Web Scraping & Data Extraction Project using Python (Books Dataset)
تفاصيل العمل

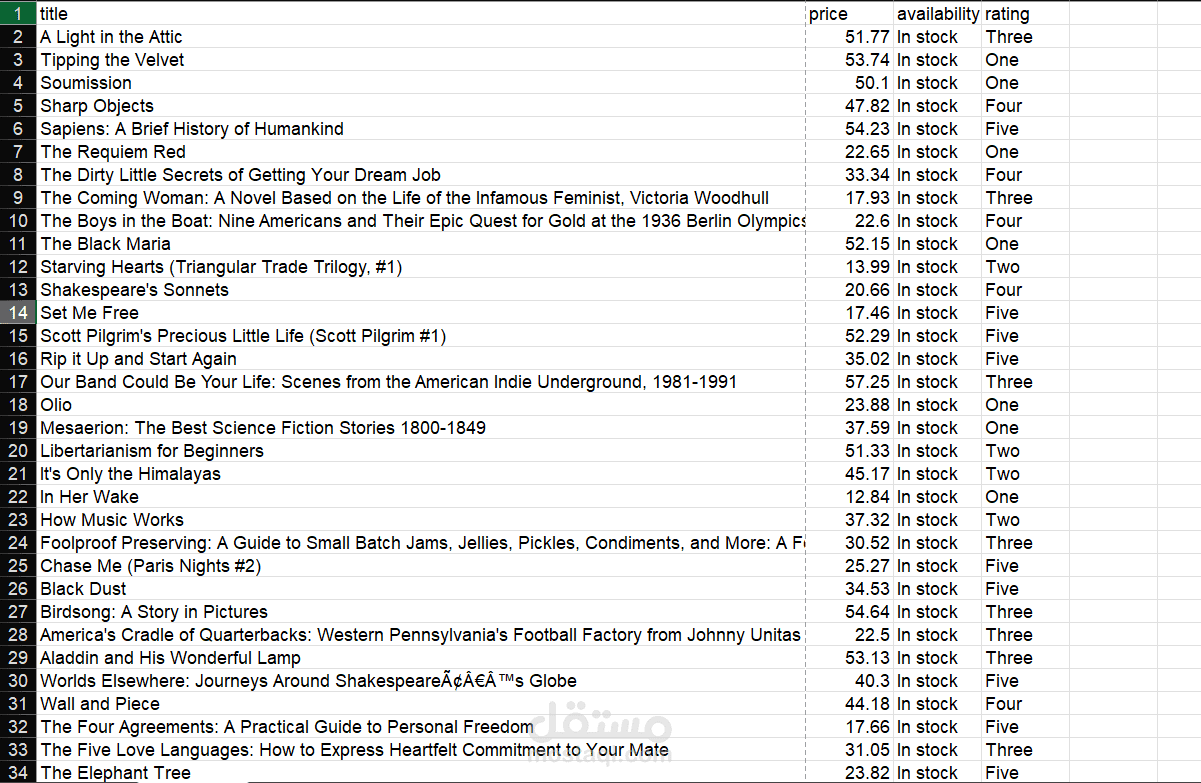
مشروع لاستخراج البيانات (Web Scraping) باستخدام Python، حيث يتم جمع بيانات الكتب من موقع إلكتروني بشكل آلي ومنظم.
يعتمد المشروع على استخدام مكتبة Requests لجلب صفحات الويب، ومكتبة BeautifulSoup لتحليل محتوى HTML واستخراج البيانات المطلوبة بدقة.
يشمل المشروع:
استخراج عناوين الكتب (Titles)
استخراج الأسعار (Prices) وتحويلها إلى قيم رقمية
استخراج حالة التوفر (Availability)
استخراج تقييم الكتب (Ratings)
التنقل بين صفحات الموقع (Pagination)
تنظيم البيانات في شكل Structured Data
حفظ البيانات في ملف CSV جاهز للاستخدام
تم تصميم الكود ليكون قابل للتطوير لإمكانية استخدامه على مواقع أخرى بسهولة.