مشروع متكامل في تعلم الآلة: تحليل البيانات وبناء نموذج تنبؤي بدقة عالية
تفاصيل العمل
هذا المشروع يهدف إلى بناء نموذج تنبؤي باستخدام تقنيات تعلم الآلة لتحليل البيانات واستخراج الأنماط المهمة التي تساعد في اتخاذ القرار.
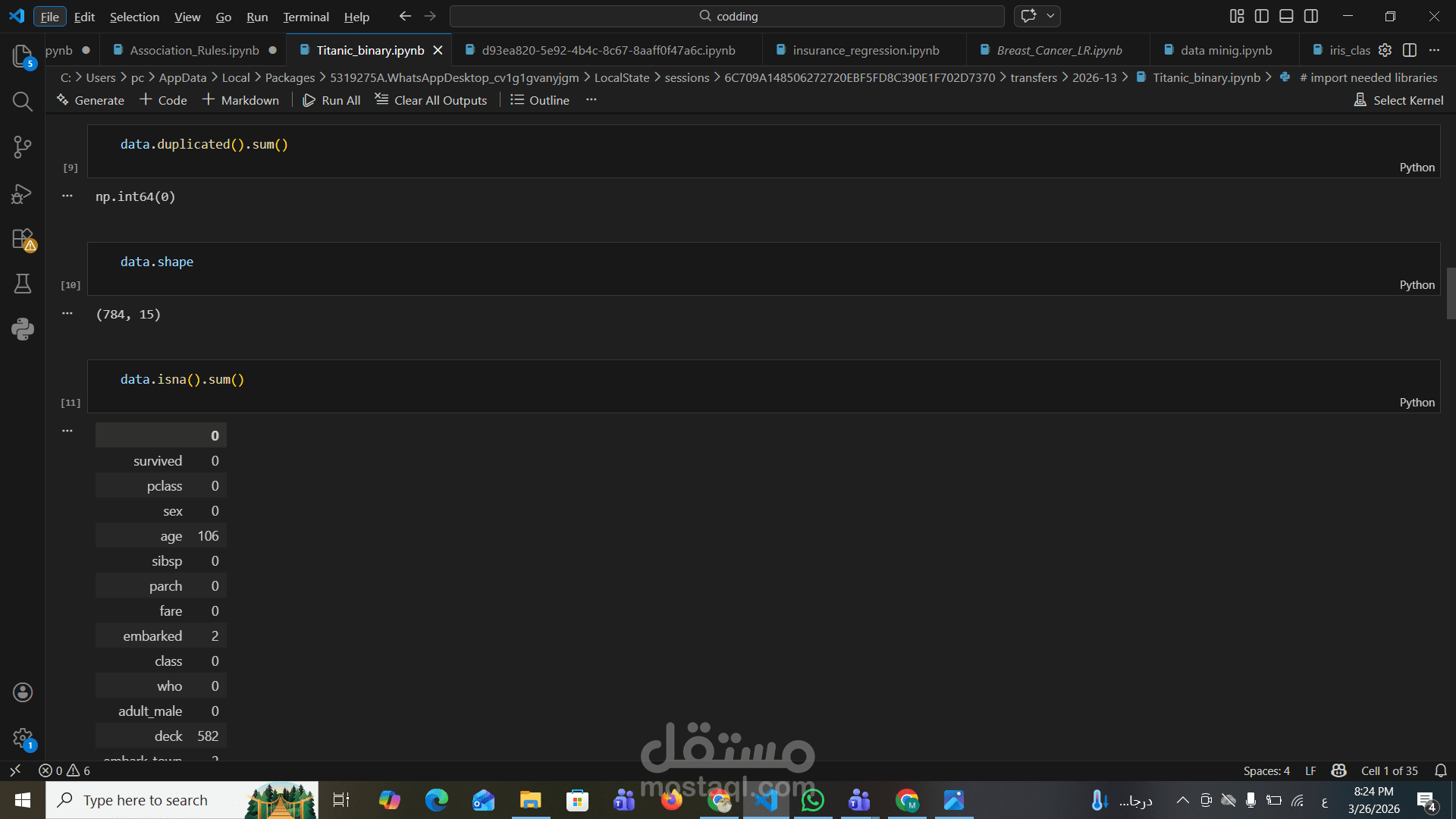
