Text to video
تفاصيل العمل
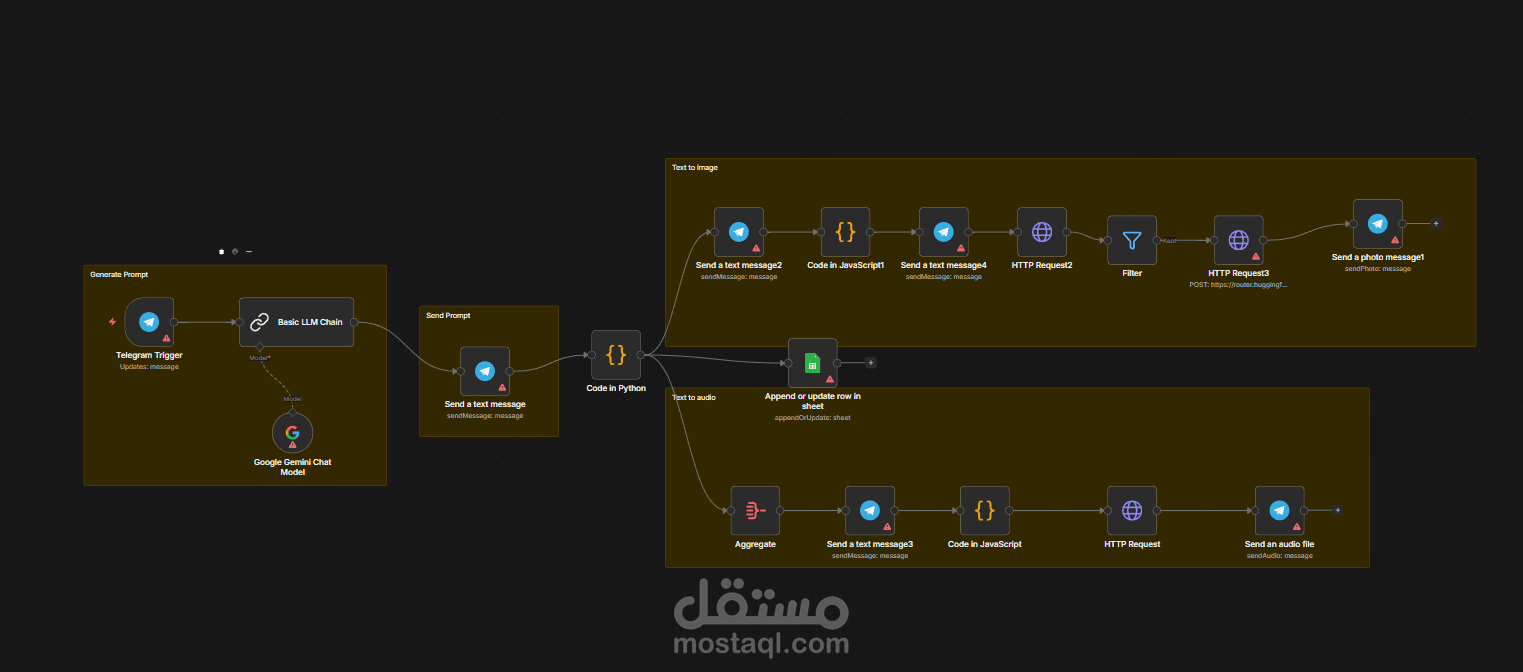
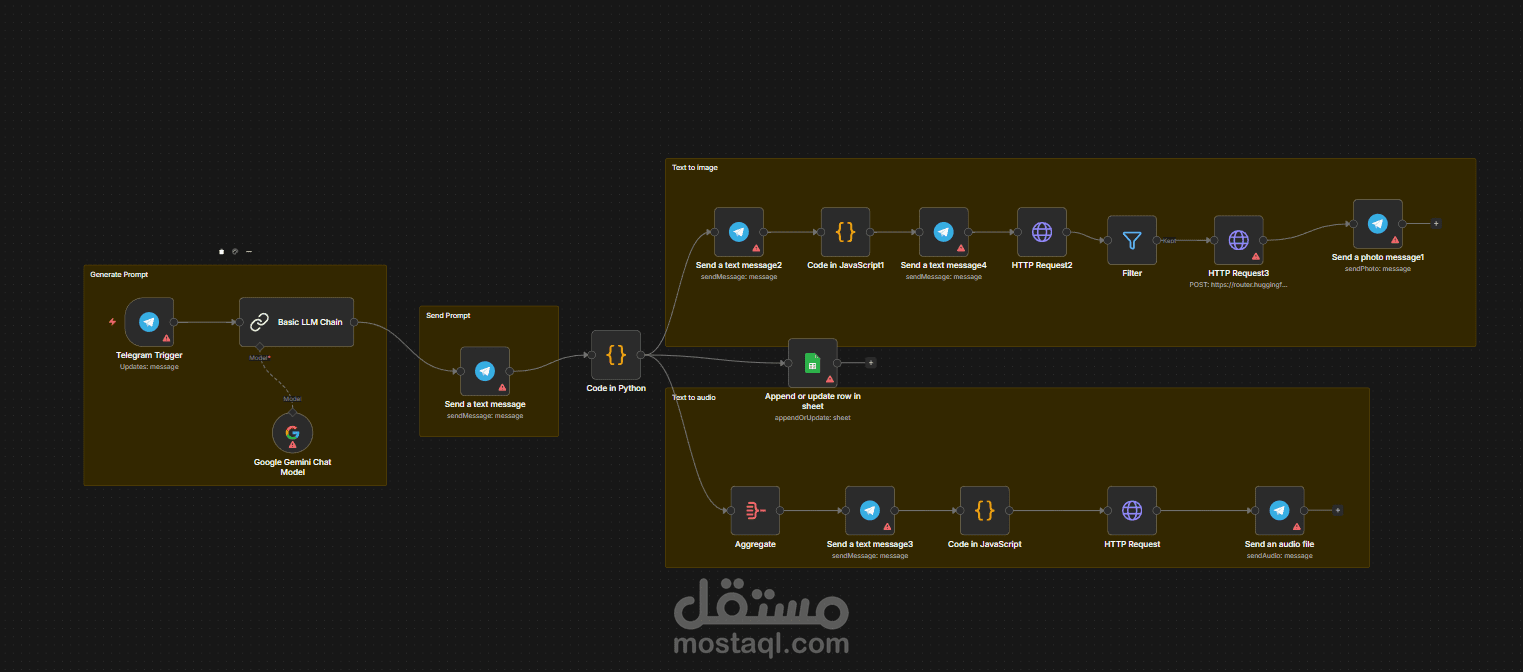
هذا المشروع هو عبارة عن "منظومة ذكية لإنتاج المحتوى الوثائقي القصير" (AI Video Content Creator Pipeline)، وهو يمثل مستوى متقدماً جداً في استخدام n8n للربط بين نماذج الذكاء الاصطناعي المختلفة.
إليك الوصف الاحترافي للمشروع بناءً على الكود (JSON) والصورة:
وصف المشروع: الأتمتة الشاملة لإنتاج الوسائط المتعددة (Text-to-Multimedia Pipeline)
هذا النظام مصمم لتحويل فكرة بسيطة مرسلة عبر تلغرام إلى "حزمة محتوى" كاملة تتضمن سكربت، صوراً مولدة بالذكاء الاصطناعي، وتعليقاً صوتياً بشرياً، مع أرشفة البيانات تلقائياً.
المكونات التقنية والابتكار في العمل:
1. هندسة الأوامر والذكاء النصي (Advanced Prompt Engineering):
يبدأ النظام بـ Telegram Trigger يستقبل موضوع الفيديو.
يتم تمرير الموضوع إلى Google Gemini Chat Model عبر Basic LLM Chain مع "برومبت" محكم لصياغة سكربت وثائقي (60 ثانية) باللغة العربية الفصحى، مقسم إلى مشاهد وبدون رموز تقنية، لضمان جاهزيته للمرحلة التالية.
