book to audio
تفاصيل العمل
المحول الذكي من صور الكتب إلى صوت (Smart Book-to-Audio Converter)
هذا النظام مصمم لأتمتة عملية استخراج المعرفة من المصادر المطبوعة وتحويلها إلى محتوى صوتي (Audiobook) بدقة عالية، مما يخدم المكفوفين، الطلاب، ومحبي الاستماع أثناء التنقل.
المكونات والقدرات التقنية:
1. هندسة استقبال ومعالجة الوسائط (Multi-Stage Data Handling):
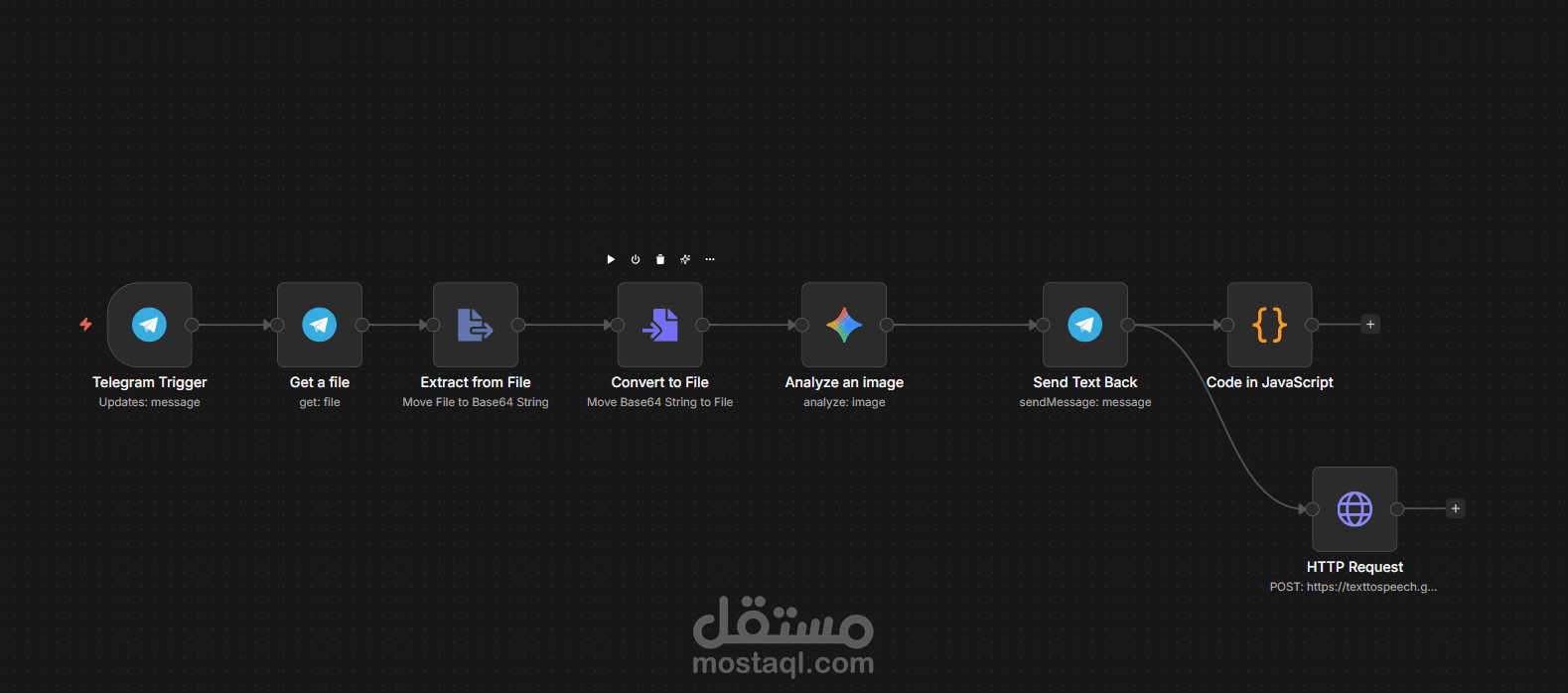
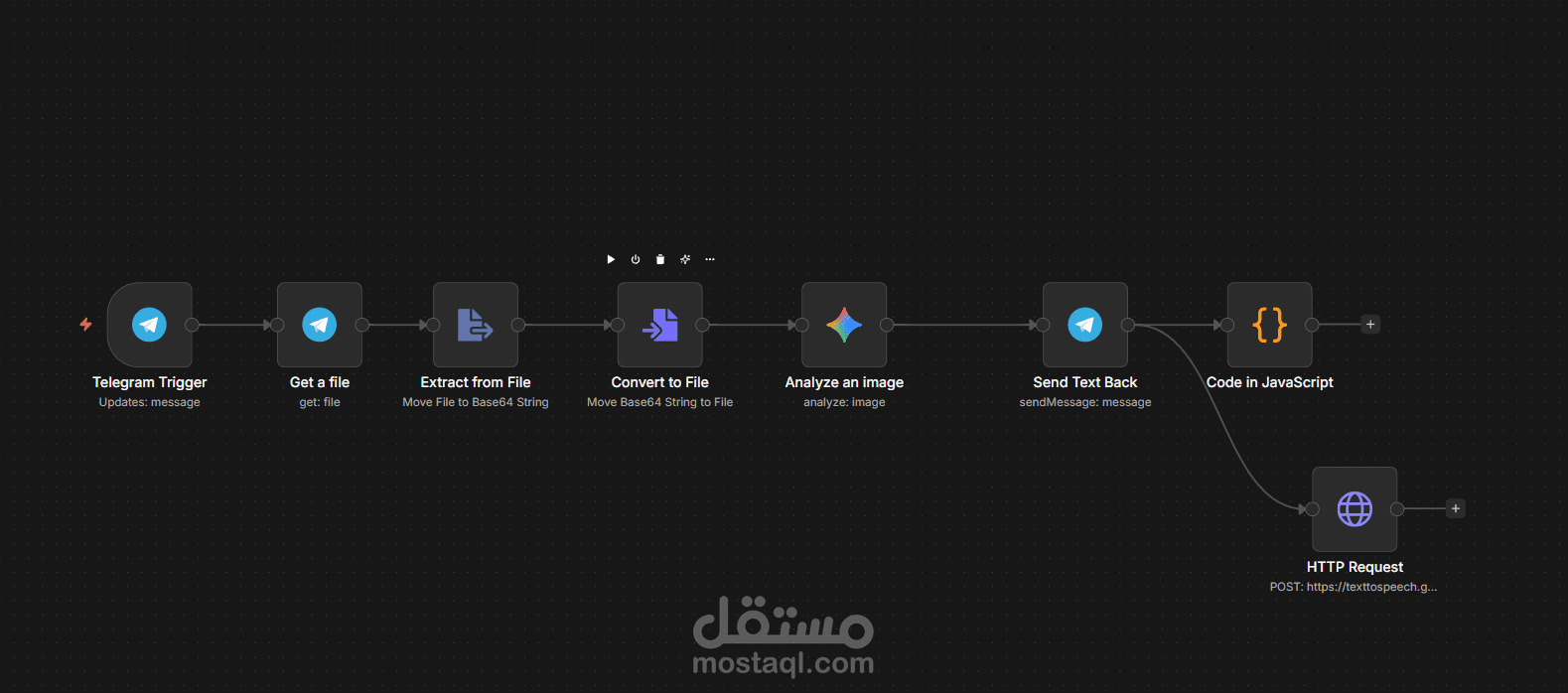
يبدأ المسار بـ Telegram Trigger لاستقبال صور صفحات الكتب.
يتم تمرير الصورة عبر سلسلة معالجة (Get a file -> Extract from File -> Convert to File) لضمان تحويل البيانات الثنائية (Binary Data) إلى صيغة قابلة للتحليل بواسطة نماذج الذكاء الاصطناعي.
2. التحليل البصري المتقدم (AI Vision Analysis):
يستخدم النظام موديل Gemini 2.5 Flash (عقدة Analyze an image) للقيام بعملية OCR ذكية. بخلاف الـ OCR التقليدي، يمتلك Gemini القدرة على فهم سياق النص، تصحيح الأخطاء الإملائية الناتجة عن جودة الطباعة، وتجاهل العناصر غير النصية في الصورة.
3. هندسة الصوت والذكاء اللغوي (Neural Text-to-Speech):
يتم تمرير النص المستخرج إلى عقدة JavaScript Code التي تعمل كـ "محرك إعداد" (Configuration Engine). يقوم الكود بتجهيز طلب (Request) لـ Google Text-to-Speech API.
يتم استخدام تقنية Wavenet (تحديداً ar-XA-Wavenet-B) لإنتاج صوت رجالي فخم وطبيعي جداً، بعيداً عن الأصوات الروبوتية التقليدية.
4. مرونة الأنظمة الهجينة (Hybrid System Flexibility):
نلاحظ في الكود وجود خيارين لمعالجة النصوص (OCR Space API و Google Gemini)، مما يعكس تصميماً مرناً يسمح بالتبديل بين المحركات لضمان أفضل دقة ممكنة في استخراج النصوص العربية.