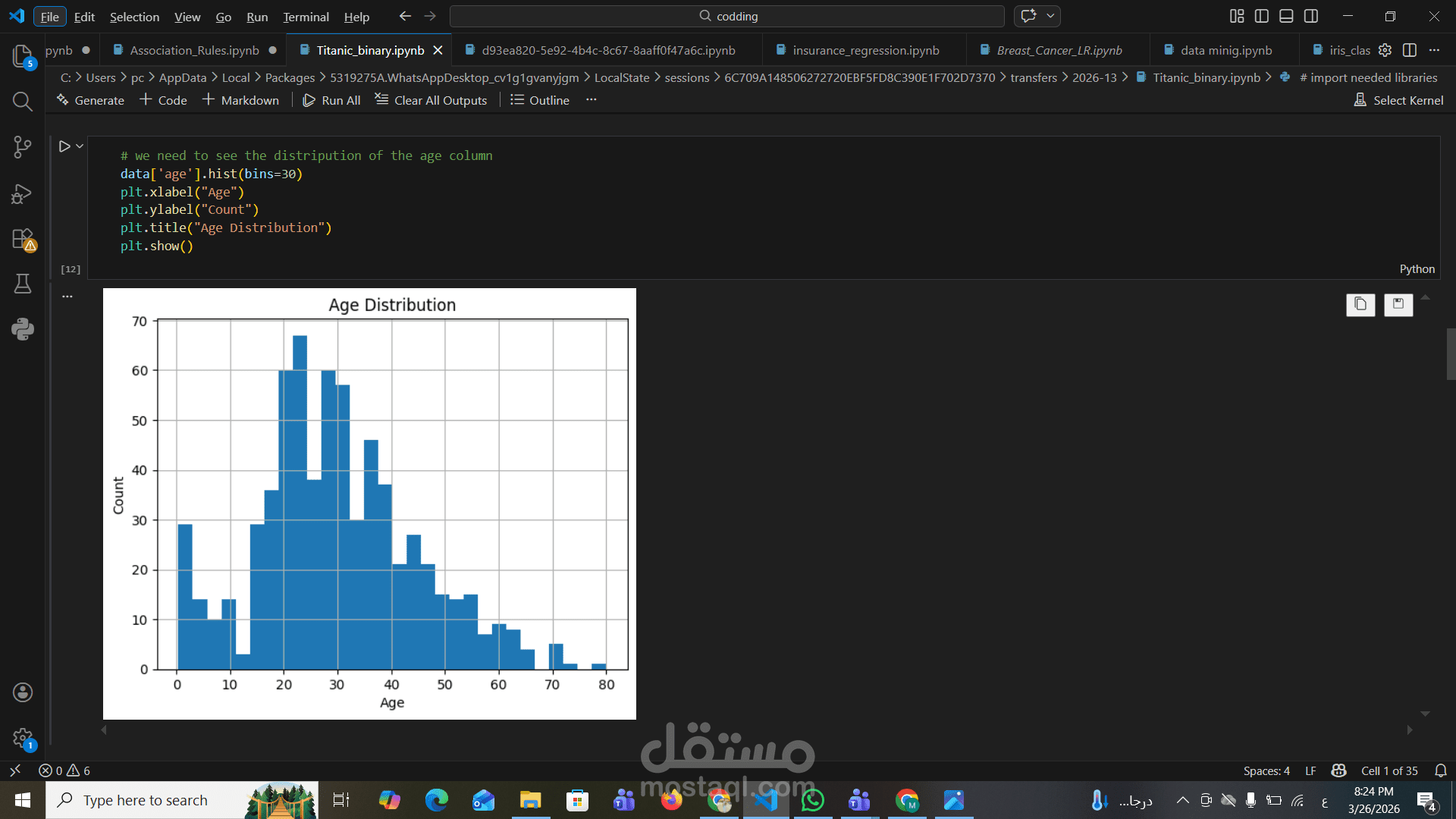
بدأ العمل بمرحلة تنظيف البيانات (Data Cleaning) والتعامل مع القيم المفقودة والتكرارات، ثم تم تنفيذ Feature Engineering لتحسين جودة البيانات وإضافة متغيرات جديدة مثل حجم العائلة.
