Car Listings Data Pipeline & Price Prediction System
تفاصيل العمل
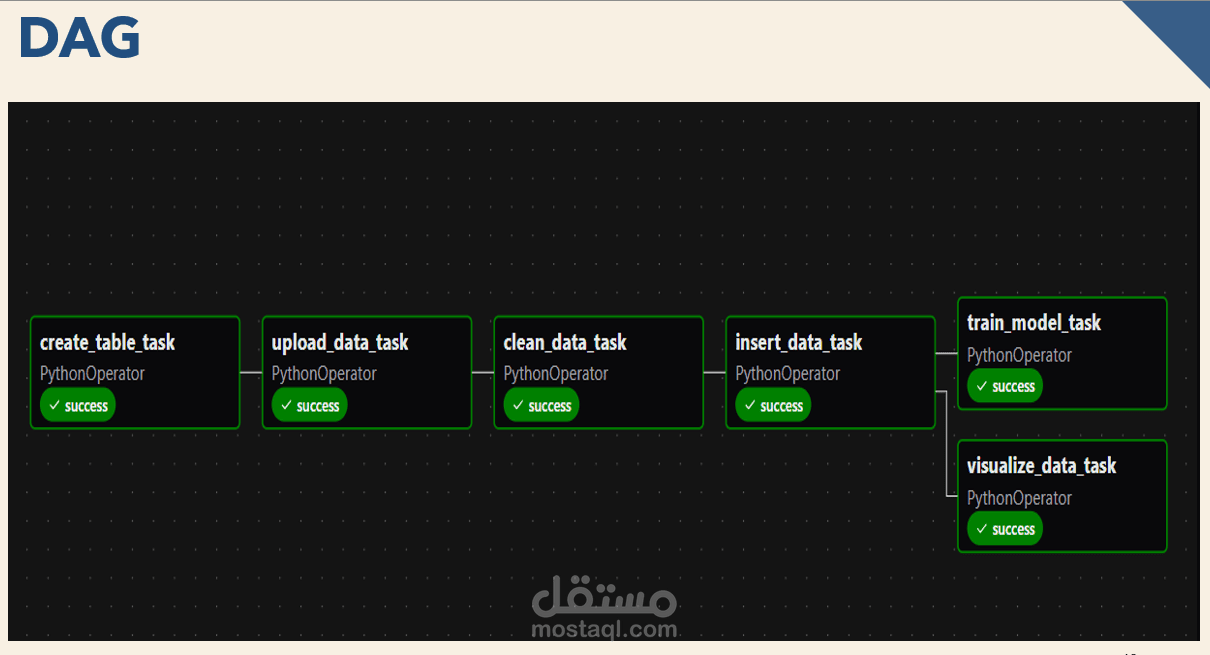
This project focuses on building a complete data pipeline and machine learning system to analyze and predict used car prices based on real-world listings data.
The data was collected from the Hatla2ee website and includes features such as car brand, model, color, mileage (KM), price, and location.
The project pipeline consists of three main stages:
1. Data Extraction:
Raw data is loaded from CSV files and prepared for processing.
2. Data Transformation:
Data cleaning is performed using Pandas, including handling missing values, correcting inconsistent entries, removing duplicates, and standardizing features.
3. Data Loading:
The cleaned data is stored in a PostgreSQL database for further analysis.
Apache Airflow is used to orchestrate and automate the entire workflow as a DAG, ensuring scheduled and reliable execution.
Additionally, a Machine Learning model (Random Forest Regressor) is trained using Scikit-learn to predict car prices based on key features such as brand, model, and mileage.
Data visualization is performed using Matplotlib and Seaborn to extract insights such as:
- Price distribution
- Most popular car models
- Brand price comparison
- Color preferences
This project demonstrates strong skills in Data Engineering, Data Analysis.