
بدأت المشروع بتحليل استكشافي شامل للبيانات (EDA) باستخدام Plotly على أكثر من 32,000 سجل لاستخراج الأنماط المرتبطة بالدخل. بعد ذلك قمت بعمل Feature Engineering متقدم وحذف الأعمدة غير المؤثرة لتحسين أداء النموذج وتقليل زمن التدريب.
تم تدريب عدة نماذج Machine Learning واختيار الأفضل من حيث الدقة والأداء، مما أدى إلى رفع دقة النموذج من 83% إلى 88%.