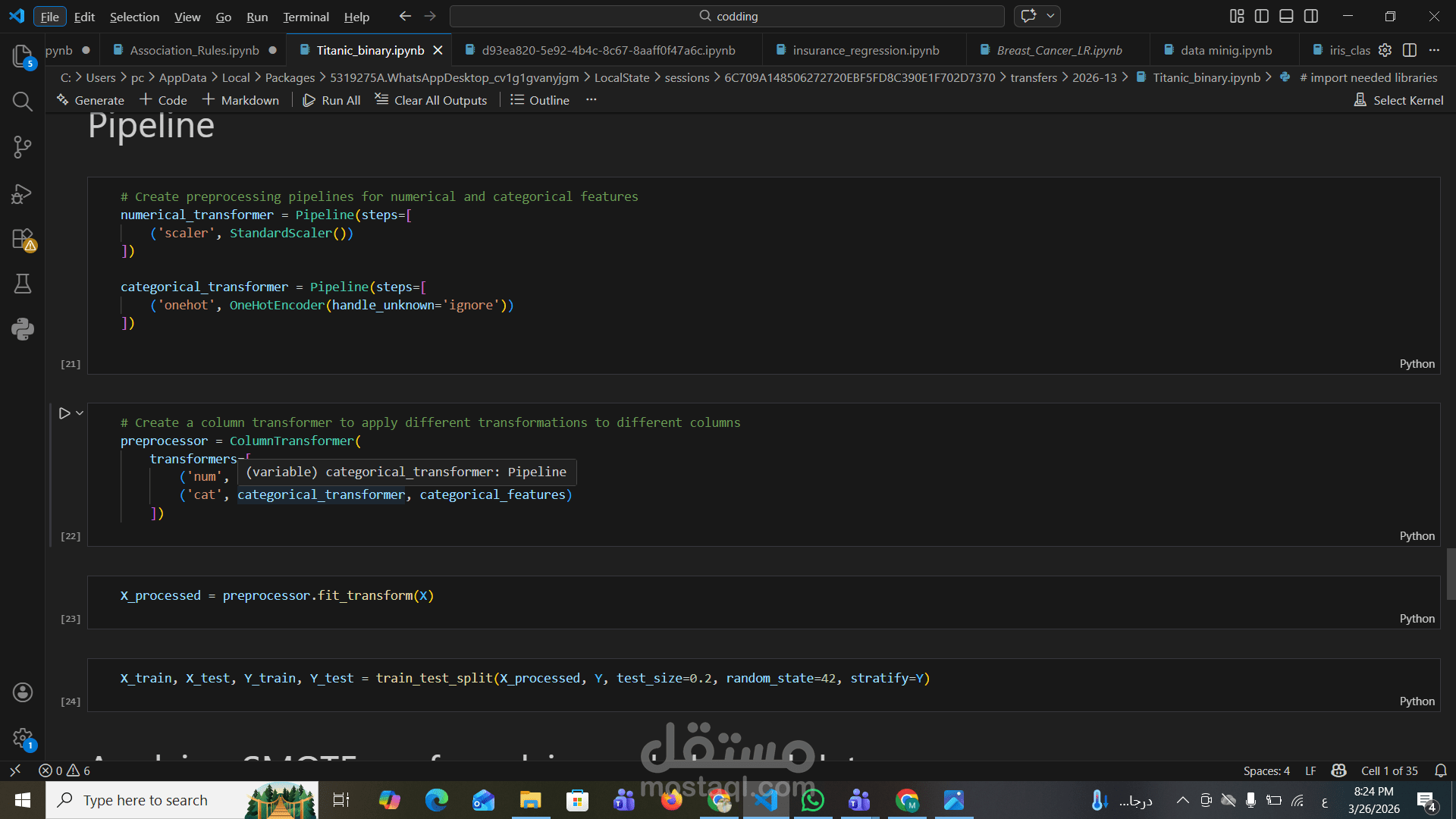
تم استخدام Pipeline احترافي يجمع بين:
Standardization للبيانات الرقمية
One-Hot Encoding للبيانات الفئوية