2. وحدة المعالجة المنطقية (Hybrid Code Logic):
يستخدم النظام مزيجاً من Python و JavaScript داخل n8n لمعالجة النصوص:
Python Node: تقوم بفصل السكربت المرئي (Visuals) عن النص الصوتي (Audio Content) بدقة عالية.
JavaScript Nodes: تقوم بتقسيم النص إلى فقرات (Chunks) لا تتجاوز 40 كلمة لضمان جودة التوليد الصوتي وعدم حدوث انقطاع في الـ API.
3. التوليد البصري الذكي (AI Image Generation):
يتم إرسال وصف المشاهد إلى Google Translate API لتحويلها للإنجليزية، ثم تمريرها إلى موديل FLUX.1-schnell (عبر Hugging Face) لتوليد صور عالية الجودة تتوافق مع محتوى السكربت، وإرسالها فوراً للمستخدم.
4. الهندسة الصوتية (Text-to-Speech Engine):
يتصل النظام بـ VoiceRSS API لتحويل النص المنقح إلى ملفات صوتية (MP3) بجودة 16khz_128kbps_mono، مع تسمية الملفات تلقائياً حسب رقم المشهد لسهولة المونتاج.
5. إدارة البيانات والأرشفة (Data Governance):
يقوم النظام بتوثيق كل عملية إنتاج في Google Sheets، حيث يتم حفظ "البرومبت" المستخدم مع النص الصوتي المقابل له، مما يوفر قاعدة بيانات للرجوع إليها مستقبلاً.