wines type predictiion using python-ML-pandas-pycaret
تفاصيل العمل



عندى بيانات عن النبيذ الاحمر والنبيذ الابيض قمت بضمهما معا ولكن قبل الضم اضفت عمود type حتى نميز بينهما فيما بعد ولكن بطبيعة الحال قمت بالتعرف على كلا منهما باستخدام ادوات بايثون المختلفه مثل-df.head(),df.info,value_countsوغيرها ثم بعد ذلك قمت بتنظيف البيانات باستخدام methods -dropna,drop_duplicatesثم قمت بتحويل جميع الارقام الىfloatحتى اسهل واسرع المهمه علىpycaret
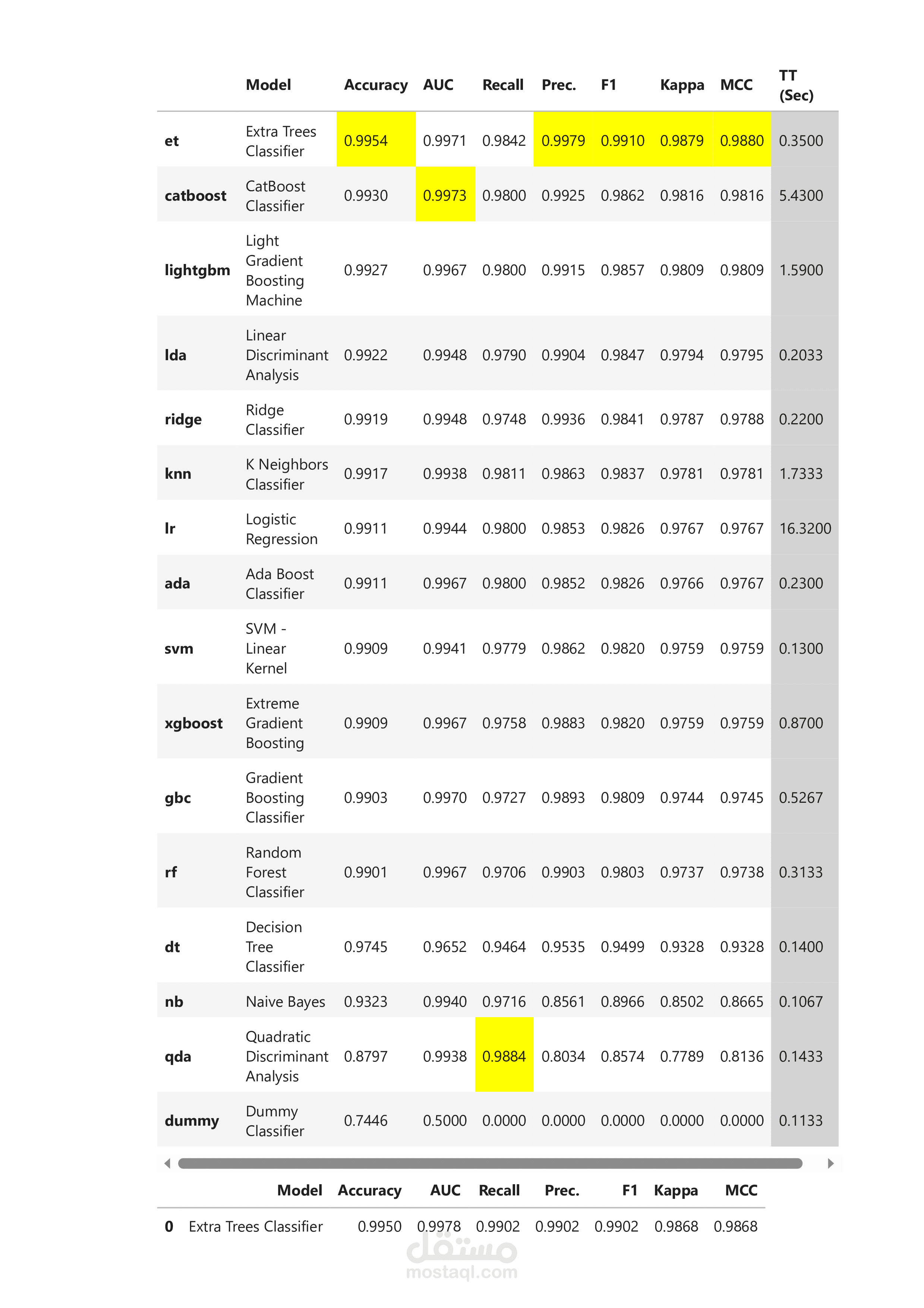
ثم قمت بتسطيب pycaret وخلال ذلك تم تحديد البيانات التى سيعمل عليها وهى wines والعمو الهدف type مع تقليل عدد fold لان default=10 وجهازى حالته سيئة كمااستخدمت True = normalize=True,transformation حتى يتم تحويل الارقام الكبيرة الى ارقام صغيره حول الصفر مع المحافظه على وزنها النسبى فتسهل على pycaret العمل ويكون اكثر دقة وماذكرته للتبسيط والهدف النهائى هو امكانية تحديد نوع النبيذ من خلال معرفة المواصفات المختلفة مثل نسبة الكحول وغيرها من المذكوره فى البيانات وذلك لاى بيانات جديده وسامحونى لانى مبعرفش احكى بس انا فاهم والحمد لله شغلى وبعرف اقوم بيه وكل شىء واضح فى صور وملفات العمل المرفقه.