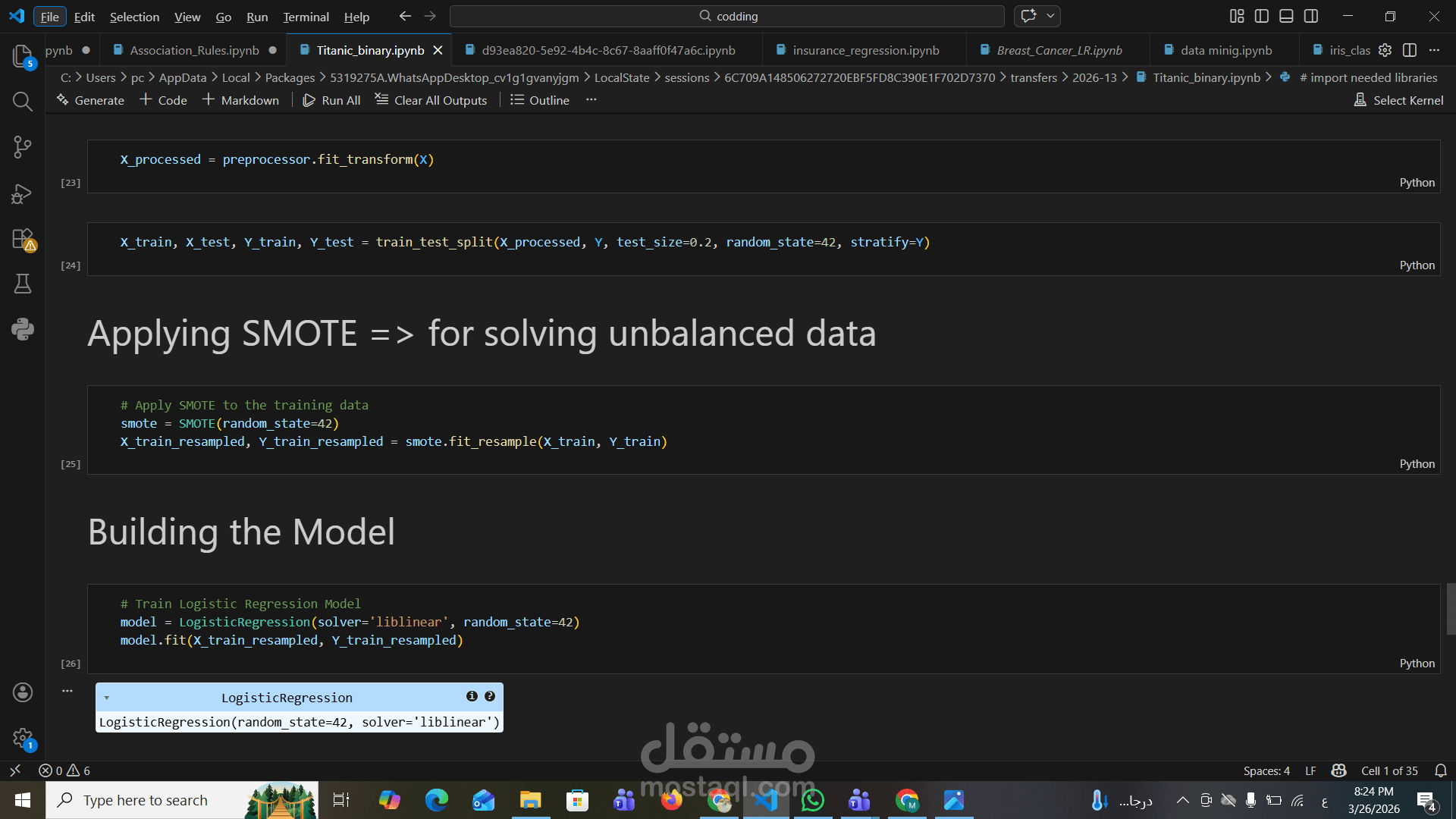
كما تم معالجة مشكلة عدم توازن البيانات (Imbalanced Data) باستخدام تقنية SMOTE لتحسين أداء النموذج.
بعد ذلك، تم بناء نموذج Logistic Regression وتدريبه وتقييمه باستخدام:
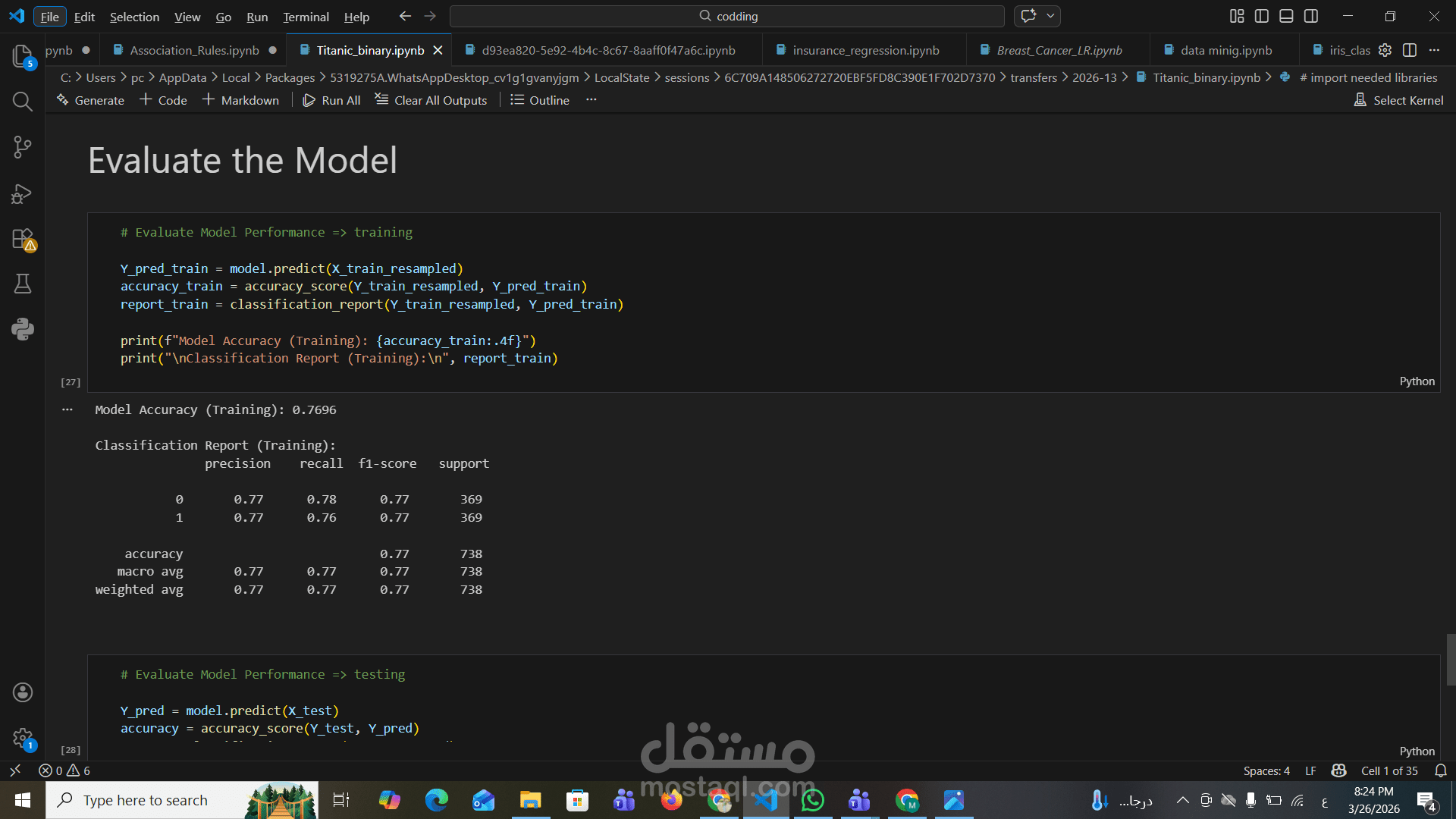
Accuracy Score
Classification Report
المشروع يعكس فهمًا قويًا لمراحل بناء نماذج تعلم الآلة بداية من البيانات الخام وحتى الوصول إلى نموذج قابل للاستخدام.